7.2 标准正态检验¶
小率又拿来一张消保小组的数据:某品牌电池包装写着“平均续航 500 小时”。消保小组抽检了 64 节,样本均值是 488 小时。厂家过去有长期生产记录,续航标准差约为 \(\sigma=50\) 小时。
| 信息 | 数值 |
|---|---|
| 标称均值 \(\mu_0\) | 500 小时 |
| 样本量 \(n\) | 64 |
| 样本均值 \(\bar x\) | 488 小时 |
| 长期标准差 \(\sigma\) | 50 小时 |
12 小时的差距看起来不小,但统计检验不只看“差多少”,还要看“相对噪声差了多少”。

7.2.1 Z 检验把差距换成标准误¶
当总体标准差 \(\sigma\) 已知,或者样本量很大、标准误可以稳定估计时,可以使用 z 检验(z-test)。
单样本均值 z 检验的统计量是:
其中 \(\sigma/\sqrt n\) 是样本均值的标准误(Standard Error, SE)。
代入电池数据:
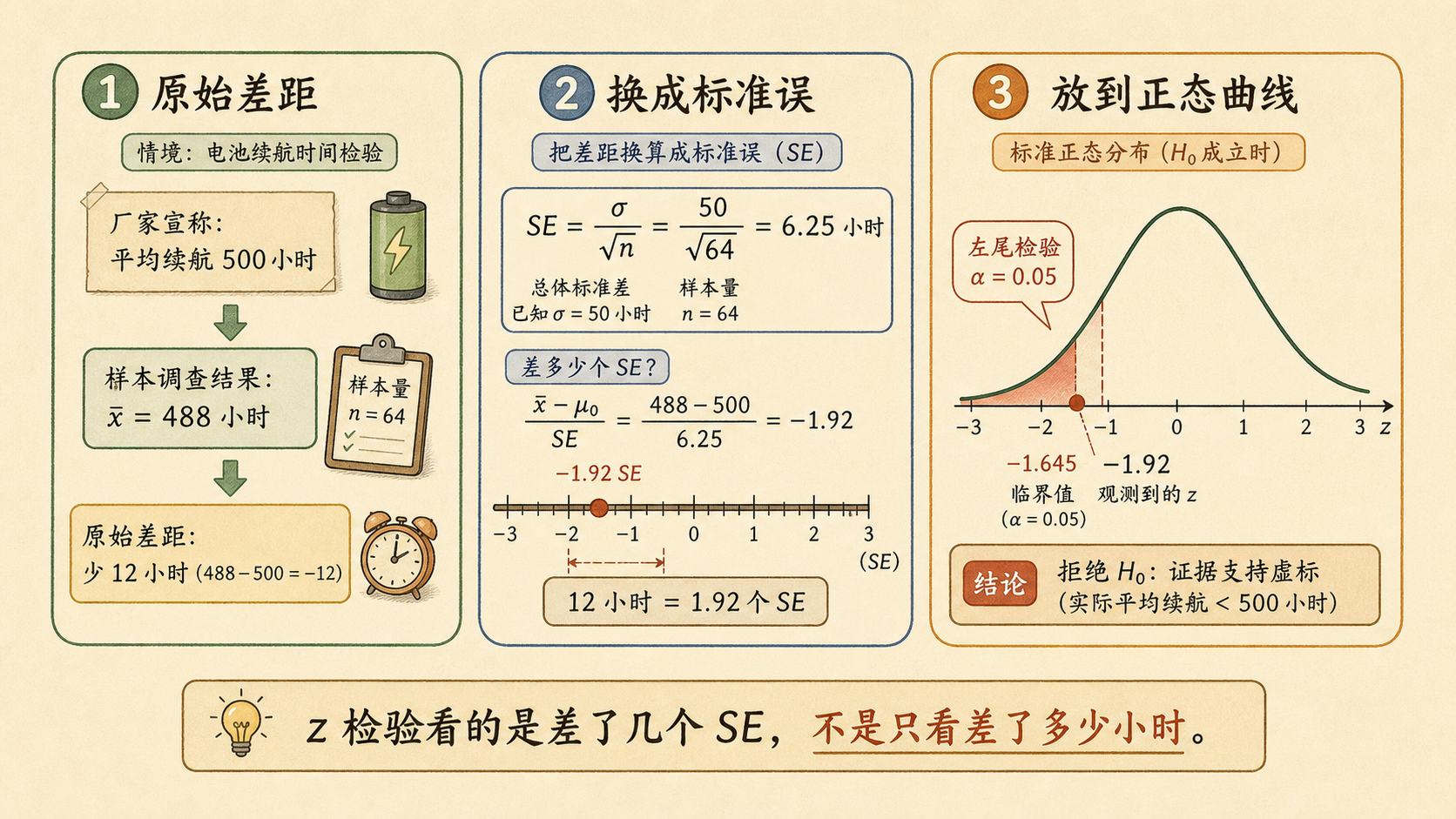
7.2.2 左侧检验判断是否虚标¶
如果消保小组只关心“是否低于标称”,就写:
这是左侧检验。显著性水平取 \(\alpha=0.05\) 时,左尾临界值约为:
观测到的 \(z=-1.92\) 比 \(-1.645\) 更靠左,落入拒绝域。因此拒绝 \(H_0\),数据支持“平均续航低于 500 小时”。
临界值和 p 值是两种说法
临界值法问“统计量是否落入拒绝域”;p 值法问“当前结果有多罕见”。两者在同一个 \(\alpha\) 下会给出一致决策。
7.2.3 z 检验家族不只均值¶
z 检验常见在三类场景里:
| 场景 | 统计量骨架 | 标准误 |
|---|---|---|
| 单样本均值,\(\sigma\) 已知 | \(\frac{\bar x-\mu_0}{SE}\) | \(\sigma/\sqrt n\) |
| 双样本均值差,\(\sigma_1,\sigma_2\) 已知 | \(\frac{(\bar x_1-\bar x_2)-\delta_0}{SE}\) | \(\sqrt{\sigma_1^2/n_1+\sigma_2^2/n_2}\) |
