14.1 近邻算法¶
社团招新现场,小率拿到一位新同学的资料:喜欢摄影和音乐,周五晚上有空,过去参加过两次展览。他想推荐一个活动,却还没有训练任何复杂模型。
均哥把过去同学的兴趣卡片铺在桌上:先找和这位新同学最像的几个人,再看看这些“邻居”最终参加了什么活动。这个朴素想法,就是 K 近邻(K-Nearest Neighbors, KNN)。

不训练模型也能预测吗
KNN 属于 懒惰学习(Lazy Learning):训练阶段几乎只存数据,预测时才临时找最近的 \(K\) 个邻居投票或平均。它把“相似的人往往有相似选择”写成算法。
所以 KNN 的模型就是那一堆历史同学卡片?
对。它不急着总结规则,而是在预测时现找邻居。
14.1.1 先找邻居,再投票¶
训练集记作:
\[
\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),\ldots,(\mathbf{x}_n,y_n)\}
\]
给定新样本 \(\mathbf{x}\),KNN 做三步:
- 计算 \(\mathbf{x}\) 与每个历史样本的距离 \(d(\mathbf{x},\mathbf{x}_i)\)。
- 取距离最小的 \(K\) 个样本,记作 \(\mathcal{N}_K(\mathbf{x})\)。
- 分类时多数投票,回归时取平均。
分类公式可以写成:
\[
\hat y=\arg\max_c \sum_{i\in \mathcal{N}_K(\mathbf{x})}\mathbb{1}(y_i=c)
\]
回归公式是:
\[
\hat y=\frac{1}{K}\sum_{i\in \mathcal{N}_K(\mathbf{x})}y_i
\]
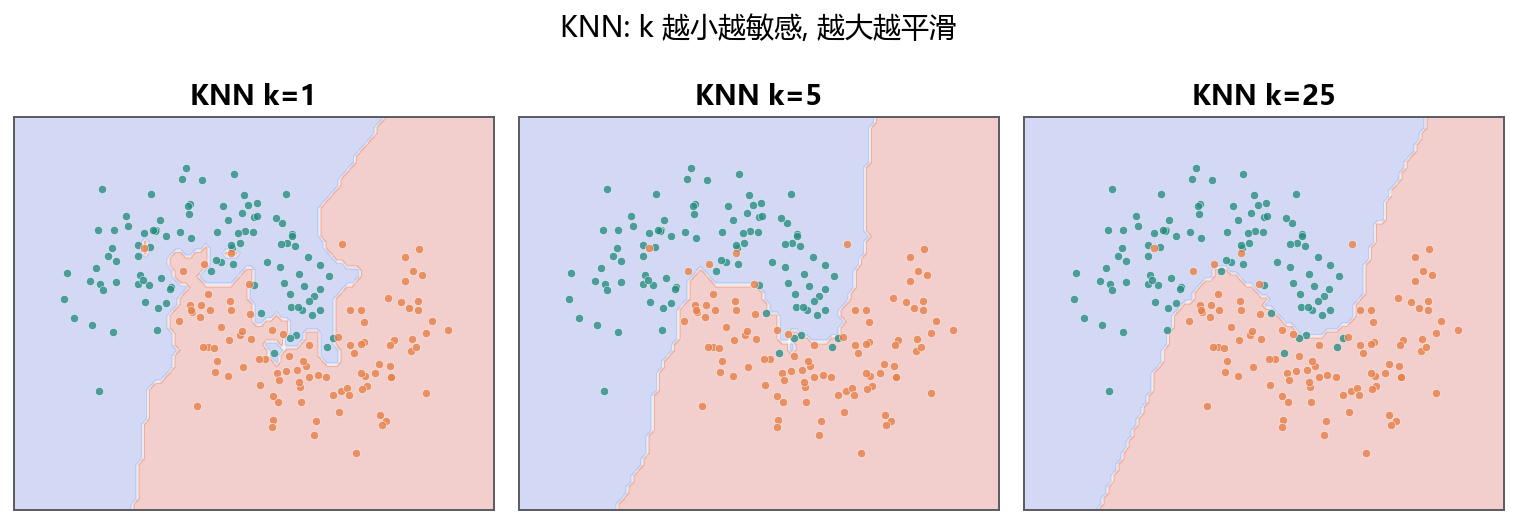
14.1.2 K 是偏差和方差的旋钮¶
\(K=1\) 时,每个新点只听最近一个邻居。边界很灵活,也很容易被噪声带偏。\(K\) 很大时,模型听很多邻居,边界更平滑,但局部差异会被抹掉。
| K 的大小 | 训练表现 | 新样本风险 | 典型问题 |
|---|---|---|---|
| 很小 | 很好 | 不稳定 | 高方差、过拟合 |
| 适中 | 稳定 | 较稳 | 需要交叉验证选择 |
| 很大 | 过于平滑 | 漏掉局部结构 | 高偏差、欠拟合 |
K 不是越大越稳,也不是越小越准,而是要让邻居数量刚刚好。
很好。实际项目里用交叉验证选 K,比拍脑袋靠谱。
14.1.3 距离决定谁算邻居¶
距离选错了,邻居就找错了。
| 距离 | 公式 | 常见场景 |
|---|---|---|
| 欧氏距离 | \(\sqrt{\sum_j(x_j-z_j)^2}\) | 同尺度连续特征 |
| 曼哈顿距离 | $\sum_j | x_j-z_j |
| 余弦距离 | \(1-\frac{\mathbf{x}\cdot\mathbf{z}}{\|\mathbf{x}\|\|\mathbf{z}\|}\) | 文本向量、方向相似 |
| 汉明距离 | 不同位置的个数 | 二值特征 |
KNN 对量纲特别敏感。通勤距离用“米”,兴趣分用 0 到 1,如果不标准化,距离几乎会被通勤距离支配。
KNN 通常必须标准化
标准化、归一化等预处理要放进 Pipeline,并且在交叉验证的每一折内部拟合,避免数据泄漏。
14.1.4 用 Python 跑一次 KNN¶
from sklearn.datasets import make_classification
from sklearn.model_selection import GridSearchCV, StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
X, y = make_classification(
n_samples=300,
n_features=6,
n_informative=4,
random_state=2026,
)
pipe = make_pipeline(StandardScaler(), KNeighborsClassifier())
param_grid = {"kneighborsclassifier__n_neighbors": range(1, 22, 2)}
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=2026)
search = GridSearchCV(pipe, param_grid, cv=cv, scoring="f1")
search.fit(X, y)
print("最佳 K =", search.best_params_["kneighborsclassifier__n_neighbors"])
print("交叉验证 F1 =", round(search.best_score_, 3))
小率的笔记本
KNN 用邻居投票或平均做预测。它直观、无需显式训练,但预测慢、怕高维、怕量纲不一致。K 和距离度量要结合交叉验证与数据场景选择。