8.5 逻辑回归¶
本节学习目标
- Y 是 0/1 时为何不能用 OLS
- 掌握 logit 链接 ** 与 ** 逻辑回归模型
- 解读 几率比 (Odds Ratio) 与系数
- 用 MLE 拟合; 评估: 准确率/AUC/混淆矩阵
8.5.1 直接 OLS 为什么会预测出 220%¶
某高校教务想做一个『学生通过期末考试的概率预测』:手里有每个学生的 每周自习时长 ,想用它估计『这个人能不能过』。 第一反应:上 OLS——把 \(Y \in \{0, 1\}\) 当连续值回归学习时长。 跑出来斜率 0.12,截距 -0.2,模型告诉你『学 10 小时的同学通过概率 1.0』,看起来挺好。
可第二天经理盯着报表问:『学 20 小时的预测概率 = 2.2,啥意思?这家伙能 220% 通过吗?』
这三条具体是:预测值会冲出 \([0, 1]\)(如刚才的 2.2);方差 \(\text{Var}(Y) = p(1-p)\) 随 \(X\) 变化(异方差严重);二元 \(Y\) 的残差也根本不服从正态。 三条同时违反,OLS 的 SE/p/CI 全部失真。
故事的核心问题:怎么让 \(X\) 的线性组合输出一个合法的 概率 ?
8.5.2 S 形曲线与挤压函数¶
学习时长从 0 一路涨到无穷大,通过的概率应该从接近 0 平滑爬到接近 1,并在某个『临界时长』附近最敏感。 这条曲线的形状大家都熟悉——S 形 :两端被压平、中间陡升。
数学家给它装了一个开关:先让 \(X\) 走线性组合 \(z = \beta_0 + \beta_1 X\),可以是任何实数;再把 \(z\) 喂进一个 挤压函数 ** ,把它压到 \((0, 1)\)。 这个挤压函数就是 ** logistic / sigmoid :
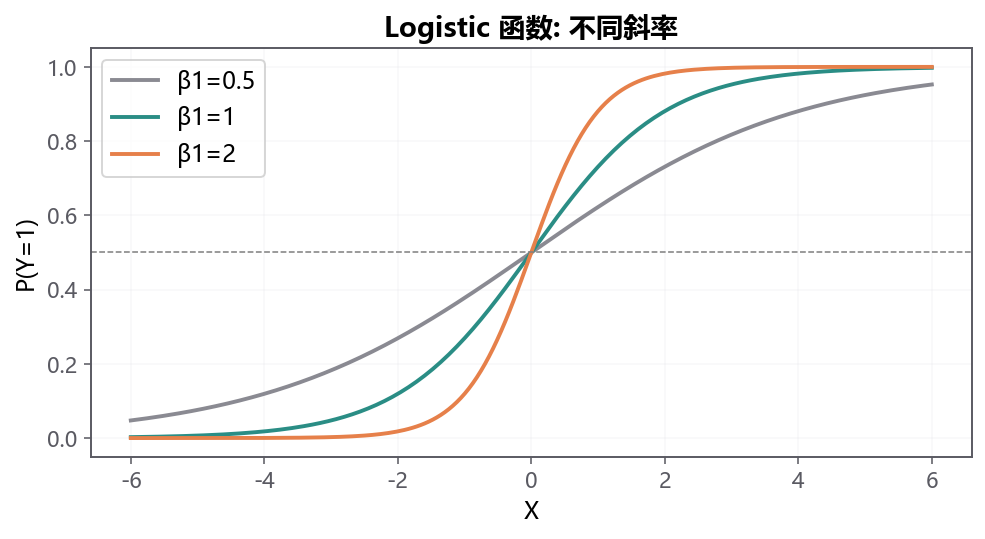
直觉抓两点:(1) 决策边界 ** 在 \(z = 0\)(即 \(p = 0.5\))的位置,由 \(\beta_0\) 平移;(2) ** 斜率 由 \(\beta_1\) 控制,\(\beta_1\) 越大曲线越陡,分类越果断。
8.5.3 logit 链接与几率比 OR¶
把 sigmoid 写成公式:
把式子倒过来——这是逻辑回归的灵魂:
\(\dfrac{p}{1-p}\) 称为 几率 (odds) :通过 vs 不通过的比值。 \(\log\) 一下就是 ** 对数几率 (log-odds, logit)** 。 模型本质是: ** 对数几率 = 自变量的线性组合** 。 看起来仍然是一条直线,只是 \(Y\) 轴换成了 logit。
系数解读:几率比 OR¶
\(X\) 增 1 单位 → log-odds 增 \(\beta_1\) → 几率乘以 \(e^{\beta_1}\)。 这个乘数就是 几率比 (Odds Ratio, OR) 。
例:\(\beta_1 = 0.7\) → \(\text{OR} = e^{0.7} \approx 2.01\),意思是 \(X\) 每增 1, 通过的几率翻一倍 (注意是几率不是概率!)。
- \(\text{OR} > 1\) → 正向影响
- \(\text{OR} < 1\) → 负向(如 \(\beta = -0.5\) → OR ≈ 0.61,几率掉 39%)
- \(\text{OR} = 1\) → 无效
8.5.4 MLE¶
OLS 在这里没用——\(Y\) 不是连续。 改用 极大似然估计 :每个观测属于伯努利分布,似然函数
取对数得 对数似然 :
这就是机器学习里熟悉的 二元交叉熵 ** 。 它没有闭式解,标准做法是用 ** Newton-Raphson 或 IRLS 迭代到收敛。
8.5.5 把通过率算到底¶
回到学生通过率:用 200 个学生数据拟合,得到
代几个值看看:
- 时长 = 5 h:\(z = -3 + 3 = 0\),\(p = 0.5\)(这就是决策边界)
- 时长 = 8 h:\(z = 1.8\),\(p = 1/(1 + e^{-1.8}) \approx 0.86\)
- OR for 时长 = \(e^{0.6} \approx 1.82\) → 多学 1 小时,通过几率提升 82%
注意区分 几率乘 1.82 和 概率涨 82% —— \(p\) 接近 0 时确实差不多翻倍,\(p\) 接近 1 时几乎不变(已经满了),sigmoid 的两头都被压平。
8.5.6 模型评估¶
二分类的成绩单不是 \(R^2\),而是混淆矩阵衍生的一组指标:
| 指标 | 公式 | 用途 |
|---|---|---|
| 准确率 Accuracy | \((TP+TN)/N\) | 简单总览 |
