16.5 因果推断¶
阳台上,小率给一盆植物换了新的浇水计划,另一盆按原计划浇。几周后,新计划那盆长得更高。小率兴奋地说:“新计划有效!”均哥指了指阳光:“如果它晒到的太阳也更多呢?”
因果推断(Causal Inference)关心的不是“两个变量是否一起变化”,而是“如果我们改变一个因素,结果会怎样改变”。

16.5.1 因果问题要有反事实¶
对同一盆植物,我们真正想比较的是:
其中 \(Y(1)\) 是接受新浇水计划后的生长结果,\(Y(0)\) 是没有接受新计划时的结果。问题是同一盆植物不能同时处在两个世界里,所以我们需要设计或方法来构造可比对照。
平均处理效应(Average Treatment Effect, ATE)写作:
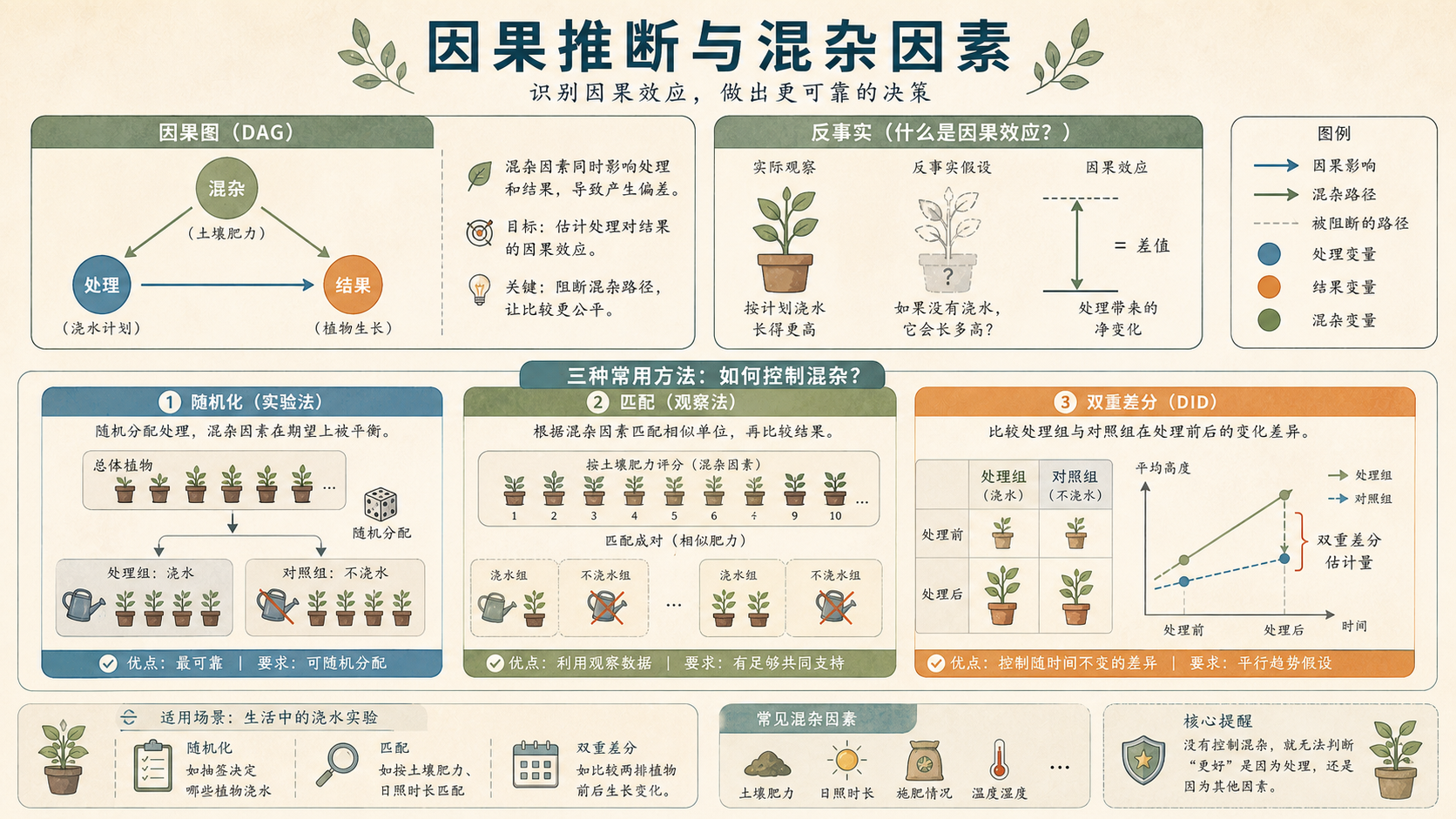
16.5.2 混杂会让相关看起来像因果¶
混杂变量(Confounder)同时影响处理和结果。阳光既可能影响你选择哪盆植物尝试新浇水计划,也会影响植物生长。
常见策略包括:
- 随机实验:让处理分配不依赖潜在混杂。
- 匹配:找相似对象比较。
- 回归控制:把关键混杂变量放进模型。
- 双重差分、工具变量、断点回归:在特定设计下估计因果效应。
16.5.3 DAG 帮我们把假设画出来¶
有向无环图(Directed Acyclic Graph, DAG)不是为了画得漂亮,而是为了逼自己说清楚:
- 哪些变量会影响处理?
- 哪些变量会影响结果?
- 哪些变量同时影响处理和结果,是混杂?
- 哪些变量是处理之后才发生的中介,不能随便控制?
例如“阳光”影响是否采用新浇水计划,也影响植物生长,就是混杂;“叶片数量”如果发生在浇水之后,可能是中介,控制它会遮住一部分处理效应。
16.5.4 双重差分比较变化而不是水平¶
如果某个社区先试点新政策,另一个社区没有试点,直接比较两地平均值可能不公平。双重差分(Difference-in-Differences, DiD)比较的是“变化的差异”:
它依赖一个关键假设:如果没有处理,两组本来会沿着相似趋势变化。这叫平行趋势假设。
16.5.5 随机分组下的简单估计¶
import numpy as np
rng = np.random.default_rng(7)
n = 100
treat = rng.binomial(1, 0.5, size=n)
sunlight = rng.normal(6, 1, size=n)
growth = 10 + 2.0 * treat + 0.8 * sunlight + rng.normal(0, 1, size=n)
ate_hat = growth[treat == 1].mean() - growth[treat == 0].mean()
print("estimated treatment effect:", round(ate_hat, 2))
随机分组让两组阳光分布在期望上相似,因此均值差可以估计处理效应。观察数据里就不能这么轻松,需要认真处理混杂。
因果不是更高级的相关
相关可以从数据里直接算出来;因果需要额外假设、研究设计或自然实验。没有设计意识,复杂模型也可能只是更精致地拟合偏差。
小率的笔记本
因果推断的核心问题是反事实:同一个对象如果接受和不接受处理,结果会差多少。随机化是最干净的办法;做不到随机化时,要明确混杂、假设和识别策略。