2.9 数据可视化基础¶
小率把一页页描述统计结果摊在桌上:均值、中位数、标准差、IQR、偏度、峰度,数字都算出来了。
均哥却把计算器扣在桌上。

这些数字可信吗
如果几组数据的均值、方差、相关系数都差不多,它们的图形会不会也差不多?如果一张图看起来很有冲击力,它是不是就一定表达得更准确?
数据可视化(Data Visualization)不是把结果“装饰”得更漂亮,而是把数据的结构、异常、趋势和不确定性暴露出来。R Graph Gallery 和 Data to Viz 的核心思路也是如此:先看数据格式,再选图形类型;每一种图最好都能配可复现代码。
参考思路
本节借鉴 R Graph Gallery 的分类方式:分布、相关、排序、整体与部分、演化、地图、流向、网络,以及可视化注意事项。我们改写成 Python 版,并用更贴近初学者的数据场景来讲。
2.9.1 同样的统计量:安斯库姆四重奏¶
先看一个经典陷阱。下面四组数据的均值、方差、相关系数和线性回归结果非常接近,但图形结构完全不同。
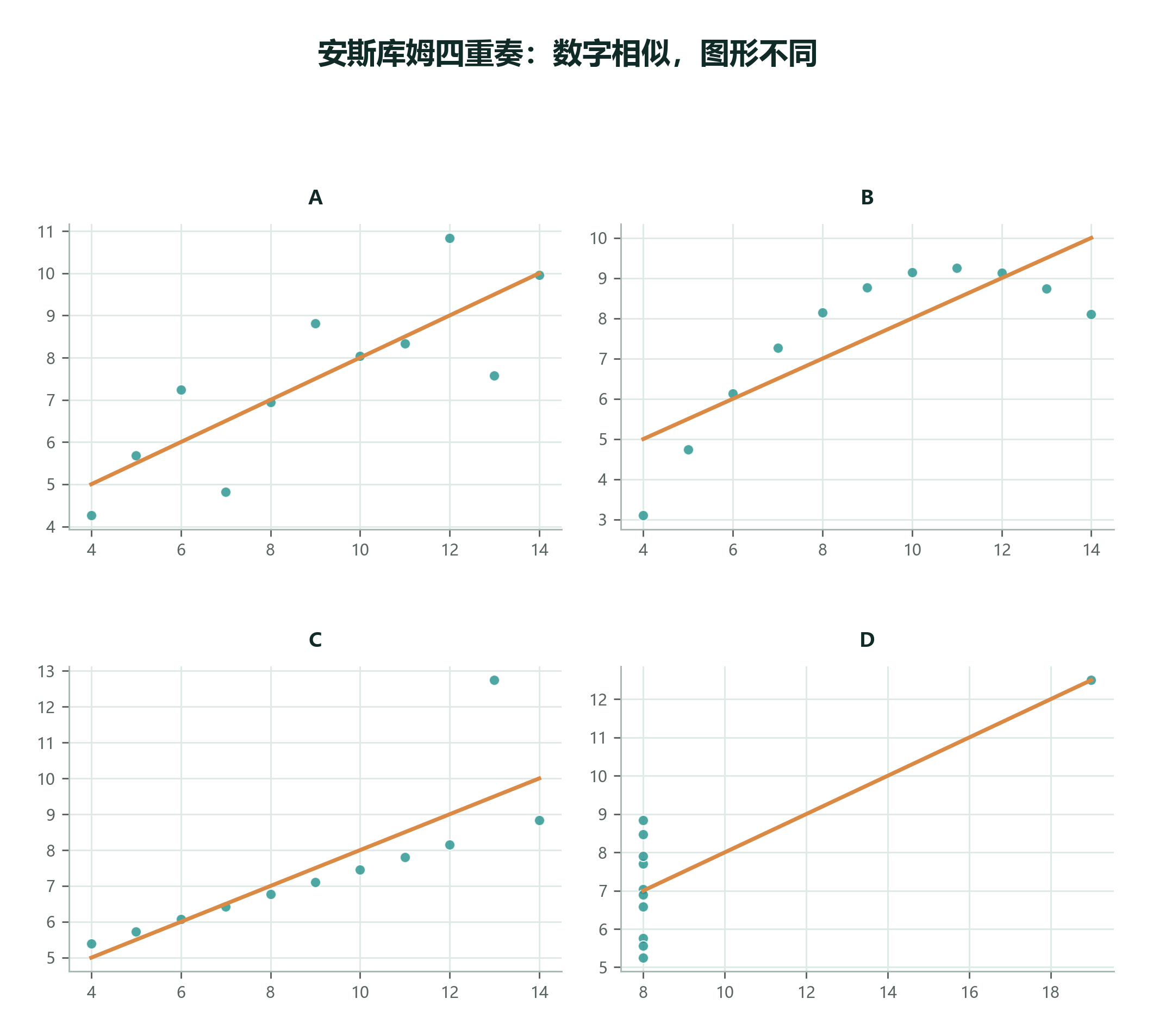
这不是反对计算,而是给计算安排正确位置。图形像体检里的影像检查,能先发现结构异常;统计量像化验指标,能把某些特征压缩成数值。只看化验不看片子,可能错过形状;只看片子不看化验,也可能缺少精确比较。
import numpy as np
import matplotlib.pyplot as plt
x = np.array([10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5], dtype=float)
y1 = np.array([8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68])
plt.scatter(x, y1)
coef = np.polyfit(x, y1, 1)
xx = np.linspace(x.min(), x.max(), 100)
plt.plot(xx, coef[0] * xx + coef[1])
plt.xlabel("X")
plt.ylabel("Y")
plt.show()
2.9.2 图形索引:先问数据类型¶
拿到数据时,不要先问“画什么最好看”,而要先问:
- 我有几个变量?
- 变量是数值、分类、时间、空间,还是网络关系?
