5.1 为什么要抽样¶
暑假下午,奶茶店门口排了长队。小率想知道「平均等待时间」到底有多长,可店员不可能停下工作给每位顾客做访谈。均哥拿起几张排队小票,说:先别急着问所有人,统计学真正关心的是:怎样用一小部分人,尽量不偏地代表所有人。

排队小票能代表所有顾客吗
如果只拿最近 10 张小票,可能刚好碰上午后高峰;如果只问愿意回答的人,可能只听到特别满意或特别不满意的声音。抽样的第一步不是算平均,而是先问:样本从哪里来。
5.1.1 总体太大时,抽样是唯一入口¶
为什么不直接把今天所有顾客都问一遍?这样不是最准吗?
有些总体太大、太贵,甚至测量会破坏对象。抽样不是偷懒,是现实条件下的严谨方案。
总体(Population) 是我们真正关心的全部对象。样本(Sample) 是从总体里抽出来的一部分对象。
| 场景 | 总体 | 为什么不普查 |
|---|---|---|
| 奶茶等待时间 | 当天所有顾客 | 人流不断变化 |
| 盒装牛奶质量 | 同批全部牛奶 | 拆开就不能卖 |
| 城市月薪 | 城市所有劳动者 | 人数巨大且收入隐私 |
| 在线课程满意度 | 所有学习者 | 许多人不会回应 |
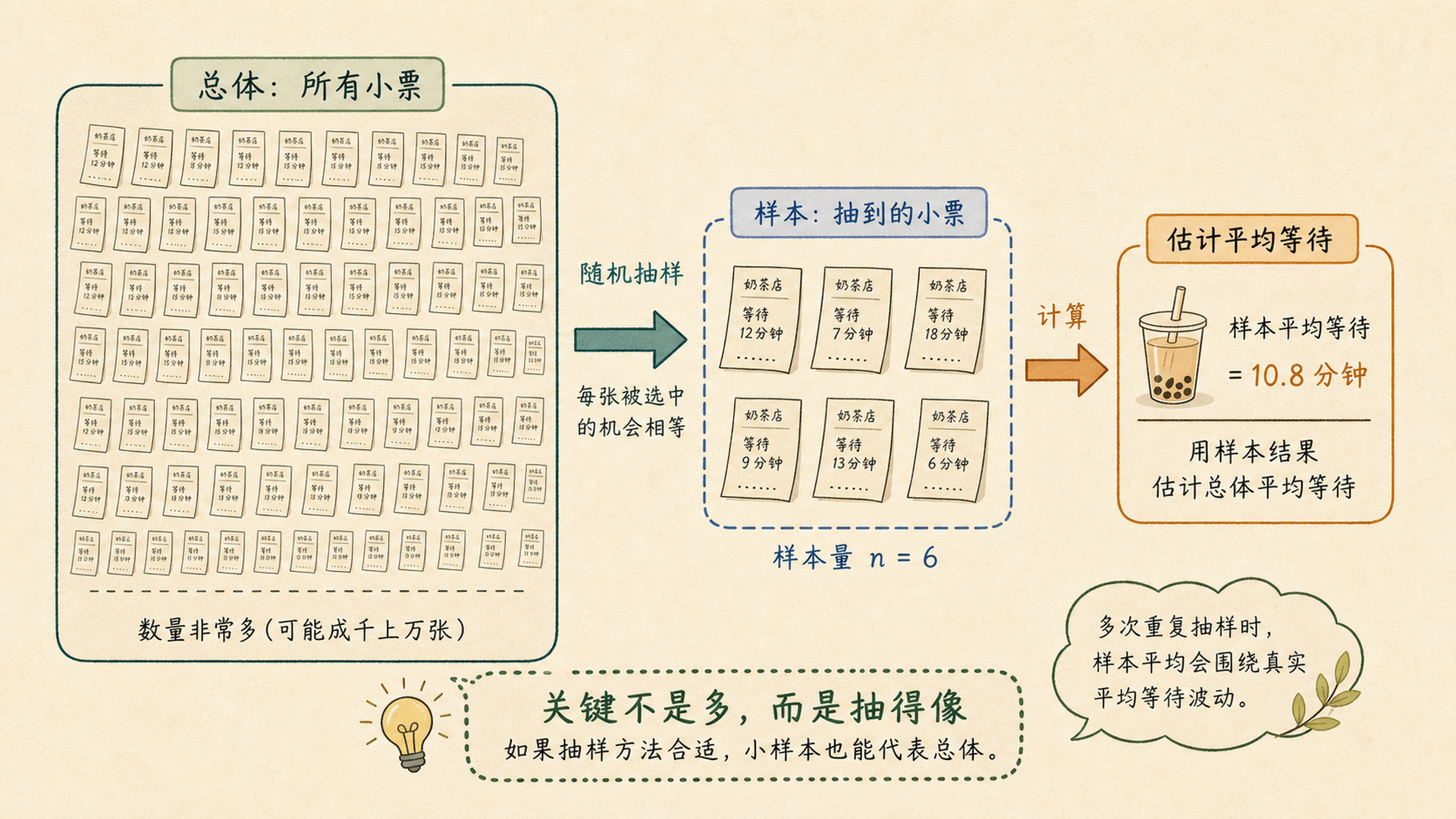
5.1.2 抽得像,比抽得多更重要¶
那是不是样本越大越好?抽 10 万人总比抽 1000 人可靠吧?
如果 10 万人都来自同一个圈子,它们只是很稳定地偏。抽样方法决定偏差,样本量主要决定波动。
记总体平均等待时间为 \(\mu\),样本平均等待时间为 \(\bar{x}\)。一次好的抽样希望满足两件事:
