11.6 小结¶
第 11 章处理的是“一个对象有很多变量”的数据。小率从很多指标画不出图开始,依次遇到五类问题:压缩维度、解释潜在结构、无标签分组、有标签分类、从距离还原位置。
11.6.1 一页速查图¶
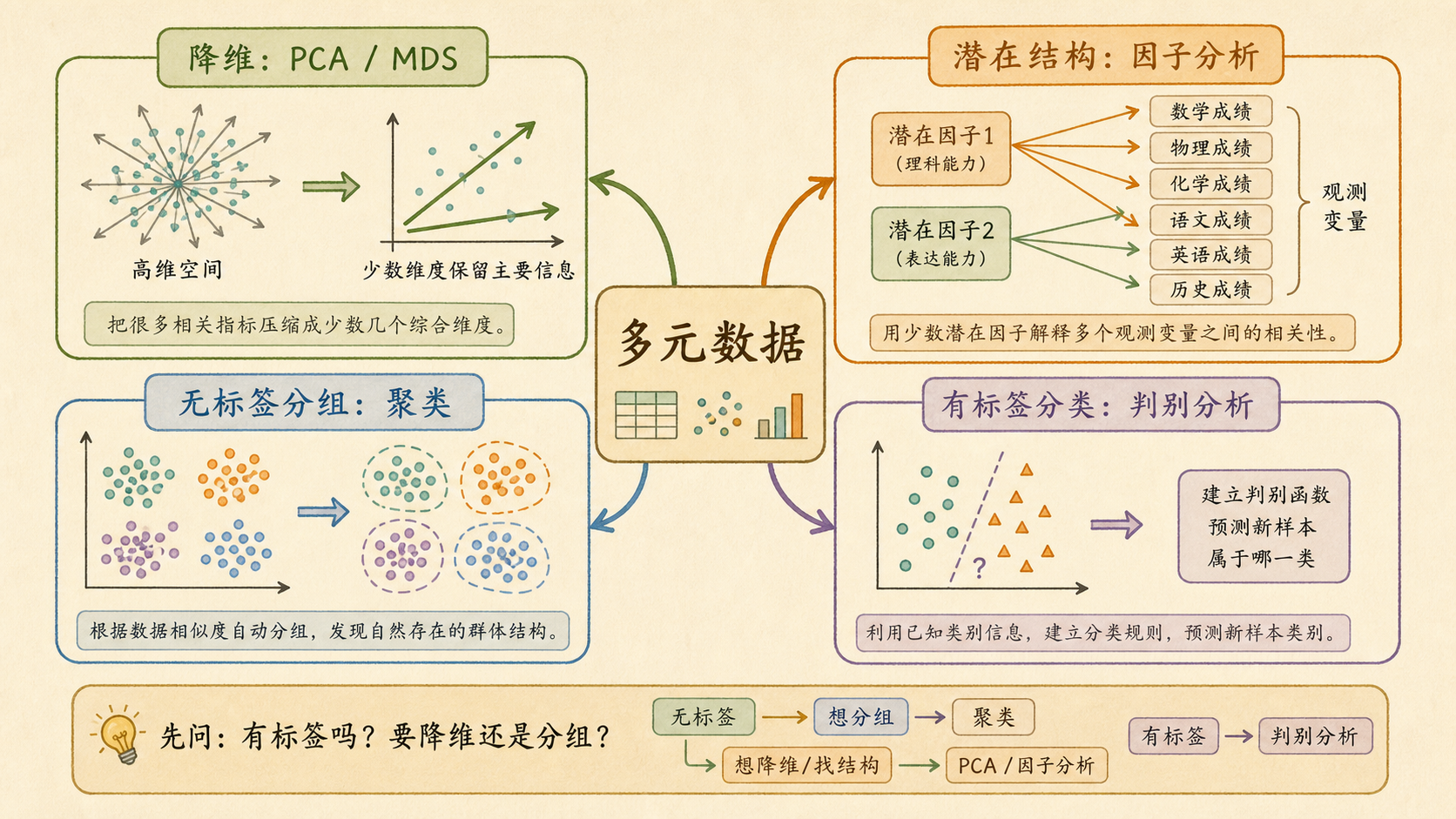
11.6.2 核心知识地图¶
| 任务 | 方法 | 一句话 |
|---|---|---|
| 很多变量想压成几条主线 | PCA | 找方差最大的正交方向 |
| 想解释变量背后的潜在来源 | 因子分析 | 观测变量 = 潜在因子 + 特殊误差 |
| 没有标签,想自然分组 | 聚类 | 组内近,组间远 |
| 有标签,想找分界方向 | LDA / QDA | 类间远,类内紧 |
| 只有距离,想画坐标 | MDS | 距离矩阵还原低维坐标 |
11.6.3 方法速查表¶
| 方法 | 输入 | 输出 | 关键参数 / 指标 |
|---|---|---|---|
| PCA | 数据矩阵 | 主成分坐标、载荷 | 主成分数、解释方差 |
| 因子分析 | 相关变量表 | 因子载荷、因子得分 | 因子数、旋转、共同度 |
| KMeans | 数据矩阵 | 簇标签 | \(K\)、轮廓系数 |
| 层次聚类 | 数据或距离 | 树状图、簇标签 | linkage、切树位置 |
| DBSCAN | 数据矩阵 | 簇标签、噪声点 | \(\varepsilon\)、min_samples |
| LDA | 数据 + 标签 | 判别轴、预测类别 | 类别数、共享协方差 |
| QDA | 数据 + 标签 | 非线性边界 | 每类协方差 |
| MDS | 距离矩阵 | 低维坐标 | 维度、Stress |
11.6.4 多元问题决策树¶
先问三个问题
先问有没有标签;再问目标是降维、解释、分组还是分类;最后看数据形状、距离定义和可解释性要求。
| 场景 | 推荐起点 |
|---|---|
| 无标签,只想画二维图 | PCA / MDS |
| 无标签,想自动分组 | KMeans / 层次聚类 / DBSCAN |
| 有标签,想分类并可视化 | LDA |
| 类别边界明显弯曲 | QDA 或非线性模型 |
| 问卷题目很多,想找潜在维度 | 因子分析 |
| 只有相似度或距离表 | MDS |
11.6.5 常见误读¶
需要注意
PCA 主成分不等于因果因素;聚类标签不等于真实人群;t-SNE 图上的簇间距离不一定可信;LDA 的判别轴最多只有 \(K-1\) 维;MDS 坐标可以旋转和镜像。
