1.2 统计学简史¶
“统计学是不是现代人才发明的?”小率在博物馆门口问。
均哥摇摇头:“只要人类开始管理粮食、人口、土地、疾病和风险,就已经在做统计学的前身了。只不过那时候还没有今天这些名字。”

统计学的历史,不是一串需要硬背的人名,而是一条很朴素的线索:
人类遇到问题,先把事实记录下来,再从记录里寻找规律,最后用规律帮助下一次决定。
所以,统计学并不是从黑板上的公式开始的。它先出现在粮仓门口、户籍账册、瘟疫死亡清单、战地医院、天文观测台、农田实验站、彩票销售点,最后才走进电脑、手机和 AI 模型。
1.2.1 古代:先把东西数清楚¶
如果把统计学的历史拍成电影,第一幕不会出现在大学教室,而会出现在一个很忙的古代仓库。
秋收刚结束,粮食一袋袋搬进仓里。负责记账的人坐在案边,面前可能是竹简、木牍、泥板,也可能是纸张账册。他要记下今年收了多少粮,哪个村交了多少,粮仓还剩多少,遇到灾荒时能救济几户。旁边另一张账上,写的是人口、田亩、赋税、徭役:谁家有几口人,谁家有多少地,谁家要服役,谁家可以免税。
这些数字听起来不浪漫,却非常现实。数错了,轻则账目混乱,重则有人挨饿、有人被多征税、有人被漏掉救济。古代统计学的第一条朴素原则就是:如果你连“有多少”都不知道,就很难谈公平、治理和计划。

在中国古代,这类工作有一个很典型的制度化场景:户部。
户部是古代中央官署之一。到唐代,户部相关机构要管户口、田土、赋税、仓储、漕运等事务;到明清,户部更是和全国疆土、田地、户籍、赋税、俸饷、财政收支紧密相关。换成今天的话说,户部很像一个把“人口数据库、土地数据库、财政系统、粮食物流系统”揉在一起的超级部门。
当然,古代没有电子表格,也没有数据库。一个地方上报的人口多一点,少一点,背后都会牵动税粮、兵役和财政。地方官可能想少报,百姓可能想躲避重役,中央又希望掌握真实情况。于是,“数清楚”从来不是单纯的技术问题,也和权力、利益、生活压力连在一起。
一个很早的中国故事,是《国语》里提到的“料民”。“料”有统计、清查的意思。周宣王在太原一带清查人口,目的与兵源、赋税有关。大臣仲山甫劝他“民不可料也”,不是说人口永远不能数,而是在提醒:如果清查只是为了加重负担,数字会变成压在人身上的石头。这个故事很适合作为统计学的第一课:数据本身不是善也不是恶,关键看它被怎样收集、怎样解释、怎样使用。
古埃及也有类似的故事。尼罗河每年泛滥,洪水退去后,土地边界可能被冲刷得不清楚。要重新丈量土地,才知道谁家的地在哪里,税该怎么算,粮食该怎样征收。古巴比伦留下过大量商业、粮食和借贷记录。古代国家要修水渠、建城墙、组织军队,也都离不开人口和物资的清点。
这一阶段的统计思想很像整理一个大家庭的储物间:
- 先记录:有多少人、多少粮、多少地、多少牲畜。
- 再汇总:一个村、一个县、一个国家合起来是多少。
- 再安排:税粮怎么收,救济怎么发,工程怎么做。
- 最后追问:这些数字准不准,有没有人被漏掉,有没有人被重复计算。
均哥的小提醒
古代统计学的关键词不是“公式”,而是“清点”。它解决的是最基本的问题:把世界从一团模糊的经验,变成可以讨论的记录。没有这一步,后面的推理、比较和预测都无从谈起。
1.2.2 近代:开始用数据讲道理¶
时间来到近代,统计学开始变得更像我们今天熟悉的样子。人们不再只满足于“数清楚”,而是开始追问:这些数字能不能说明问题?能不能帮我们发现危险?能不能说服别人改变做法?