\[
\text{偏差小:}\quad E[\bar{X}] \approx \mu
\]
\[
\text{波动小:}\quad \bar{X}\text{ 在不同抽样中不要晃得太厉害}
\]
前者靠抽样设计,后者靠样本量和总体波动程度。
5.1.3 偏差不会被大样本自动治好¶
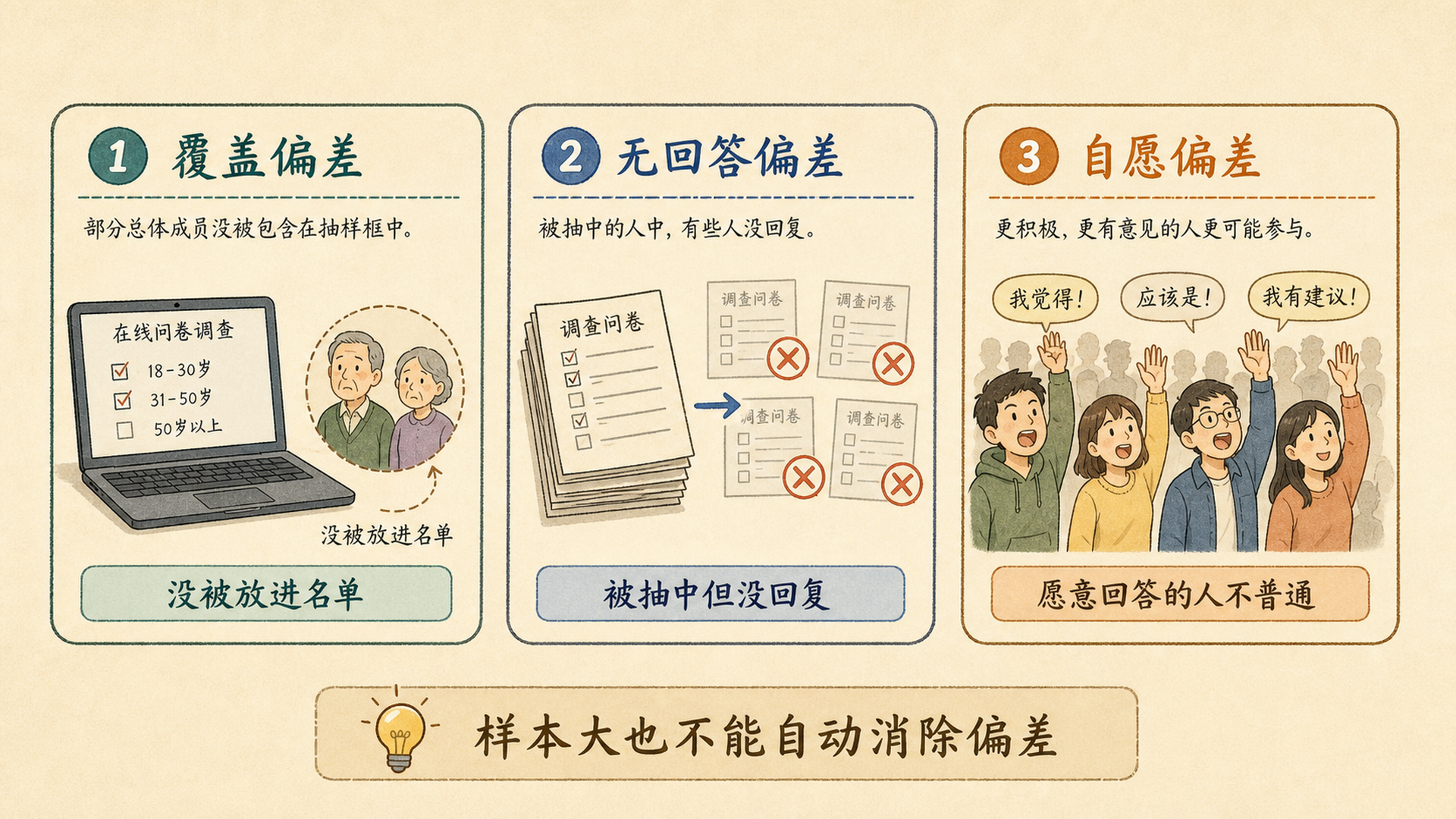
需要注意
样本量只能降低随机波动,不能修复系统偏差。比如只在高档商场调查月薪,即使问 10 万人,也不代表全城市劳动者。
原来“大数据”也可能很偏?
对。统计学先问“数据怎么来的”,再问“数据有多少”。
5.1.4 用模拟看一次偏差¶
下面用一个拟真城市月薪总体做演示:大多数人月薪集中在 5000-12000 元,但少量高收入者会拉高均值。如果调查渠道漏掉高收入者,样本会稳定偏低。
import numpy as np
rng = np.random.default_rng(2026)
# 拟真总体:绝大多数普通收入,少数高收入
ordinary = rng.normal(8200, 1800, 9800)
high_income = rng.normal(42000, 7000, 200)
population = np.concatenate([ordinary, high_income])
population = np.clip(population, 2500, None)
true_mean = population.mean()