- 我想看分布、排序、关系、变化,还是整体与部分?
| 数据类型 | 常用图形 | 主要回答 |
|---|---|---|
| 一个数值变量 | 直方图、密度图、箱线图、小提琴图、ECDF | 分布形状、中心、离散、偏态、异常值 |
| 一个分类变量 | 条形图、棒棒糖图、排序点图、排名表 | 哪类最多、比例如何、排序如何 |
| 数值 + 分类 | 分组箱线图、小提琴图、蜂群图、山峦图 | 不同组的分布是否不同 |
| 数值 + 数值 | 散点图、气泡图、二维密度、hexbin、相关热图 | 是否有关系、趋势、离群点、非线性 |
| 时间 + 数值 | 折线图、面积图、堆叠面积图、日历热图 | 趋势、季节性、突变 |
| 整体与部分 | 堆叠条形图、treemap、waffle、环图 | 构成比例 |
| 空间、网络、流向 | 地图、气泡地图、网络图、桑基图 | 位置、连接、流向 |
| 多维、文本、层级 | Radar、Wordcloud、Parallel、Circular Barplot、Circular Packing、Dendrogram | 看多指标轮廓、词频、层级聚类 |

图形选择口诀
一个变量看分布,两个数值看关系,分类变量看频数,分组数据看差异,时间数据看变化,整体部分看构成,网络流向看连接。
如果你一开始不知道选什么图,可以先用最朴素的图:数值变量画直方图或箱线图,分类变量画条形图,两个数值变量画散点图,时间变量画折线图。朴素图不丢人,很多专业报告最依赖的也正是这些图。
2.9.3 一个数值变量:直方图、密度图、箱线图、小提琴图、ECDF¶
数据集设定: 小率记录了 195 位同学每天的手机使用时长,单位是分钟。大部分人在 20 到 30 分钟附近,但也有一小撮人明显更久。
这类数据只有一个数值变量,核心任务是看分布。
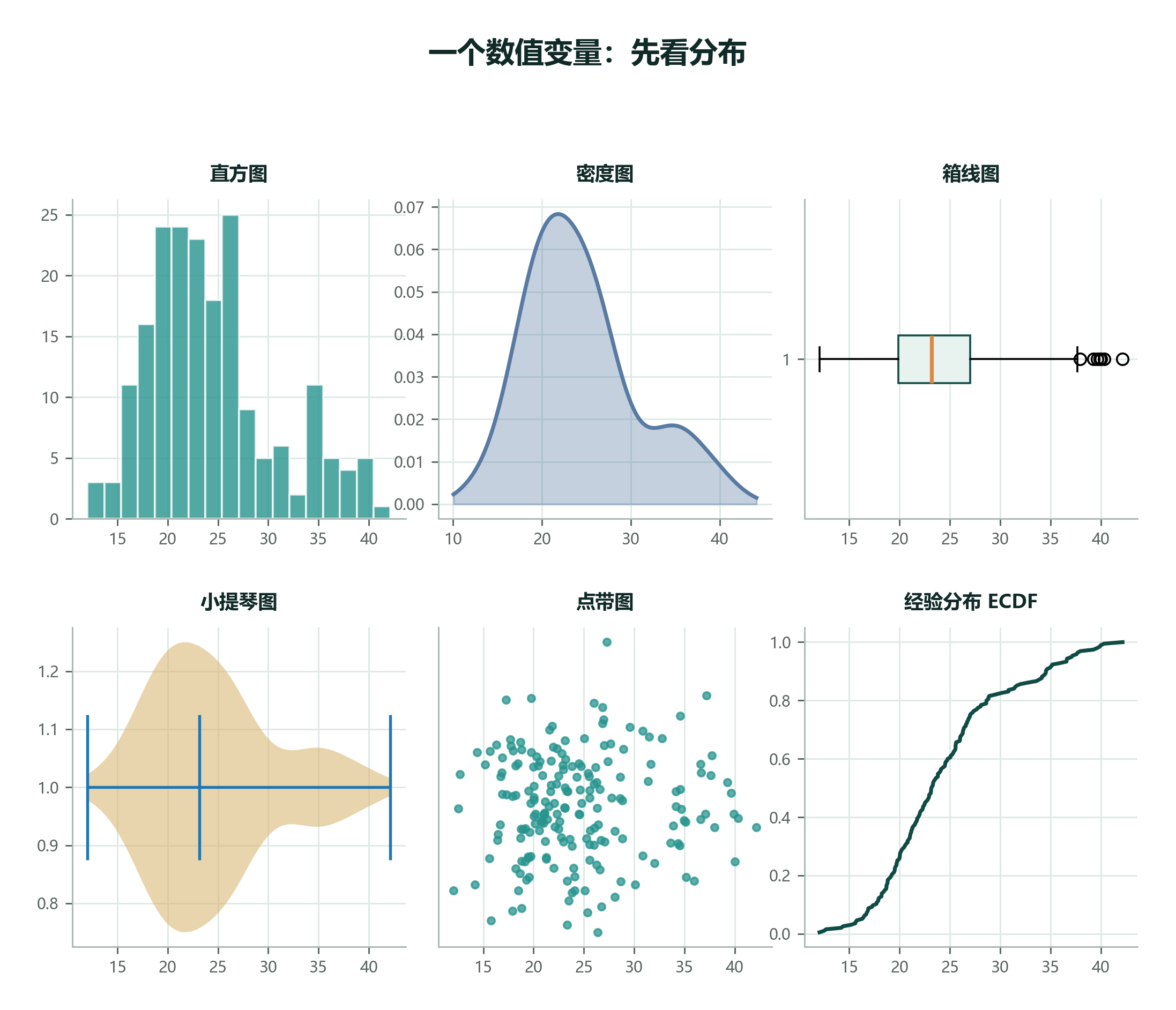
| 图形 | 适合看什么 | 注意事项 |
|---|---|---|
| 直方图 Histogram | 分布形状、峰、偏态 | 组距会影响视觉判断 |
| 密度图 Density Plot | 平滑分布形状 | 样本太少时容易过度平滑 |