伦敦死亡清单:一个布商看见了城市的脉搏¶
17 世纪的伦敦,瘟疫时常让人心惊。城里会发布一种叫“死亡清单”的东西,记录各个教区一周里有多少人死亡,以及大致死因。对普通人来说,这像是一份危险地图:哪里死亡多,哪里就要少去;瘟疫数字上升,富人可能赶紧离开城市。
约翰·格朗特(John Graunt)原本是布商,不是大学教授。他却盯上了这些周周发布的死亡数字。他把多年死亡清单收集起来,认真整理、比较,写成了 1662 年的《基于死亡清单的自然与政治观察》。他关心的问题很具体:伦敦到底大约有多少人?男孩和女孩出生比例怎样?哪些死因常见,哪些可能被误记?某些疾病的数字突然变多,是疾病真的爆发,还是记录方式出了问题?
这件事厉害在哪里?
不是因为格朗特有一台显微镜,也不是因为他知道现代医学。厉害的是,他发现一堆“日常公告”可以变成理解城市的证据。单看一个人的死亡,是悲伤的个体事件;把很多人的死亡放在一起看,就会出现城市健康、人口变化和公共风险的轮廓。
这就是统计学从“账房工具”走向“公共知识”的关键一步。数字开始会说话,但前提是有人愿意把它们放在一起,耐心地问:这些记录背后,社会正在发生什么?
骰子、分奖金和概率:偶然也能讲道理¶
同一时期,还有一条线索来自游戏。
想象两个朋友玩一场掷骰子游戏,约好谁先赢到若干局,谁就拿走奖金。可游戏玩到一半,突然必须中断。这时奖金应该怎么分?

如果只看已经赢了几局,可能不公平;如果只说“各拿一半”,也不一定合理。真正的问题是:在当前局面下,双方接下来赢得整场比赛的机会分别有多大?
帕斯卡和费马讨论的“分赌注问题”,就把人们带向了概率思想。这里有一个很重要的转变:偶然不是不能讨论,偶然也有结构。我们不知道下一次骰子会掷出几点,但可以讨论很多次以后各结果出现的机会;我们不知道某个人明年是否生病,但可以研究一群人的风险。
统计学从此学会了一句非常现代的话:
我不知道下一次会怎样,但我可以认真估计许多次以后大概会怎样。
南丁格尔:她不只是“提灯的女士”¶
很多人知道南丁格尔(Florence Nightingale)是现代护理事业的重要人物,知道她在克里米亚战争中照顾伤员,被称为“提灯的女士”。但如果只记住这个形象,就会错过她最有力量的一面:她也是一位非常出色的数据传播者。
克里米亚战争期间,英军士兵大量死亡。普通人的直觉可能会以为,战场上死亡主要来自枪炮和伤口。南丁格尔整理数据后发现,许多死亡其实与拥挤、污水、通风差、卫生条件糟糕有关。也就是说,士兵不是只死于敌人,也死于可以改善的环境。
她真正厉害的地方,是没有把这些发现只写成厚厚的报告。她把数据画成醒目的图形,也就是后来常被称为“玫瑰图”或“极区图”的统计图。每一块扇形都像一片花瓣,花瓣大小告诉读者某类死亡原因有多严重。这样一来,不懂复杂表格的官员和公众,也能一眼看出问题。

这就是数据可视化的力量:它不是把数字变漂亮,而是把原本容易被忽视的痛苦变得难以回避。
南丁格尔后来成为英国皇家统计学会第一位女性会员。这个身份很有象征意义:统计学不只是数学家的玩具,它也可以是护士、改革者、公共卫生工作者手里的工具。她告诉我们,好的统计图不是装饰,而是一种公共表达:请看清事实,然后采取行动。
小率的理解
近代统计学像是从账本走向街道、医院和议会。它开始帮助人们讨论公共问题:城市是否安全,疾病怎样传播,战争伤亡能不能减少,制度有没有必要改变。
1.2.3 现代:用统计模型理解现实¶
进入现代,统计学又往前迈了一步。
古代统计问:“有多少?”
