5.5 大数定律¶
小率连续抛硬币,前 8 次都是正面。他盯着硬币说:下一次反面概率是不是该更大了?均哥把记录纸推过去:长期比例会靠近 50%,但下一次硬币不会记账。

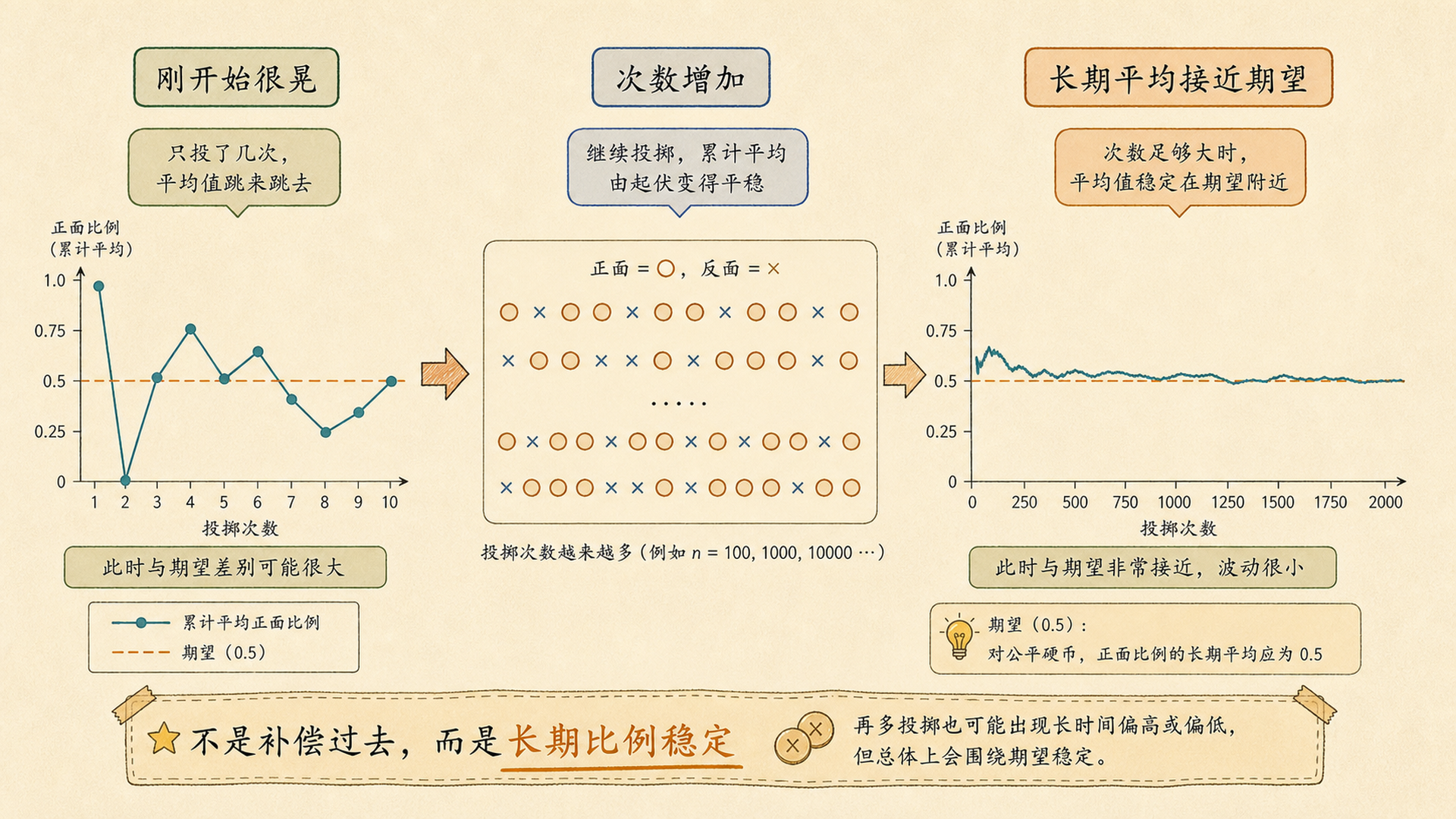
连出正面后,下一次会补偿吗
大数定律说的是“长期平均会靠近期望”,不是“下一次会自动反向补偿”。这两个说法差得很远。
5.5.1 长期平均会靠近期望¶
如果前面正面太多,后面是不是必须多出反面才能拉回来?
不是必须。每次仍然独立。只是次数多了以后,前面那几次的影响被稀释。
大数定律(Law of Large Numbers, LLN):当独立同分布样本越来越多时,样本均值会趋近总体期望。
\[
\bar{X}_n=\frac{X_1+\cdots+X_n}{n}\ \longrightarrow\ \mu
\]
5.5.2 LLN 和 CLT 的分工¶
| 问题 | 大数定律回答 | 中心极限定理回答 |
|---|---|---|
| 样本均值最终去哪 | 去 \(\mu\) 附近 | 也以 \(\mu\) 为中心 |
| 它怎么波动 | 越来越稳 | 近似正态,宽度是 SE |
| 关注重点 | 收敛方向 | 分布形状和概率计算 |
LLN 像告诉我“会到哪里”,CLT 像告诉我“路上怎么晃”?
这句话很准。一个讲终点,一个讲波动形状。
5.5.3 赌徒谬误错在哪里¶
赌徒谬误
“已经连出 8 次正面,下一次反面概率更高”是错的。若硬币公平且每次独立,则无论前面发生什么,下一次反面的概率仍是 0.5。
长期比例靠近 0.5,不是靠下一次“补偿”,而是靠分母变大后,早期极端结果的影响越来越小。
5.5.4 用模拟看收敛¶
import numpy as np
rng = np.random.default_rng(2026)
rolls = rng.integers(1, 7, size=5000)
running_mean = np.cumsum(rolls) / np.arange(1, len(rolls) + 1)
for n in [10, 100, 1000, 5000]:
print(f"前 {n:4d} 次累计平均 = {running_mean[n-1]:.3f}")
你知道吗
蒙特卡洛模拟就是大数定律的工程用法:用大量随机样本的平均去近似一个难算的数学期望。样本越多,结果通常越稳定,但计算成本也会增加。
5.5.5 大数定律也有前提¶
大数定律常见版本需要随机变量独立、同分布,并且期望存在。如果数据来自会随时间变化的机制,或者极端重尾到连期望都不存在,就不能直接套用。
那我看长期平均之前,也要问数据是不是同一个规则生成的?
对。稳定机制是长期平均有意义的前提。
小率的笔记本
- 大数定律:样本均值会靠近总体期望。
- 它不表示下一次会补偿,独立事件没有记忆。
- LLN 讲收敛方向,CLT 讲抽样分布形状。
- 蒙特卡洛模拟就是用大量随机样本平均来近似期望。