| 箱线图 Boxplot | 中位数、IQR、异常值 | 不显示分布细节 |
| 小提琴图 Violin Plot | 分布形状 + 中心 | 需要足够样本量 |
| 点带图 Strip Plot | 每个观测值 | 点太多会重叠 |
| ECDF | 小于某个值的比例 | 初学时读起来稍慢 |
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(29)
minutes = np.r_[rng.normal(22, 4.2, 160), rng.normal(35, 3.2, 35)]
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
axes[0].hist(minutes, bins=18)
axes[0].set_title("直方图")
axes[1].boxplot(minutes, vert=False)
axes[1].set_title("箱线图")
xs = np.sort(minutes)
ys = np.arange(1, len(xs) + 1) / len(xs)
axes[2].plot(xs, ys)
axes[2].set_title("ECDF")
plt.tight_layout()
plt.show()
一个数值变量最常见的错误,是直接报均值。更稳妥的顺序是:
- 先画直方图,看是否对称、偏态、双峰。
- 再画箱线图,看中位数、IQR 和异常点。
- 最后决定报告均值和标准差,还是中位数和 IQR。
这样做看起来慢,其实能避免很多后面返工。
2.9.4 一个分类变量:条形图、棒棒糖图、排序点图¶
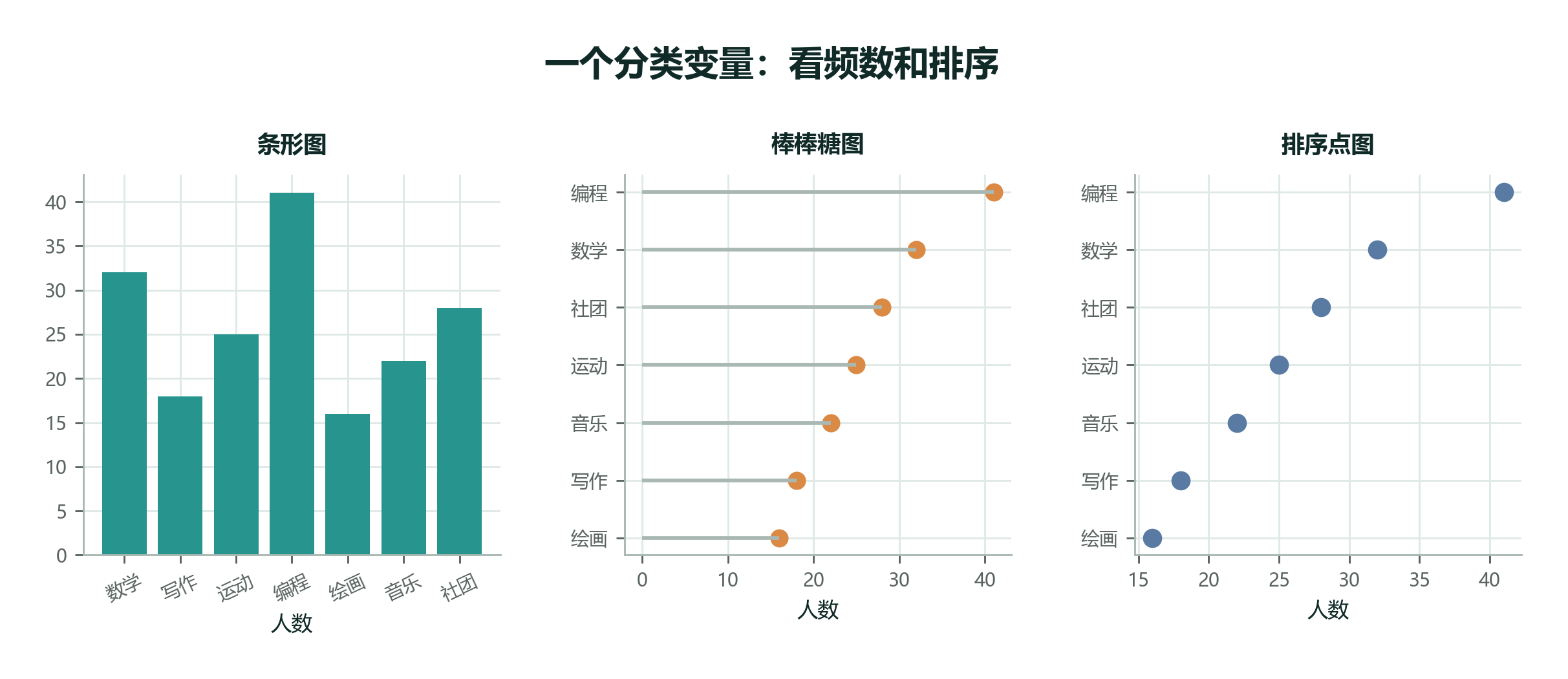
数据集设定: 班级问卷统计“最想参加的兴趣活动”,变量是活动类型,取值是数学、写作、运动、编程等类别。
一个分类变量不要用折线图,也不需要硬画饼图。大多数时候,条形图已经很清楚;如果类别很多,排序点图或棒棒糖图更利于比较。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