近代统计问:“这些数字说明了什么?”
现代统计开始问:“现实背后有没有一种可以理解的结构?我们能不能建立一个简化模型,帮助解释和预测?”
这里的“模型”不用想得太神秘。模型就像地图。地图不可能画出每一片树叶、每一块石头,但它能保留道路、方向和距离。统计模型也一样:它不复制整个世界,而是抓住最重要的关系。
高斯:误差不是噪音,而是可以理解的形状¶
高斯(Carl Friedrich Gauss)是数学史上非常耀眼的人物。他和统计学的关系,可以从一个日常问题讲起:同一个东西,为什么反复测量结果会不一样?
比如测一张桌子的长度。第一次是 120.1 厘米,第二次是 119.9 厘米,第三次是 120.0 厘米。是尺子坏了吗?不一定。现实中的测量总会有微小误差:眼睛读数、手的角度、工具精度、环境变化,都会让结果有一点浮动。
天文学和测地学里,这个问题更严重。观测星体位置、测量土地距离,误差不可避免。高斯等人研究误差时发现,许多测量误差并不是完全乱飞,而是经常围绕某个中心聚集:小误差常见,大误差少见,正负误差大致平衡。把它画出来,就像一口钟。这就是我们后来熟悉的正态分布(Normal Distribution),也常被称为“高斯分布”。
有趣的是,高斯和这条钟形曲线后来甚至登上了德国 10 马克纸币。纸币正面是高斯的肖像,旁边有哥廷根建筑和一条高斯曲线;背面则有测量仪器和测地网络。把数学家印在钞票上,本身就像一个文化隐喻:一个国家把“精确测量、科学理性、数学模型”当成值得纪念的财富。
这条曲线为什么重要?因为它让人们意识到,误差并不只是麻烦。只要误差有规律,我们就能估计真实值,评估不确定性,也能判断某个观测结果是不是异常。
身高、回归和“别被极端值骗了”¶
还有一个很适合初学者的故事,来自高尔顿(Francis Galton)研究身高。
他观察父母和孩子的身高,发现一个现象:很高的父母,孩子往往也偏高,但通常没有父母那么极端;很矮的父母,孩子往往偏矮,但也常常比父母更接近平均水平。这个现象后来和“回归到平均水平”联系在一起。
这不是说孩子一定会变普通,也不是说努力没有意义。它提醒我们:极端表现里常常混有偶然因素。一次考试特别高分,不代表以后每次都那么高;一次比赛发挥失常,也不代表真实水平就那么差。统计学让我们学会把“趋势”和“波动”分开看。
这条思想在生活里特别有用。看到某个产品本周销量暴涨,我们要问:是广告真的有效,还是刚好赶上节日?看到某个运动员上一场发挥神勇,我们要问:这是稳定实力,还是一次特别顺的状态?现代统计学训练我们的,不只是计算能力,还有一种不被单次极端结果带跑的冷静。
费舍尔和农田:比较要公平¶
再看一个农业实验的故事。
如果我们想知道某种肥料是否能提高小麦产量,最直觉的做法是:一块地用肥料,另一块地不用,然后比较收成。问题是,两块地可能本来就不一样。一块靠近水源,一块土壤贫瘠;一块阳光好,一块容易积水。最后产量不同,到底是肥料造成的,还是土地本来就不同?
