12.1 时间序列基本概念¶
暑假里,小率在奶茶店帮忙整理销售记录。他发现同样是“销量”,按日期排起来以后,折线像有记忆:周末会高一点,天气热会高一点,连续几天促销后还会慢慢回落。
| 日期 | 最高气温 | 奶茶销量 |
|---|---|---|
| 7 月 1 日 | 31 | 118 |
| 7 月 2 日 | 32 | 126 |
| 7 月 3 日 | 33 | 137 |
| ... | ... | ... |
| 7 月 7 日 | 35 | 172 |
均哥,我以前会把销量当成一列普通数字。现在按日期一画,怎么感觉它们互相牵着走?
这就是时间序列最特别的地方:顺序本身带信息。今天不是随机抽出来的一天,它站在昨天和明天中间。
12.1.1 时间顺序让数据有了记忆¶
时间序列 (Time Series) 是按时间顺序记录的一串观测值,通常写成:
\[
y_1, y_2, \ldots, y_t, \ldots, y_T
\]
这里的下标 \(t\) 表示时间。普通横截面数据常问“这些人有什么差异”;时间序列常问“这个量怎样随时间变化,以及接下来会怎样”。
时间序列常见在哪里
每日销量、每小时客流、每月收入、每周体重、每天步数、气温、空气质量、网站访问量、股票价格,都可以按时间序列来分析。
12.1.2 一条折线通常混着三种东西¶
一条真实时间序列通常不是单一原因造成的。奶茶销量里至少混着三层信号:
- 趋势 (Trend):长期向上、向下或基本水平。
- 季节 (Seasonality):每周、每月、每年重复出现的周期波动。
- 残差 (Residual):趋势和季节解释不了的临时扰动。
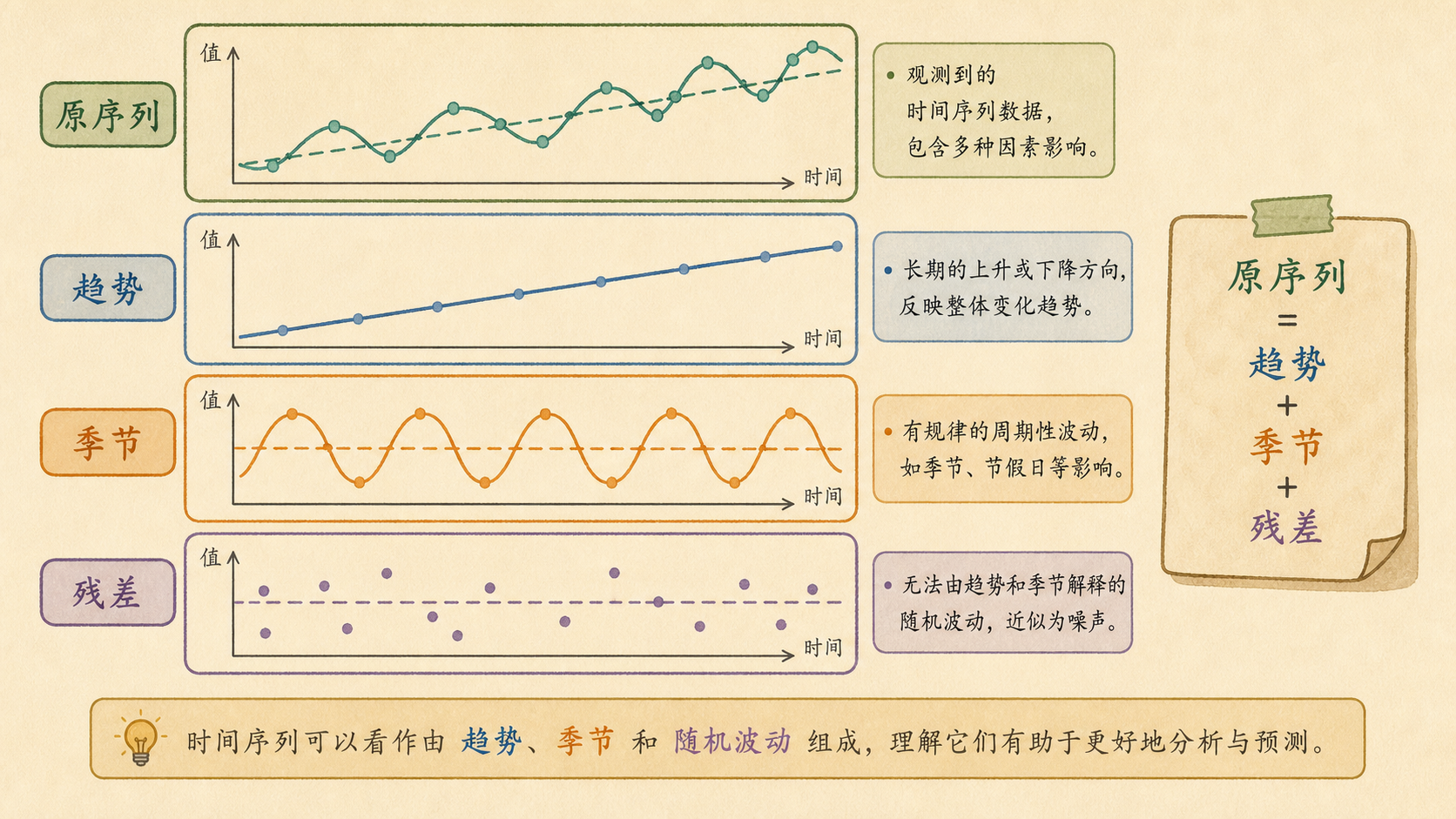
最常见的加法分解写作:
\[
\text{原序列} = \text{趋势} + \text{季节} + \text{残差}
\]
也就是:
\[
y_t = T_t + S_t + R_t
\]
如果销量越高,季节波动幅度也越大,可以先对数据取对数,再用加法思路处理。
12.1.3 自相关:今天和前几天有多像¶
时间序列里的“记忆”,常用自相关 (Autocorrelation) 描述。滞后 \(k\) 阶自相关,就是把序列和自己向后错开 \(k\) 个时间单位后计算相关性。