"活动": ["数学", "写作", "运动", "编程", "绘画", "音乐", "社团"],
"人数": [32, 18, 25, 41, 16, 22, 28],
}).sort_values("人数")
plt.hlines(df["活动"], 0, df["人数"])
plt.scatter(df["人数"], df["活动"])
plt.xlabel("人数")
plt.title("兴趣活动报名人数")
plt.show()
需要注意
分类变量没有天然顺序时,不要随手按录入顺序画图。按频数排序、按业务顺序排序,或按时间顺序排序,都比随机顺序更容易读。
分类图最重要的是让比较容易。类别很多时,横着画常常比竖着画更清楚;类别名称很长时,横向条形图比饼图更容易读;类别之间差异不大时,排序点图比花哨配色更有帮助。
2.9.5 数值 + 分类:分组箱线图、小提琴图、Beeswarm、Ridgeline¶
数据集设定: 四个班做同一次小测,每个学生都有一个分数。我们不只想知道哪个班平均分高,还想看每个班内部是否分散、有没有异常值。
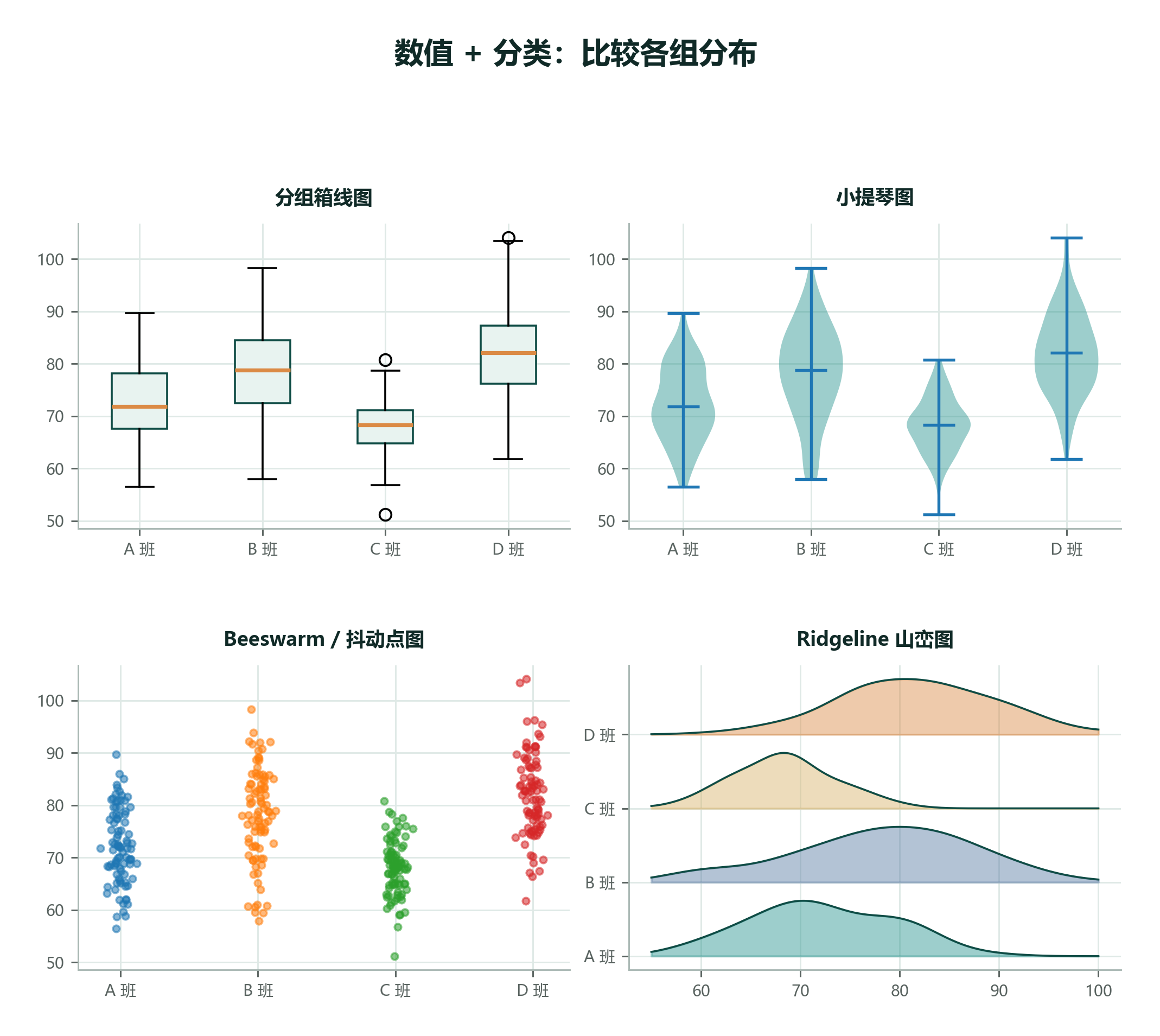
| 图形 | 优点 | 适合场景 |
|---|---|---|
| 分组箱线图 | 简洁,突出中位数和 IQR | 组数较多、报告空间有限 |
| 小提琴图 | 展示分布形状 | 每组样本量较大 |
| 蜂群图 Beeswarm / 抖动点图 | 保留每个观测值 | 样本量中等 |
| 山峦图 Ridgeline | 多组分布纵向比较 | 组很多且分布形状重要 |
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(30)
groups = ["A 班", "B 班", "C 班", "D 班"]
scores = [rng.normal(mu, sd, 90) for mu, sd in [(72, 7), (78, 9), (69, 6), (82, 8)]]