费舍尔(R. A. Fisher)在英国罗斯汉姆斯特德农业试验站工作时,面对的就是这类问题。农业实验看似朴素,其实非常考验统计思想。要让比较公平,就要设计实验:把地块分组,尽量随机安排处理方式,重复观察,估计自然波动的大小。
这就是现代统计学非常重要的一课:
想知道一个因素有没有作用,不能只看结果差多少,还要看比较是否公平。
这个思想后来进入医学、心理学、工业、教育和互联网实验。今天我们讨论药物是否有效、教学方法是否更好、按钮颜色是否提高点击率,本质上都在继承这条线索:让比较尽量公平,让结论经得起怀疑。
彩票漏洞:统计学也会出现在便利店¶
现代统计学还有一些很“电影感”的故事。
美国有一对退休夫妻 Jerry 和 Marge Selbee,他们的故事后来被改编成 2022 年电影《Jerry & Marge Go Large》。故事的核心不是他们运气特别好,而是他们看懂了彩票规则里的一个统计漏洞。
当时有种彩票叫 WinFall 或 Cash WinFall。一般情况下,彩票当然是对玩家不利的:长期平均看,买票的钱会比奖金多。但这个游戏有一个特殊规则:如果头奖累积到某个水平还没人中,奖金不会继续全部滚入头奖,而会“下滚”到低等级奖项。也就是说,三等奖、四等奖等奖项的奖金会突然变大。
Jerry 发现,在这种“下滚周”里,如果买足够多的彩票,平均回报可能超过成本。注意,这不是保证每一张票都赚,也不是预测开奖号码,而是利用“期望值”变成正数。单张彩票仍然随机,但大量购买彩票后,随机波动会被摊平,规则本身的优势就显出来了。
这个故事很适合提醒初学者:
- 概率不是算命,它不告诉你下一张票会不会中。
- 期望值也不是保证,它说的是长期平均。
- 规则设计如果有漏洞,统计学能把漏洞照出来。
- “合法利用规则”和“公平感受”可能不是同一回事。
后来类似故事也引发监管关注,相关彩票游戏被停止或调整。统计学在这里像一盏灯:它照见的不只是中奖技巧,也照见制度设计里的不平衡。
均哥的小提醒
现代统计学最迷人的地方,是它既能解释天文观测误差,也能分析农田肥料;既能帮助公共卫生改革,也能看穿彩票规则。它不是远离生活的公式,而是理解现实的一套眼睛。