| 精确率 Precision | \(TP/(TP+FP)\) | 在乎假阳代价 |
| 召回率 Recall (TPR) | \(TP/(TP+FN)\) | 在乎漏检 |
| F1 | \(2PR/(P+R)\) | 精确/召回平衡 |
| AUC-ROC | ROC 曲线下面积 | 阈值无关 |
| 对数损失 logloss | \(-\frac{1}{n}\sum [y\log\hat{p}+(1-y)\log(1-\hat{p})]\) | 概率校准 |
不平衡数据 (正例只占 1%)千万别只看 Accuracy——把所有人预测为负就有 99% 准确率,但模型啥也没学到。 用 F1 / AUC / PR 曲线代替。
阈值与混淆矩阵¶
默认 \(p > 0.5\) → 预测 1,但阈值是 业务参数 :
- 提高阈值 → 提精确率(漏检多)
- 降低阈值 → 提召回率(误报多)
癌症筛查偏召回(漏检致命),垃圾邮件偏精确(误删用户邮件烦),由场景定。
应用场景
信用违约预测、垃圾邮件分类、疾病筛查、广告点击预测、用户流失预警、A/B 转化率建模——任何 是/否 的决策、且需要给出 概率 的场景,逻辑回归通常是 baseline。 它简单、可解释、稳定,深度学习模型最后一层往往就是 sigmoid + 交叉熵——本质还是 logistic。
8.5.7 statsmodels 推断 + sklearn 评估¶
import numpy as np, pandas as pd
import statsmodels.api as sm
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, roc_auc_score
rng = np.random.default_rng(0)
hours = rng.uniform(1, 10, 200)
p_true = 1 / (1 + np.exp(-(-3 + 0.6 * hours)))
y = (rng.uniform(0, 1, 200) < p_true).astype(int)
# statsmodels (含 SE/CI)
X = sm.add_constant(hours)
m = sm.Logit(y, X).fit(disp=False)
print(m.summary())
print(f"\nOR for hours = {np.exp(m.params[1]):.3f}")
# sklearn (重预测)
clf = LogisticRegression().fit(hours.reshape(-1,1), y)
prob = clf.predict_proba(hours.reshape(-1,1))[:, 1]
pred = (prob >= 0.5).astype(int)
print(classification_report(y, pred, digits=3))
print(f"AUC = {roc_auc_score(y, prob):.3f}")
statsmodels.Logit 给推断(SE、CI、p),sklearn.LogisticRegression 给预测和评估,两者搭配最顺手。
8.5.8 多分类扩展¶
二分类用 sigmoid,K 分类有两条路:
- Softmax / Multinomial Logistic :\(K\) 类用 \(K-1\) 个独立 logit,类别概率通过 softmax 归一
- One-vs-Rest (OvR) :每个类别拟合一个二元分类器,预测时取概率最大者
详见第 14 章 ML 模型。
你知道吗
sigmoid 函数最早出现在 19 世纪比利时数学家 Verhulst 研究 种群增长 的工作里——人口增长一开始指数式爆炸,资源耗尽后被压平到承载上限,曲线正是 S 形。 它和逻辑回归共享同一个名字 logistic ,但完全不是用『逻辑学』命名,而是源自希腊语 logistikē (计算)。 同一条曲线后来在化学动力学、神经元激活、流行病传播里反复出现——一个公式三百年没退休。
8.5.9 本节小结¶
- 二分类 \(Y\) → 用 logit 链接把 \((0,1)\) 拉到全实数线,再用线性组合建模;MLE(迭代)求解。
- 系数 \(\hat{\beta}_j\) 取 \(e^{\hat{\beta}_j}\) 是 几率比 OR ,方向与大小一目了然;OR > 1 正向,OR < 1 反向。
- 评估用 AUC / F1 / 混淆矩阵;不平衡数据 绝对 别只看 Accuracy。
- 阈值 0.5 不是金科玉律,按业务调(医疗偏召回、过滤偏精确)。
- 下节 §8.6 学习 多项式回归 ,处理曲线关系。