常见误读可以压成五句话:
- PCA 不是删除变量,而是重组变量。
- 因子分析的因子命名需要领域知识。
- 聚类结果必须回到业务或研究问题验证。
- LDA 用标签,PCA 不用标签。
- MDS 保距离,不保方向。
11.6.6 术语对照表 (Glossary)¶
| 中文 | English | 本章语境 |
|---|---|---|
| 主成分分析 | Principal Component Analysis | 方差最大方向 |
| 因子分析 | Factor Analysis | 潜在结构解释 |
| 载荷 | Loading | 原变量与主成分 / 因子的关系 |
| 共同度 | Communality | 公共因子解释的方差比例 |
| 聚类 | Clustering | 无标签分组 |
| 轮廓系数 | Silhouette Score | 聚类紧凑与分离程度 |
| 线性判别分析 | Linear Discriminant Analysis | 有监督降维和分类 |
| 二次判别分析 | Quadratic Discriminant Analysis | 弯曲分类边界 |
| 多维尺度分析 | Multidimensional Scaling | 距离矩阵还原坐标 |
| 应力 | Stress | MDS 距离还原误差 |
小率的笔记本
多元统计不是一套算法,而是一组工具箱。变量太多先考虑 PCA;想解释潜在结构用因子分析;没有标签想分组用聚类;有标签想分类用 LDA/QDA;只有距离矩阵就用 MDS。每种方法都要先问“我到底想保留什么信息”。
11.6.7 练一练¶
练习 11.1
一组变量量纲差异很大,做 PCA 前要先做什么?为什么?
参考答案
通常要先标准化。否则量纲大的变量会主导协方差和主成分方向。
练习 11.2
PCA 和因子分析最大的解释差异是什么?
参考答案
PCA 主要做几何降维,解释总方差;因子分析假设观测变量由少数潜在因子和特殊误差生成,重点解释公共结构。
练习 11.3
KMeans 为什么不适合月牙形簇?
参考答案
KMeans 用中心和欧氏距离划分,偏好近似球形的簇。月牙形簇不是凸形,容易被硬切错。
练习 11.4
LDA 最多能降到几维?
参考答案
最多 \(K-1\) 维,\(K\) 是类别数。二分类最多 1 维,三分类最多 2 维。
练习 11.5
MDS 输出图整体旋转 90 度算错吗?
参考答案
不算错。MDS 只保留点间距离,整体平移、旋转、镜像都不会改变距离。