1.2.4 AI 与计算时代:人人都能处理海量数据¶
计算机出现后,统计学像换上了高速发动机。
过去一群人算很久的大表,今天一台电脑几秒钟就能处理。过去只能抽几百份问卷,今天手机、传感器、网站、医院系统、卫星和智能设备每天都在产生海量数据。统计学的任务也从“把表算完”,变成“从数据洪流里找出有用的模式”。
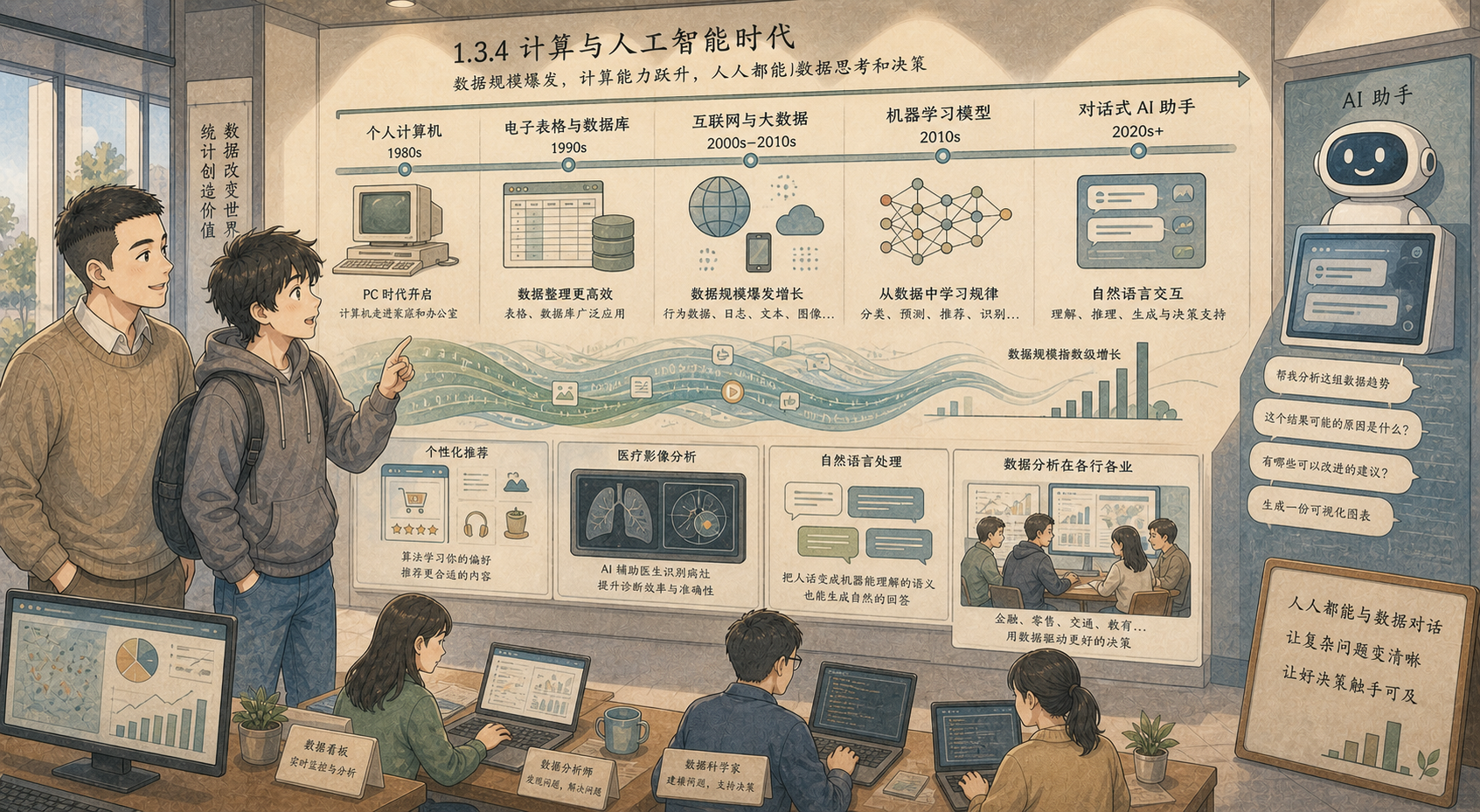
电子表格:普通人第一次摸到数据分析¶
在很长时间里,数据分析是专家的工作。你要会计算,要能操作大型机器,要有专门训练。
电子表格改变了这一点。一个小店老板可以记录每天卖出的奶茶口味,看周末和工作日有什么不同;一个学生可以记录复习时间和测验成绩,观察自己什么时候效率最高;一个家庭可以记录每月支出,发现外卖、交通、订阅服务到底花了多少钱。
电子表格让统计学从实验室和办公室里走出来,变成普通人也能使用的工具。它不一定高级,却很重要。因为很多数据素养,就是从“我把自己的记录整理成一张表”开始的。
机器学习:统计学换了一种更会计算的外衣¶
如果说电子表格让人更容易处理数据,那么机器学习(Machine Learning)则让计算机开始从数据中学习规律。
但机器学习并不是凭空冒出来的魔法。它和统计学是一脉相承的:统计学关心“从已经看到的数据里找规律,并判断这个规律靠不靠谱”;机器学习关心“让计算机从大量例子里自动找规律,并把规律用于新情况”。两者的共同底座,仍然是数据、误差、比较、预测和不确定性。
举个最简单的例子:如果我们让电脑根据房屋面积、楼层、位置来估计房价,电脑一开始可能猜得很离谱。它会把猜测结果和真实成交价比较,看看自己错了多少;然后调整内部规则,让下一次猜得更接近。这个过程听起来像机器在“学习”,其实背后仍然是统计学的老问题:
- 看到的数据能不能代表未来会遇到的情况?
- 模型是不是只记住了旧题答案,而没有学会真正规律?
- 预测错了多少,错得能不能接受?
- 换一批新数据,它还能表现好吗?