# 随机抽样
random_sample = rng.choice(population, size=500, replace=False)
# 带偏抽样:只从低于 20000 的人中抽
biased_frame = population[population < 20000]
biased_sample = rng.choice(biased_frame, size=500, replace=False)
print(f"总体均值:{true_mean:.0f} 元")
print(f"随机样本均值:{random_sample.mean():.0f} 元")
print(f"带偏样本均值:{biased_sample.mean():.0f} 元")
三秒判断法
看到任何调查结论,先问三件事:总体是谁?抽样框覆盖了谁?没回应的人可能和回应者不同吗?
5.1.5 普查什么时候仍然必要¶
你知道吗
全国人口普查就是少数必须尽量接近总体调查的例子。它成本极高,但会影响公共服务、行政规划、教育医疗资源配置和人口政策。大多数日常研究不用普查,是因为目标通常是估计、比较或预测;但当政策必须依赖完整底账时,普查仍不可替代。
所以抽样不是普查的低配版,而是另一种工具?
正是。总体小、每个个体都极重要时,用普查;总体大、只需估计规律时,用抽样。
小率的笔记本
- 总体是我真正想了解的全部对象,样本是我实际看到的一部分。
- 抽样先解决“代表性”,再谈“样本量”。
- 偏差靠设计修,波动靠样本量降。
- 大样本不自动等于好样本。