\[
\rho_k = \operatorname{Corr}(y_t, y_{t-k})
\]
如果奶茶销量的 \(\rho_7\) 很高,说明“今天”和“上周同一天”很像,周周期可能很强。
小率的问题
如果昨天销量高,今天销量也容易高,这是不是说明天气一定是原因?
不一定。自相关只说明时间上的相似,不直接说明因果。天气、促销、节假日都可能一起影响销量。
12.1.4 用 Python 先做三件小事¶
拿到时间序列后,先不要急着建复杂模型。先画图、算滚动均值、看自相关。
from pathlib import Path
import numpy as np
import pandas as pd
from statsmodels.tsa.stattools import acf
rng = np.random.default_rng(12)
dates = pd.date_range("2026-01-01", periods=72, freq="W")
trend = np.linspace(80, 130, len(dates))
season = 12 * np.sin(2 * np.pi * np.arange(len(dates)) / 4)
noise = rng.normal(0, 5, len(dates))
sales = pd.Series(trend + season + noise, index=dates, name="奶茶销量")
rolling = pd.DataFrame({
"销量": sales,
"4 周滚动均值": sales.rolling(4).mean(),
"4 周滚动标准差": sales.rolling(4).std(),
})
print(rolling.head(8).round(1))
print("前 8 阶自相关:", np.round(acf(sales, nlags=8), 2))
完整脚本见:
不要把时间打乱
时间序列建模时,训练集和测试集不能随机打散。预测未来时,模型只能看见过去,不能偷看未来。
小率的笔记本
时间序列 = 按时间顺序排列的数据。
第一眼先看折线图:有没有趋势、季节、异常点。
第二眼看自相关:今天和前几天、前几周是否相似。
做预测前,必须保留时间顺序。