机器学习的很多关键词,换成统计学语言也很亲切:“训练”就是反复用数据调整规则;“损失”就是模型犯错的大小;“泛化”就是它遇到新情况时还能不能靠谱;“过拟合”就是把偶然细节当成规律记住了。
所以,这一段历史不是“统计学结束,机器学习开始”,而是统计学在计算机时代长出了新的枝条。
神经网络:从会学习的机器,到沉睡很久的想法¶
神经网络(Neural Network)的想法很早就出现了。1943 年,麦卡洛克和皮茨提出了人工神经元的逻辑模型;1950 年代,罗森布拉特提出感知机(Perceptron)。当时媒体对它非常兴奋,仿佛机器马上就要学会看、说、写,甚至拥有意识。
但早期神经网络能力有限。它能处理一些简单分类,却很难解决更复杂的问题。后来人们发现,单层感知机有明显边界,研究热情一度下降。这个阶段很像一个孩子刚学会走路,大家却期待他立刻跑马拉松,于是失望来得很快。
1980 年代,反向传播(Backpropagation)重新点燃了神经网络研究。你可以把它理解成一种“错了就往回找原因”的学习方法:模型先给出答案,和正确答案比较,看看错了多少;然后把错误一层层往回传,调整内部连接的权重。这个过程重复很多次,模型就可能慢慢学会更复杂的模式。
这里的“错了多少”非常统计学。它不是一句情绪化评价,而是一个可以计算的量。模型每次训练,都在尝试让这种错误变小。深度学习(Deep Learning)只是把这件事做得更深、更大:层数更多,参数更多,数据更多,能表达的模式也更复杂。
可是,想法有了,还不够。神经网络需要大量数据,也需要强大的计算能力。很长一段时间里,硬件和数据都跟不上,很多研究只能停在小规模实验。
深度学习爆发:数据、算力和算法终于碰头¶
到了 2010 年前后,三件事终于碰到一起:
- 互联网带来了大量图片、文字、语音和行为数据。
- GPU 等硬件让大规模计算变得可行。
- 神经网络训练技巧不断改进。
2012 年,AlexNet 在 ImageNet 图像识别竞赛中表现惊人,把深度学习推到聚光灯下。它不是第一个神经网络,却像一个响亮的信号:原来多层神经网络真的可以在大规模现实任务中取得巨大进步。
从那以后,图像识别、语音识别、机器翻译、推荐系统都迅速变化。手机相册能自动识别人脸,输入法能预测下一个词,地图能估计堵车时间,平台能推荐你可能喜欢的内容。这些功能背后,常常有统计学和机器学习的共同影子。
深度学习看起来很新,但它仍然离不开统计学的三件事:
- 用数据学习规律,而不是只靠人工写死规则。
- 用误差衡量模型哪里做得不好。
- 用新数据检验模型是否真的学会了,而不是只会背训练材料。
Transformer:让模型学会“看重点”¶
在自然语言处理里,早期模型处理句子常常像一个人从左到右逐字阅读。这样当然可以,但长句子、长文章、跨段关系会变得很难处理。
2017 年,Google 研究者发表论文《Attention Is All You Need》,提出 Transformer 架构。这里的核心词是注意力机制(Attention)。通俗地说,模型在处理一句话时,不是平均看每个词,而是学会判断“现在这个位置应该重点关注哪些词”。
比如“小率把书递给均哥,因为他要讲这一页”。要理解“他”指谁,模型需要回头看前面的词和关系。注意力机制让模型更灵活地建立词与词之间的联系。Transformer 还有一个重要优点:它更适合并行计算,可以利用现代硬件训练更大的模型。
这一步非常关键。后来的许多大语言模型,包括 GPT 系列,都建立在 Transformer 思想之上。
从统计学角度看,Transformer 仍然在做一件熟悉的事:根据上下文,估计接下来最可能出现什么。只是它面对的不是几十行表格,而是海量文本;它估计的不是一个简单数值,而是一长串可能词语的机会大小。
ChatGPT:数据分析从“写命令”变成“对话”¶
2022 年 11 月 30 日,OpenAI 发布 ChatGPT。它带来的震动,不只是因为模型会写文章、改代码、回答问题,而是因为它把复杂的 AI 能力包装成了普通人熟悉的形式:对话。
ChatGPT 背后的 GPT 模型,主要使用 Transformer 的解码器(decoder)部分。可以把 decoder 想成一个“接着往下说”的系统:给它前面的文字,它会估计下一个词、下一个片段、下一句话最可能是什么。训练时,它看过大量文本,每一步都在做类似这样的练习:
前面已经出现了这些字词,那么后面最可能接什么?