plt.boxplot(scores, tick_labels=groups)
plt.ylabel("分数")
plt.title("不同班级的小测成绩")
plt.show()
分组图最适合问:“不同组只是平均值不同,还是整个分布都不同?”两个班平均分接近,但一个班分数很集中,另一个班两极分化,这对教学安排的意义完全不同。分组箱线图能把这种差异显示出来。
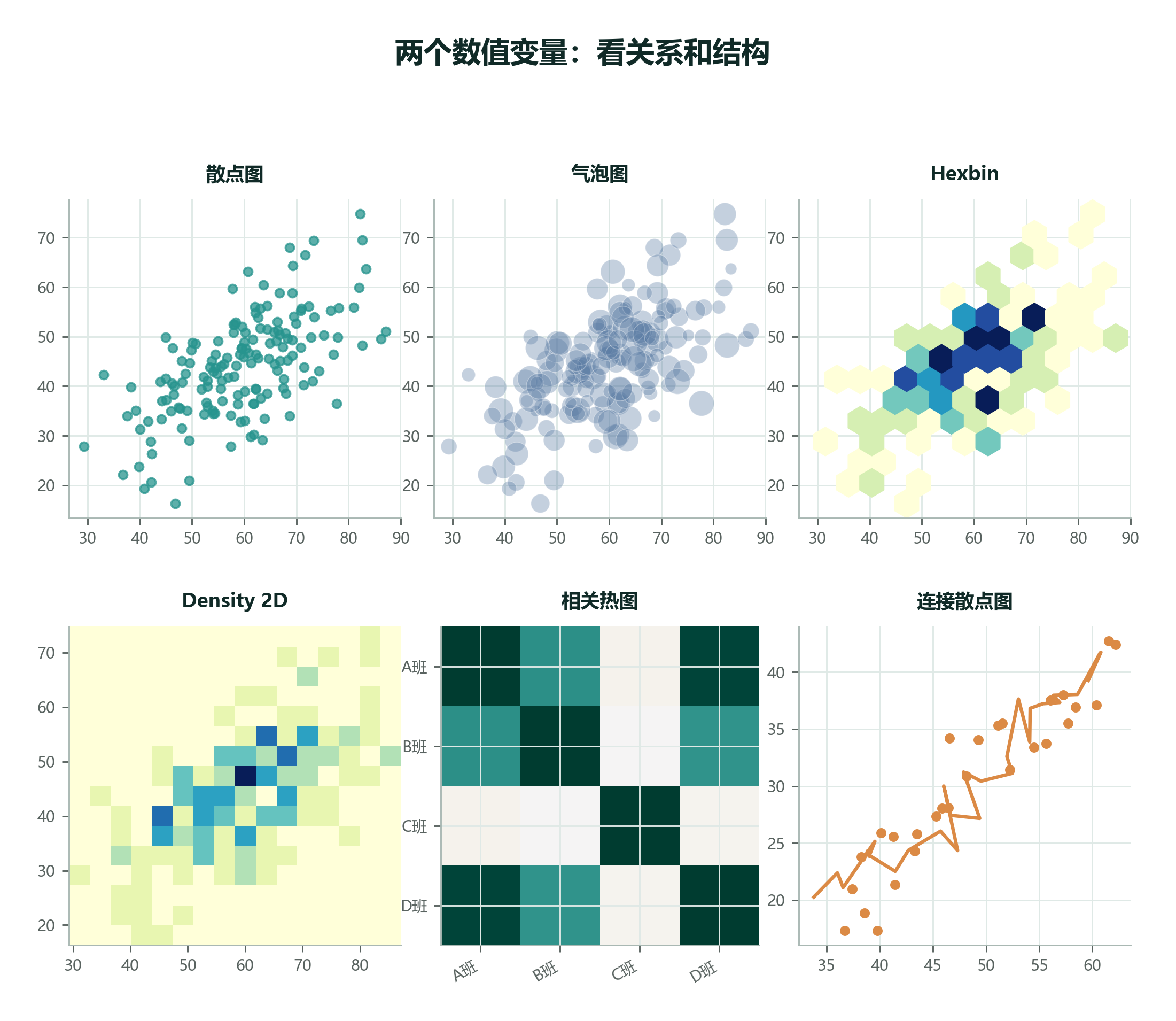
2.9.6 数值 + 数值:散点图、气泡图、Density 2D、Hexbin、相关热图¶
数据集设定: 小率调查同学的“上周学习时间”和“测验分数”。两个变量都是数值变量,我们想看它们有没有关系。
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(31)
study_hours = rng.normal(60, 12, 160)
score = 0.58 * study_hours + rng.normal(10, 8, 160)
plt.scatter(study_hours, score, alpha=0.7)
plt.xlabel("上周学习时间")
plt.ylabel("测验分数")
plt.title("学习时间与测验分数")
plt.show()
不要把相关直接读成因果
散点图能提示关系,但不能自动证明因果。学习时间和分数相关,可能有努力程度、基础水平、课程难度等其他变量共同影响。
散点图至少要看四件事:方向、强弱、形状和离群点。方向是整体上升还是下降;强弱是点云是否贴近一条带状区域;形状是直线、曲线还是分段;离群点是有没有个别样本明显偏离主体。
如果点太多挤成一团,不要硬画密密麻麻的散点。可以加透明度、用 hexbin、二维密度图,或先抽样展示。图的目标是让结构显现,不是把所有点堆到看不清。
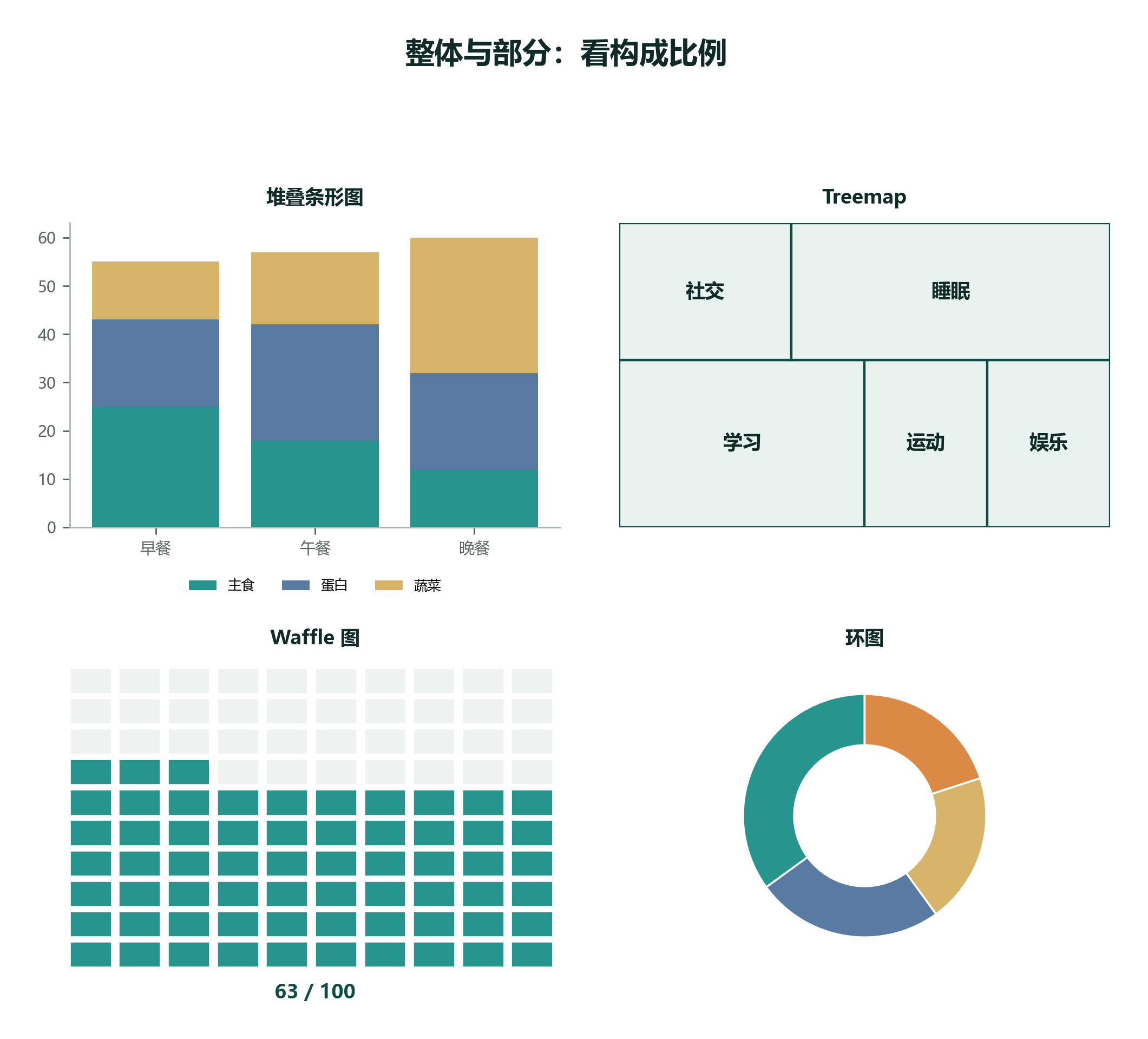
2.9.7 整体与部分:堆叠条形图、Treemap、Waffle、环图¶
数据集设定: 一天 24 小时怎么分配?学习、睡眠、运动、娱乐、社交分别占多少?这类问题关心“部分如何组成整体”。
