13.7 过拟合与正则化¶
小率给推荐模型加了很多特征:活动海报颜色、标题字数、报名当天温度、教室楼层、上一场活动是否下雨。训练集分数一路上涨,验证集却越来越差。
过拟合(Overfitting) 像是把旧题答案背得太细。正则化(Regularization) 则是在训练时加一点约束,让模型别把每个噪声都当成宝。
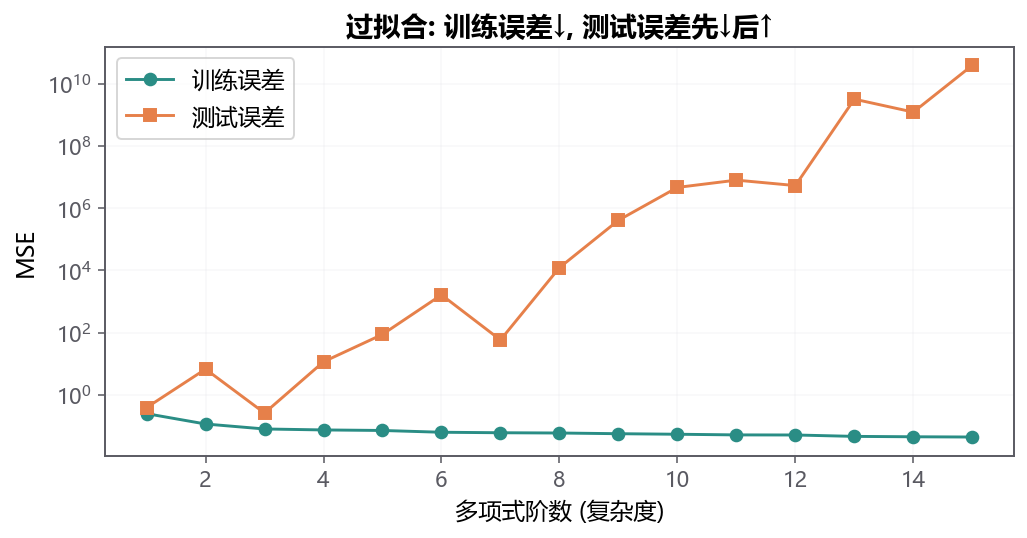
训练集这么好看,为什么一上新数据就翻车?
因为模型把旧题里的偶然细节也学进去了。我们要让它学主线,少记噪声。
13.7.1 正则化是在损失里加约束¶
普通训练只最小化预测误差:
\[
\text{Loss}=\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat y_i)^2
\]
正则化把目标改成:
\[
\text{Loss}_{\text{regularized}}
=\frac{1}{n}\sum_{i=1}^{n}(y_i-\hat y_i)^2+\lambda\cdot\text{Penalty}
\]
\(\lambda\) 控制惩罚力度。\(\lambda\) 越大,模型越被迫简单;\(\lambda\) 太大,又可能欠拟合。
这像是在说:你可以拟合数据,但别为了拟合付出太复杂的代价。
正是这个意思。正则化不是不让模型学,而是不让它乱学。
13.7.2 L2 让参数变小,L1 让参数变少¶
L2 正则化(Ridge) 惩罚参数平方和:
\[
\lambda\sum_{j=1}^{p}w_j^2
\]
它会把参数往 0 收缩,但通常不会精确变成 0。
L1 正则化(Lasso) 惩罚参数绝对值和:
\[
\lambda\sum_{j=1}^{p}|w_j|
\]
它可能把一部分参数压到 0,因此有特征选择效果。
| 方法 | 惩罚项 | 常见效果 |
|---|---|---|
| Ridge | \(\sum w_j^2\) | 参数平滑收缩 |
| Lasso | $\sum | w_j |
| ElasticNet | 二者混合 | 在相关特征多时更稳 |
13.7.3 早停和数据增强也是约束¶
正则化不只出现在公式里。很多训练技巧本质上都在限制模型过度贴合训练集:
- 早停(Early Stopping):验证误差开始变差就停止训练。
- Dropout:训练神经网络时随机关闭一部分单元,减少共同适应。
- 数据增强(Data Augmentation):让模型看到更多合理变化,别记住固定样子。
- 剪枝(Pruning):限制树模型过深、叶子过细。
所以正则化的本质是给模型一点克制?
是。克制得刚好,模型才更容易泛化。
13.7.4 用 Ridge 看惩罚力度¶
from sklearn.datasets import make_regression
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
X, y = make_regression(
n_samples=100,
n_features=30,
noise=20,
random_state=2026,
)
for alpha in [0.0, 0.1, 1.0, 10.0, 100.0]:
model = Ridge(alpha=alpha)
scores = cross_val_score(model, X, y, cv=5, scoring="neg_root_mean_squared_error")
print(f"alpha={alpha:>5}: CV RMSE={-scores.mean():.2f}")
alpha 太小,约束不足;太大,模型被压得过于简单。实际项目里通常用交叉验证选择它。
正则化不能修复坏数据
如果标签错、特征泄漏、训练和上线环境不同,正则化只能缓解复杂度问题,不能把错误的数据生成过程变正确。
小率的笔记本
过拟合是训练集好、新数据差。正则化通过惩罚复杂度、早停、Dropout、数据增强等方式约束模型。L2 收缩参数,L1 可能让参数变成 0;惩罚强度要用验证集或交叉验证选择。