7.3 学生氏检验¶
电池抽检里,厂家给了长期标准差 \(\sigma\)。但现实里更多时候,小率只有一小份样本。比如社团帮社区检测 16 只节能灯泡,包装宣称平均寿命 1100 小时,样本测得:
| 样本量 | 样本均值 | 样本标准差 |
|---|---|---|
| 16 | 1080 小时 | 100 小时 |
这一次,\(\sigma\) 不知道,只能用样本标准差 \(s\) 顶上。问题也就变成:这个额外的不确定性要不要补偿?

7.3.1 σ 未知时要用胖尾补偿¶
z 检验的分母是:
t 检验把未知的 \(\sigma\) 换成样本标准差 \(s\):
但 \(s\) 本身会波动,尤其当 \(n\) 很小时,分母并不稳定。于是参考分布不再是标准正态,而是 t 分布(t-distribution)。
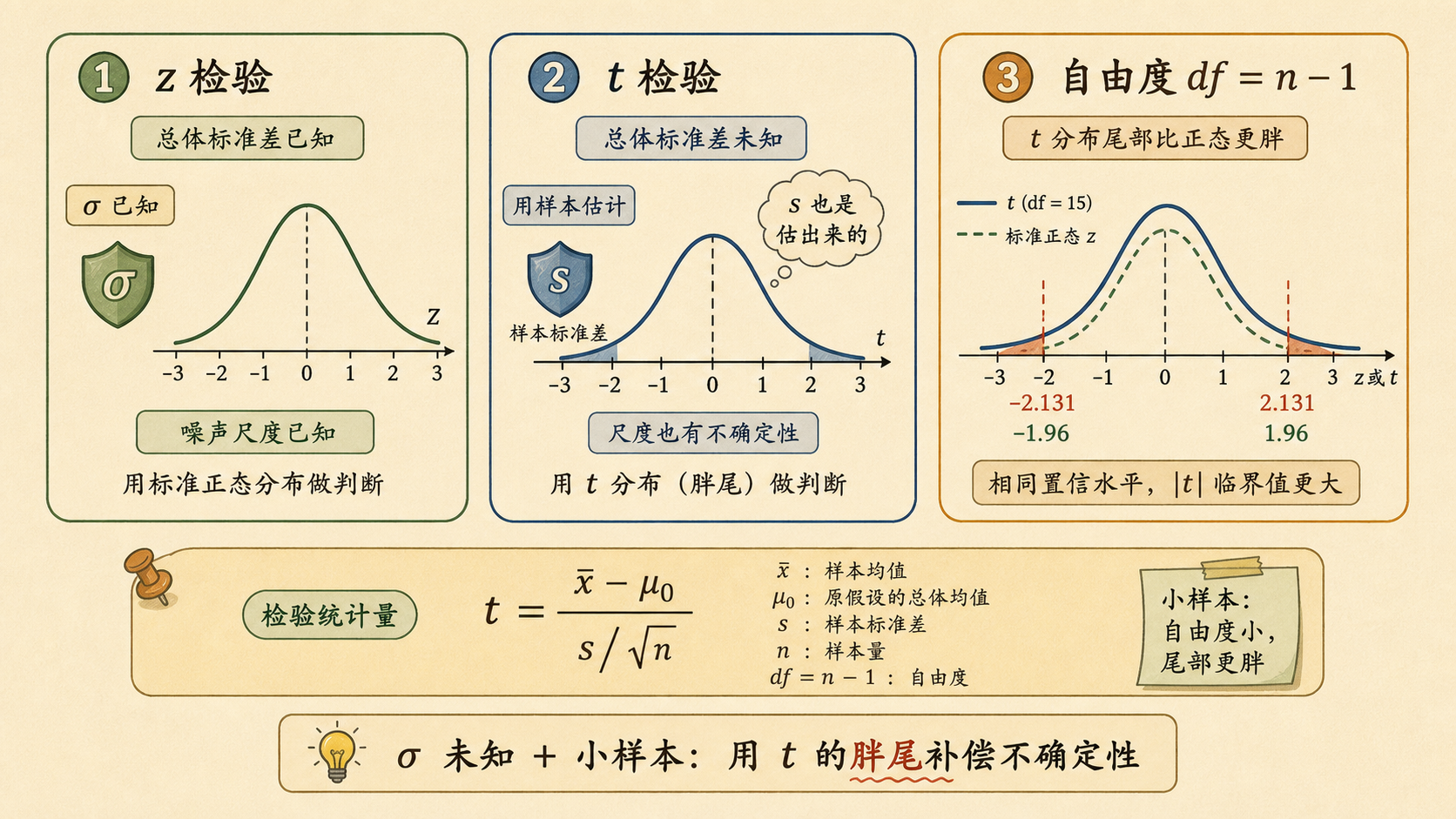
自由度(degrees of freedom)为:
样本越小,t 分布尾巴越胖,临界值越大;样本越大,t 分布越接近 z 分布。
你知道吗
t 分布由 William S. Gosset 在 1908 年提出。他在吉尼斯酒厂工作,发表论文时使用笔名 Student,所以它也常被称为 Student's t 分布。
7.3.2 单样本 t 检验:灯泡数据怎么判¶
灯泡问题写成假设:
统计量:
自由度:
在 \(\alpha=0.05\) 双侧检验下,临界值约为 \(\pm 2.131\)。因为 \(|-0.80|<2.131\),所以不拒绝 \(H_0\)。
7.3.3 两组比较优先用 Welch¶
若比较两个独立小组,比如 A 班和 B 班的练习成绩,常用 独立双样本 t 检验(two-sample t-test)。
传统 Student t 检验假设两组方差相等。但现实里两组方差常常不一样,所以更推荐 Welch t 检验(Welch's t-test):
Welch 的自由度由近似公式计算,软件会自动处理。
默认建议
在 Python 中比较两个独立样本时,优先使用 scipy.stats.ttest_ind(a, b, equal_var=False)。这就是 Welch t 检验,少了一个“方差相等”的额外假设。
7.3.4 三种 t 检验别混¶