import matplotlib.pyplot as plt
labels = ["学习", "睡眠", "运动", "娱乐", "社交"]
hours = [7, 8, 2, 4, 3]
plt.pie(hours, labels=labels, startangle=90)
plt.title("一天时间构成")
plt.show()
饼图要克制
饼图和环图适合类别很少、只需要粗略看比例的场景。如果要比较多个类别之间的细小差异,条形图通常更准确。
构成图最容易制造错觉。多个饼图并排时,人眼很难准确比较扇形面积;类别太多时,颜色会变成负担;如果各部分之间差异很小,条形图或表格往往更诚实。
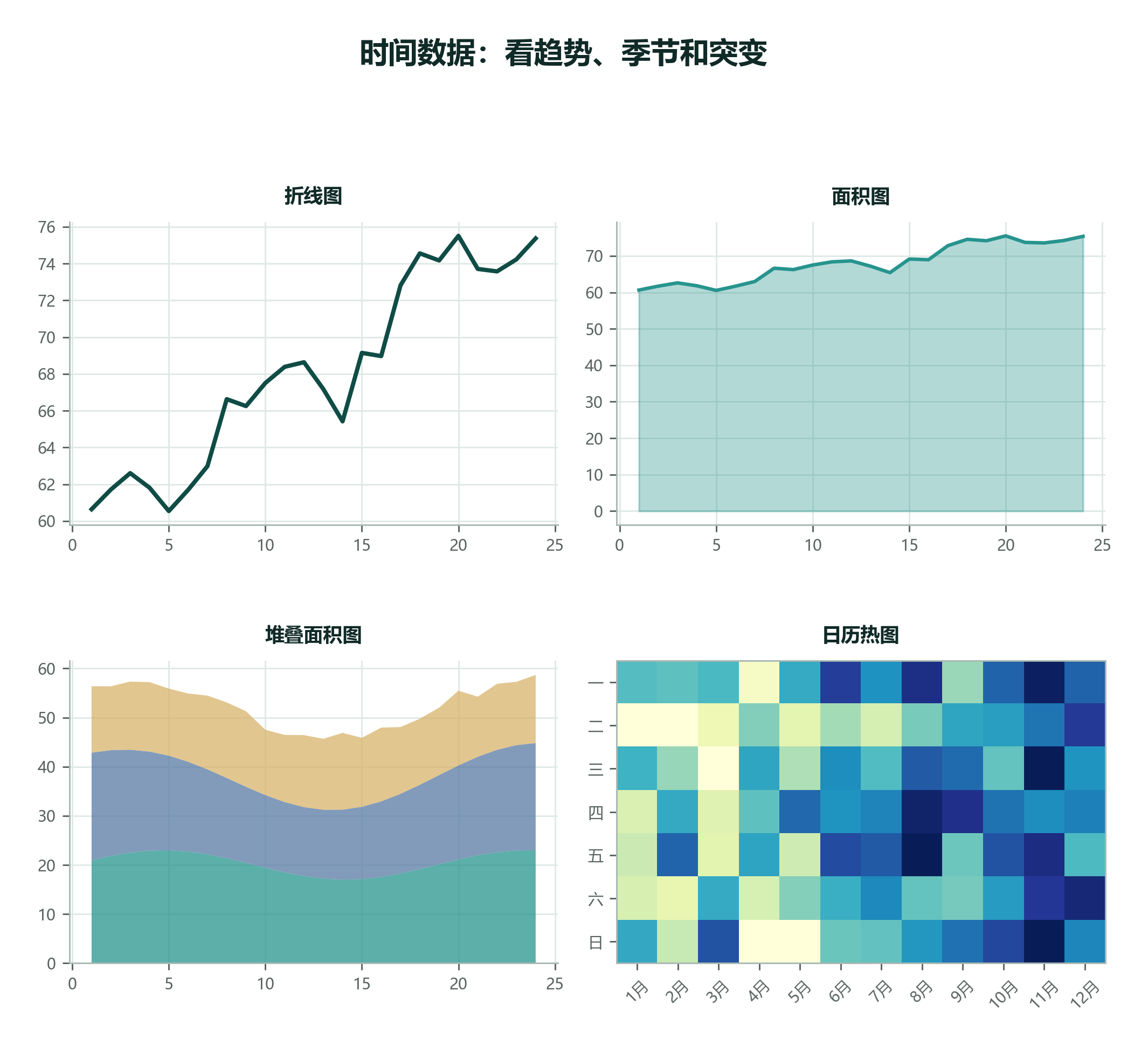
2.9.8 时间 + 数值:折线图、面积图、堆叠面积图、日历热图¶
数据集设定: 小率连续 24 周记录每周阅读页数。时间变量有顺序,不能打乱。我们关心趋势、季节性、突变和累计变化。
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(32)
week = np.arange(1, 25)
pages = 60 + np.cumsum(rng.normal(0.6, 1.6, len(week)))
plt.plot(week, pages, marker="o")
plt.xlabel("周")
plt.ylabel("阅读页数")
plt.title("每周阅读页数变化")
plt.show()
时间图最重要的规则是:不要打乱顺序。哪怕某周数值最大,也不能为了排序把它挪到最前面。时间数据关心的是过程:什么时候上升,什么时候下降,什么时候突然改变,是否有周期。
时间图先看变化点
读折线图时,先找明显拐点、峰值、低谷和异常跳变,再问这些变化是否对应现实事件。
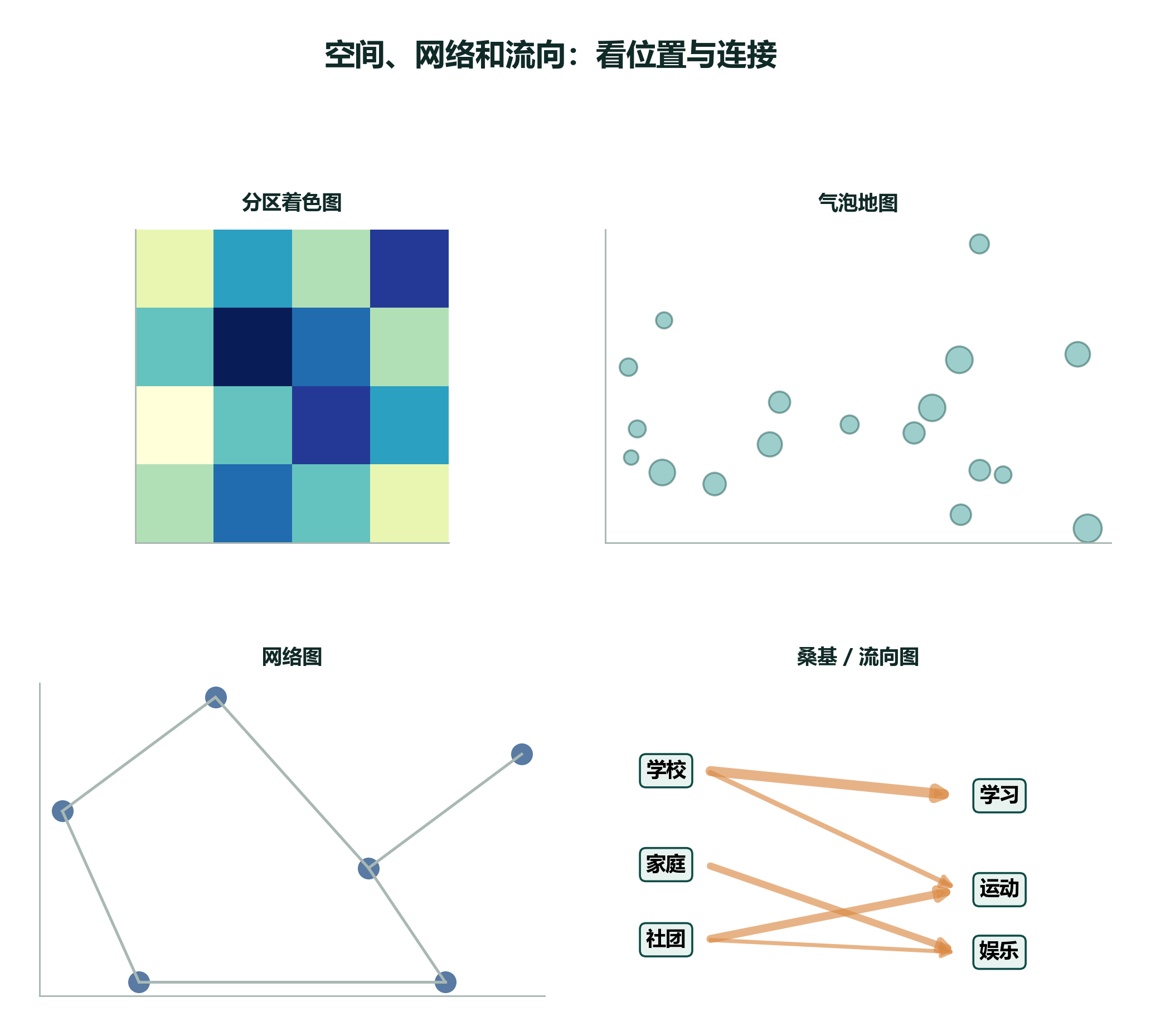
2.9.9 空间、网络和流向:地图、网络图、桑基图¶
数据集设定: 如果数据包含位置、区域、连接、来源和去向,就不再只是普通的表格。比如“不同城区报名人数”“社团成员之间的合作关系”“学生一天时间从哪里流向哪里”。