| 单样本比例,\(H_0:p=p_0\) | \(\frac{\hat p-p_0}{SE}\) | \(\sqrt{p_0(1-p_0)/n}\) |
比例检验里,标准误按 \(H_0\) 为真时的 \(p_0\) 来算。这一点很重要:检验统计量的参考世界永远来自 \(H_0\)。
7.2.4 单侧和双侧别混用¶
常用 \(\alpha=0.05\) 时:
| 备择假设 | 拒绝域 |
|---|---|
| \(H_1:\mu\ne\mu_0\) | $ |
| \(H_1:\mu>\mu_0\) | \(z>1.645\) |
| \(H_1:\mu<\mu_0\) | \(z<-1.645\) |
若电池问题在抽样前只关心“是否虚标”,左侧检验可以用;如果抽样前只是想查“和 500 小时是否不同”,则应该用双侧检验。
单侧检验不是事后优惠券
单侧检验必须在看结果前决定。看见样本均值偏低后再改成左侧,会人为放大证据。
7.2.5 Python 计算 z 和 p 值¶
from scipy import stats
import math
xbar = 488
mu0 = 500
sigma = 50
n = 64
z = (xbar - mu0) / (sigma / math.sqrt(n))
p_left = stats.norm.cdf(z)
p_two = 2 * stats.norm.cdf(-abs(z))
print(f"z = {z:.2f}")
print(f"左侧 p 值 = {p_left:.4f}")
print(f"双侧 p 值 = {p_two:.4f}")
完整脚本见:
7.2.6 什么时候 z 检验适合¶
z 检验适合:
- 总体标准差 \(\sigma\) 已知的工业质检、长期监控。
- 样本量很大的均值问题,此时 \(s\) 近似 \(\sigma\),z 和 t 差别很小。
- 大样本比例检验,例如支持率、点击率、转化率。
不适合:
- 小样本且 \(\sigma\) 未知的均值问题,应使用 t 检验。
- 强偏态、重尾、非独立样本。
- 样本比例接近 0 或 1 且样本量小的比例问题。
小率的笔记本
z 检验适合 \(\sigma\) 已知、大样本或比例问题。单样本均值统计量是 \(z=(\bar x-\mu_0)/(\sigma/\sqrt n)\)。z 值表示样本结果离 \(H_0\) 有几个标准误;单侧和双侧必须在看结果前定好。