13.3 偏差-方差权衡¶
小率想预测每个活动的报名人数。他先用一条直线描述“宣传次数越多,报名越多”,结果抓不住音乐会和篮球赛的周末高峰;后来换成一条能弯来弯去的曲线,训练数据几乎全贴上了,可下周预测反而更差。
模型太简单,主规律都没学到;模型太复杂,又会把偶然波动当规律。机器学习里最常见的拉扯,就叫 偏差-方差权衡(Bias-Variance Tradeoff)。
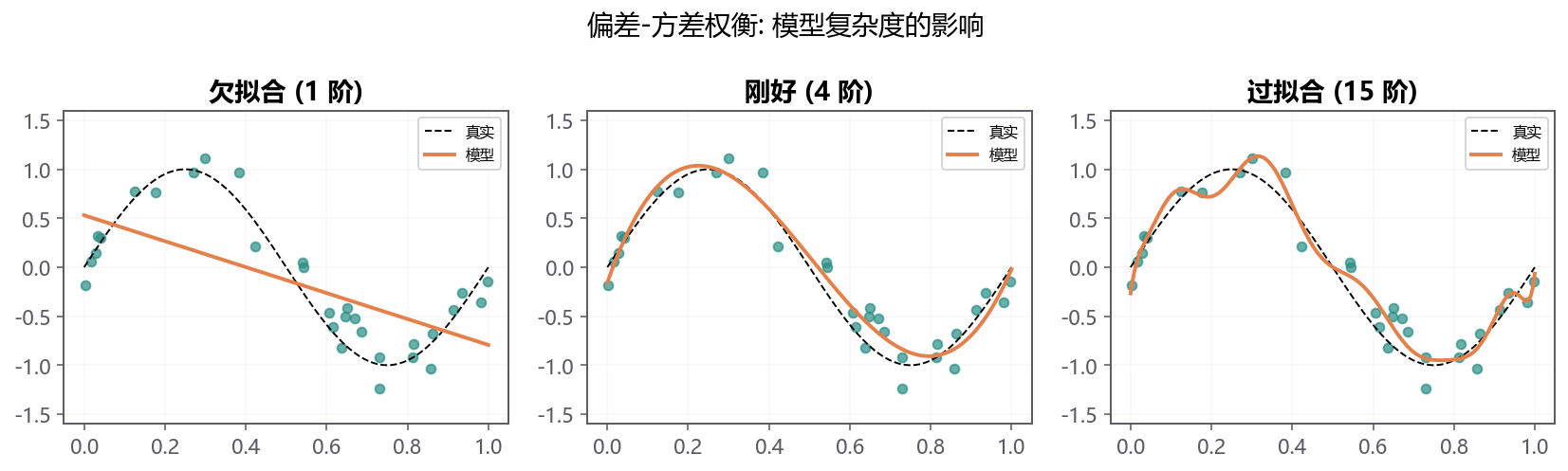
13.3.1 欠拟合是主趋势没学到¶
偏差(Bias) 可以理解成模型平均预测与真实规律之间的系统性偏离。模型太简单时,偏差往往大。
如果真实关系是“宣传次数增加后报名上升,但周末活动会额外火爆”,一条直线可能只能学到“大致上升”,却学不到周末高峰。这就是 欠拟合(Underfitting)。
| 现象 | 训练误差 | 验证误差 | 常见原因 |
|---|---|---|---|
| 高偏差 | 高 | 高 | 模型太简单、特征太少、正则太强 |
13.3.2 过拟合是把噪声也背下来了¶
方差(Variance) 衡量模型对训练样本变化有多敏感。模型太复杂时,换一批样本,学出来的曲线可能大变样。
活动报名里,有一天因为海报刚好刷屏而报名暴涨;另一天因为暴雨而报名暴跌。这些是偶然事件。如果模型强行穿过每个点,就会把偶然事件当成一般规律。这就是 过拟合(Overfitting)。
| 现象 | 训练误差 | 验证误差 | 常见原因 |
|---|---|---|---|
| 高方差 | 低 | 高 | 模型太复杂、样本太少、噪声太多 |
一句话记住
简单模型偏差大、方差小;复杂模型偏差小、方差大。好模型不追求训练集满分,而是在两者之间找到验证误差最低的位置。
13.3.3 误差可以拆成三部分¶
对一个输入点 \(\mathbf{x}\),如果真实值为:
其中噪声满足 \(E(\varepsilon)=0\)、\(\operatorname{Var}(\varepsilon)=\sigma^2\)。模型预测的期望平方误差可以拆成:
三项的意思是:
- 偏差平方:模型平均离真实规律有多远。
- 方差:模型随训练集变化有多摇摆。
- 不可约噪声:再好的模型也无法消掉的随机波动。
13.3.4 用交叉验证看复杂度¶
import numpy as np
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
rng = np.random.default_rng(2026)
X = np.linspace(0, 6, 120).reshape(-1, 1)
y = np.sin(X.ravel()) + rng.normal(0, 0.25, size=120)
for degree in [1, 4, 15]:
model = make_pipeline(PolynomialFeatures(degree), Ridge(alpha=0.01))
score = cross_val_score(model, X, y, cv=5, scoring="neg_mean_squared_error")
print(f"{degree} 阶模型 CV 均方误差 = {-score.mean():.3f}")
低阶模型如果训练和验证都差,通常是高偏差;高阶模型如果训练很好但验证很差,通常是高方差。
不要只看训练误差
训练误差只能说明模型对旧题的记忆程度。偏差-方差权衡关心的是新题表现,所以一定要配合验证集或交叉验证。
小率的笔记本
偏差大是“没学到主规律”,方差大是“对样本太敏感”。训练误差和验证误差一起看,才能判断欠拟合还是过拟合。不可约噪声存在时,模型不可能把误差降到 0。