import numpy as np
import matplotlib.pyplot as plt
rng = np.random.default_rng(33)
x = rng.uniform(0, 10, 18)
y = rng.uniform(0, 8, 18)
size = rng.uniform(40, 260, 18)
plt.scatter(x, y, s=size, alpha=0.5)
plt.title("简化气泡地图")
plt.xticks([])
plt.yticks([])
plt.show()
入门时先掌握核心图
地图、网络图和桑基图很有用,但它们对数据结构要求更高。初学阶段先把直方图、箱线图、条形图、散点图、折线图画扎实。
2.9.10 多维、文本与层级:Radar、Wordcloud、Parallel、Circular、Dendrogram¶
有些图不属于描述统计入门的第一批核心图,但真实项目中经常会遇到。它们通常要求数据结构更明确:多指标评分、词频文本、层级关系、聚类结构或环形布局。
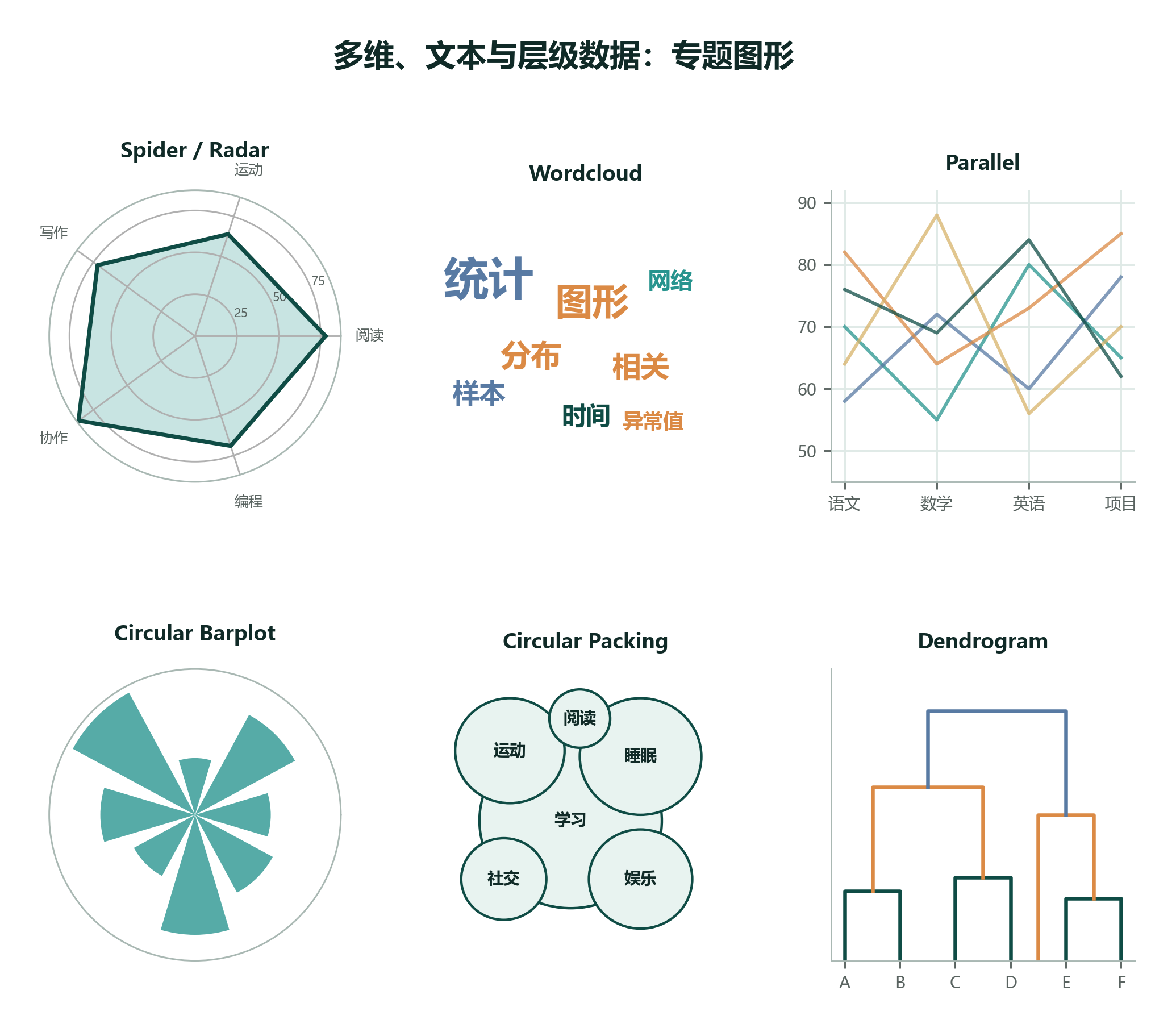
| 图形 | 数据结构 | 常见用途 |
|---|---|---|
| Spider / Radar | 一个对象的多项指标 | 能力画像、产品维度评分 |
| Wordcloud | 文本词频 | 快速展示关键词 |
| Parallel Coordinates | 多个数值变量 | 多维样本模式和异常 |
| Circular Barplot | 分类 + 数值 | 环形排序展示 |
| Circular Packing | 层级 + 数值 | 层级构成和大小 |
| Dendrogram | 样本间距离 | 聚类树、层级关系 |
专题图不要为了炫技而用
这些图信息密度高,但阅读成本也高。教学、报告和论文中要先确认读者能否读懂;如果普通条形图、散点图、箱线图已经能回答问题,就不必强行换成复杂图。
2.9.11 坐标轴与比例尺:坏图会制造错觉¶