如果它猜错了,就调整内部参数;如果猜对的机会变高,就说明模型对语言模式掌握得更好。这里仍然是统计学的影子:根据已有信息估计未知结果,用错误大小推动改进,用大量例子让规律变得更稳定。
当然,大语言模型不只是“词语接龙”。当模型足够大、数据足够多、训练方式足够好时,它会表现出总结、改写、翻译、写代码、解释概念、辅助推理等能力。但这些能力的底层,仍然离不开“从数据中学习规律”这条统计学主线。
过去,一个人想让电脑分析数据,通常要知道软件、菜单、公式或编程语言。ChatGPT 这类对话式 AI 出现后,人们开始尝试直接说:
- “帮我解释这张表里发生了什么。”
- “把这些数据画成适合汇报的图。”
- “这段 Python 代码为什么报错?”
- “我这个实验设计有没有明显问题?”
- “这份调查结果能不能说明结论?”
这是一种很大的变化。AI 没有让统计学消失,反而把统计学问题带到更多人面前。以前很多人卡在“我不会写代码”,现在他们可能先从提问开始,再逐步学会数据、图表、模型和验证。
所以,ChatGPT 不是统计学的反面,而是统计学、计算机科学、语言学和工程实践长期汇合后的结果。它把“用数据学习规律”这件事,推到了普通人能直接对话使用的层面。
但均哥也提醒小率:“越是强大的工具,越需要清醒地使用。”
ChatGPT 这类模型可能生成听起来很流畅但并不正确的内容。它可能误解数据来源,可能忽略样本偏差,可能把相关说成因果,也可能给出看似合理但未经验证的解释。所以,在 AI 时代,统计学不是过时了,而是更重要了。
我们更需要会问:
- 数据从哪里来,收集过程可靠吗?
- 样本能代表我们关心的人群吗?
- 模型是在学习规律,还是记住了巧合?
- 结果有没有不确定性,误差大不大?
- 一个看起来漂亮的结论,能不能被新的数据验证?
- AI 给出的解释,有没有和真实证据对上?
从户部账册到 ChatGPT:同一个问题没有变¶
表面上看,古代户部和 ChatGPT 离得很远。一个面对的是户籍、田亩和粮仓,一个面对的是互联网文本、图像、代码和海量数据。
但它们背后的核心问题其实连在一起:
| 阶段 | 代表故事 | 统计学在做什么 |
|---|---|---|
| 古代 | 户籍、田亩、粮仓、赋税 | 把东西数清楚,让管理有凭据 |
| 近代 | 格朗特死亡清单、帕斯卡与费马、南丁格尔玫瑰图 | 用数据讲道理,让问题被看见 |
| 现代 | 高斯误差曲线、农田实验、彩票漏洞 | 用模型理解现实,让比较更公平 |
| AI 与计算时代 | 电子表格、机器学习、深度学习、Transformer、ChatGPT | 从海量数据中学习模式,辅助人类决策 |
小率的笔记本
统计学的历史,就是人类越来越会和数据相处的历史。先是把东西数清楚,再用数据讲道理,然后用模型理解现实,最后借助计算机和 AI 处理海量数据。工具一直在变,但最重要的问题没有变:证据可靠吗?比较公平吗?不确定性有多大?结论能帮助我们更好地理解世界吗?