| 场景 | 问题 | Python |
|---|---|---|
| 单样本 t | 一组均值是否等于某值 | ttest_1samp |
| 独立双样本 t | 两组不同对象均值是否不同 | ttest_ind |
| 配对 t | 同一批对象前后是否变化 | ttest_rel |
配对 t 检验会在 §7.8 单独讲。这里先记住:如果是同一批学生训练前后各测一次,就不能当成两个独立样本。
独立和配对是设计问题
统计检验不是看表格长相决定的,而是看数据如何产生。两列数据若来自同一批对象的前后测量,就是配对结构。
7.3.5 Python 跑单样本和 Welch t¶
import numpy as np
from scipy import stats
# 单样本 t:灯泡寿命
n = 16
xbar = 1080
s = 100
mu0 = 1100
t_stat = (xbar - mu0) / (s / np.sqrt(n))
p_two = 2 * stats.t.cdf(-abs(t_stat), df=n - 1)
print(f"单样本 t = {t_stat:.2f}, p = {p_two:.4f}")
# Welch t:两班成绩
rng = np.random.default_rng(2026)
a = rng.normal(78, 12, 20)
b = rng.normal(72, 10, 25)
t, p = stats.ttest_ind(a, b, equal_var=False)
print(f"Welch t = {t:.2f}, p = {p:.4f}")
完整脚本见:
7.3.6 什么时候 t 检验会失灵¶
t 检验依赖几个基本条件:
- 观测值近似独立。
- 数据没有极端离群值主导。
- 小样本时总体分布不要严重偏态。
- 双样本比较时先分清独立还是配对。
如果样本很小又强偏态,可以考虑非参数检验;如果数据是同一批对象前后变化,使用配对 t;如果是比例问题,不要硬套 t。
小率的笔记本
t 检验用于 \(\sigma\) 未知的均值问题。单样本统计量是 \(t=(\bar x-\mu_0)/(s/\sqrt n)\),自由度通常是 \(n-1\)。两独立组比较时默认 Welch;同一批对象前后测量要用配对 t。