同一份数据,换一种坐标轴或比例尺,读者的感受可能完全不同。
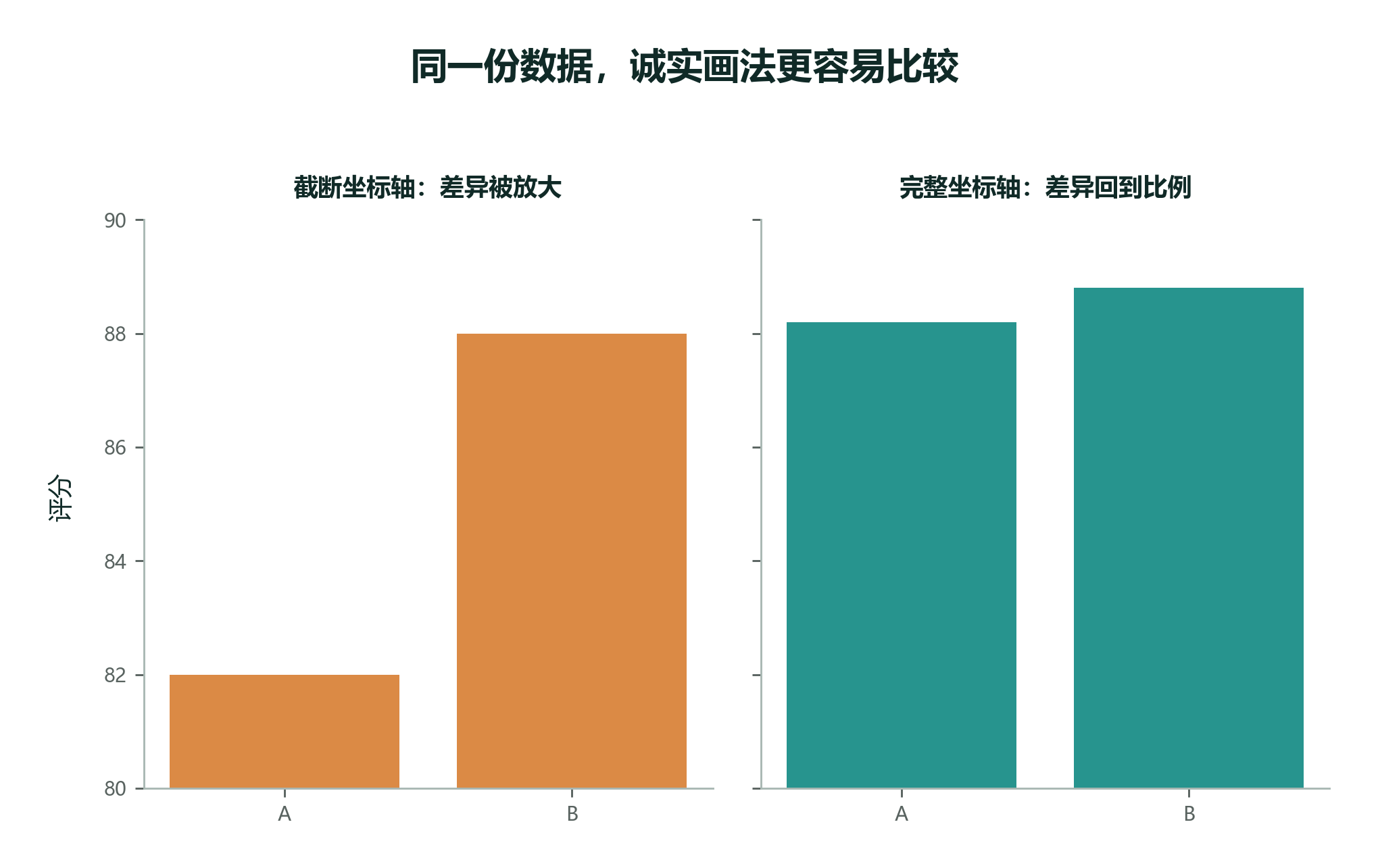
需要注意
图形设计不是“怎么更好看”,而是“怎么更诚实”。坐标轴、排序、颜色、比例尺都要服务于清楚表达数据,而不是制造视觉冲击。
常见坏图包括:
- 截断纵轴,让很小的差异看起来像翻倍。
- 用 3D 饼图,让面积和角度都难以比较。
- 类别顺序混乱,让读者来回找。
- 颜色过多,重要信息反而淹没。
- 不写单位,让读者不知道数值代表什么。
好图不一定复杂,但一定要让读者知道:比较对象是谁、单位是什么、差异有多大、结论是否被夸张。
2.9.12 小率的画图检查清单¶
画图前问九个问题:
- 变量是数值、分类、时间、空间,还是网络关系?
- 我是在看一个变量、比较多个组,还是看两个变量的关系?
- 样本量够不够支撑密度图、小提琴图、山峦图这类形状图?
- 类别是否需要排序?
- 坐标轴是否从合理位置开始,单位是否清楚?
- 颜色是否只强调真正需要强调的信息?
- 点是否重叠?是否需要透明度、抖动、hexbin 或二维密度?
- 是否暴露了异常值、分组结构或非线性模式?
- 读者能不能只看标题、坐标轴和图例就理解这张图?
报告里的最低要求
任何描述统计报告都至少说明样本量、变量单位、数据来源,并给出一张能看清分布形状的图。图形不是最后的装饰,而是分析过程的一部分。
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/09_data_visualization.py,可以复现本节主要图形类型和可视化误导示例。
小率的笔记本
- 先画图,再算数;图形能暴露汇总统计量隐藏的结构。
- 图形选择取决于数据类型和分析问题。
- 一个数值变量看分布,一个分类变量看频数,数值加分类看组间差异,两个数值变量看关系。
- 时间数据不要打乱顺序;整体与部分要看比例;空间、网络和流向要先确认数据结构。
- 坐标轴、颜色、排序和比例尺都可能影响读者判断。
- 好图不是更花哨,而是更诚实、更容易比较。
- 不知道选什么图时,先用直方图、箱线图、条形图、散点图和折线图这些基础图。