9.4 实验设计基础¶
周末社区活动要做饼干义卖。小率想比较三种配方哪一种更受欢迎,可厨房里还有一个麻烦:上层烤架更热,下层烤架温度低一点。如果不提前设计,配方差异可能和烤架位置混在一起。

如果配方 A 都放上层,配方 C 都放下层,最后 A 更香,我是不是也不知道是配方好,还是上层烤得更好?
这就是实验设计要解决的事。好的 ANOVA 不是从软件开始,而是从数据怎么来开始。
9.4.1 三个原则:重复、随机化、区组¶
实验设计(Experimental Design)最核心的三件事是:
- 重复:每种处理做多次,估计自然波动。
- 随机化:随机安排处理顺序,减少系统偏差。
- 区组:把已知会影响结果的因素先分层,再在层内比较。
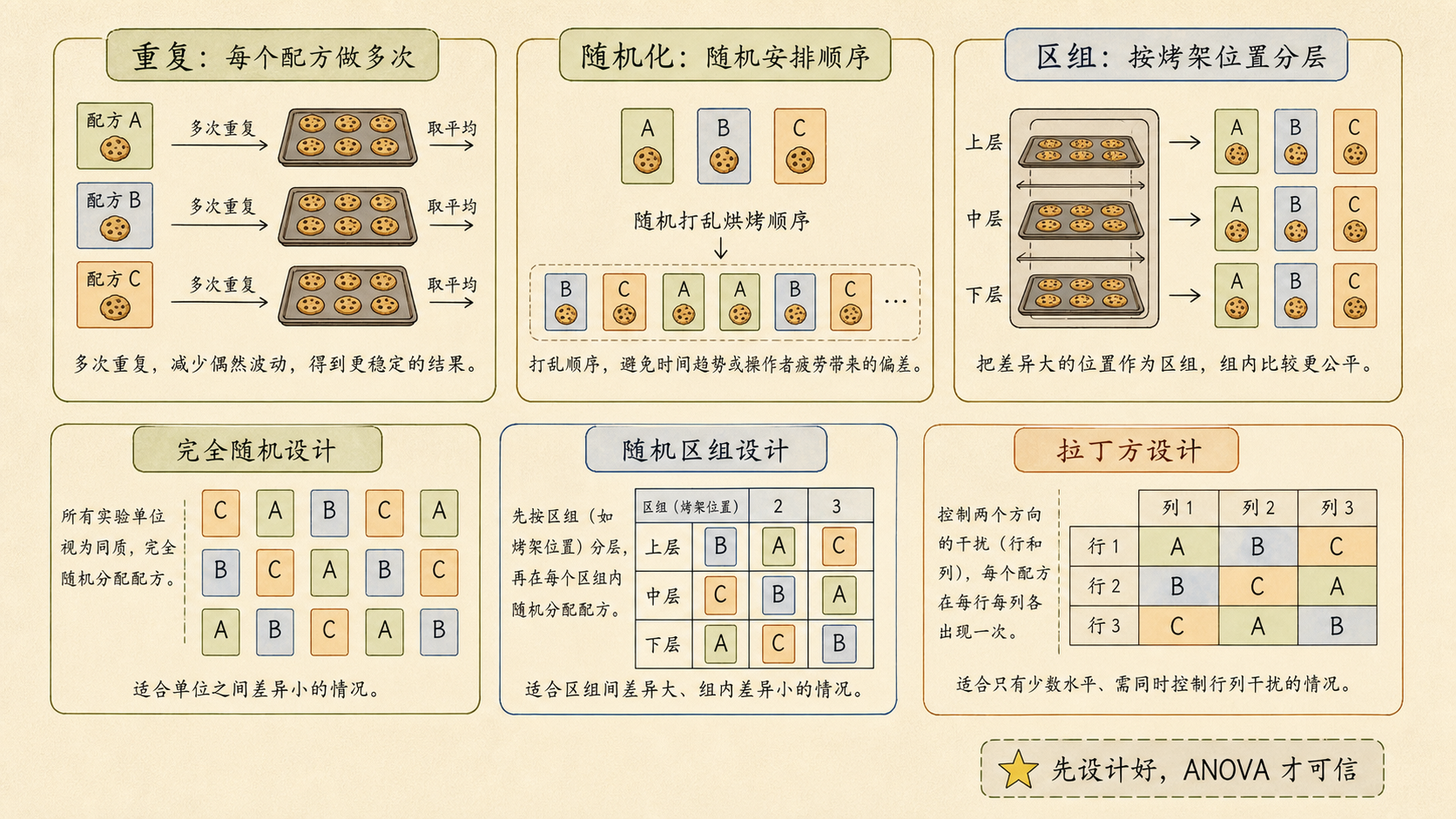
在饼干例子里,“配方”是我们关心的处理,“烤架位置”不是我们想研究的重点,却会影响结果。把烤架位置作为区组,可以让每种配方都在上、中、下层出现,比较更公平。
9.4.2 完全随机设计适合干扰少的场景¶
完全随机设计(Completely Randomized Design)把所有实验单位视为差不多,然后随机分配处理。
| 实验单位 | 随机分配的配方 |
|---|---|
| 第 1 盘 | B |
| 第 2 盘 | A |
| 第 3 盘 | C |
| 第 4 盘 | A |
| ... | ... |
它简单、直接,但前提是实验单位之间差异不大。若烤架位置、批次、操作者、时间段会明显影响结果,就要考虑区组或更复杂的设计。
9.4.3 随机区组设计把已知干扰先收起来¶
随机区组设计(Randomized Block Design)先按一个已知干扰因素分组,再在每个区组内随机安排处理。
| 烤架位置 | 第 1 次 | 第 2 次 | 第 3 次 |
|---|---|---|---|
| 上层 | A | C | B |
| 中层 | B | A | C |
| 下层 | C | B | A |
这样做的好处是:配方之间的比较不再被烤架位置强烈干扰。ANOVA 模型里也可以把“区组”作为一个解释项。
区组不是研究重点
区组通常是为了减少误差、提高检验效率。它可以被建模,但解释重点仍然是我们真正关心的处理因素。
9.4.4 实验前要写清楚分析计划¶
一个可靠的实验设计至少要提前写清楚:
- 研究问题:想比较什么?
- 实验单位:一盘饼干、一个同学、一次点击,哪个才是一行数据?
- 处理因素:哪些变量是主动安排的?
- 干扰因素:哪些变量会影响结果但不是研究重点?
- 随机化方案:如何随机分配?
- 主要检验:用哪种 ANOVA 或替代方法?
不要制造伪重复
如果同一盘饼干切成 10 块让 10 个人评分,这 10 个评分并不等于 10 个独立实验单位。真正独立的是“盘”还是“人”,要在设计阶段说清楚。
9.4.5 用 Python 比较是否加入区组¶
配套脚本放在:
核心代码如下:
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
df = pd.DataFrame({
"rack": ["上层", "中层", "下层"] * 3,
"recipe": ["A", "B", "C", "C", "A", "B", "B", "C", "A"],
"score": [88, 82, 79, 84, 86, 80, 83, 81, 87],
})
model = ols("score ~ C(recipe) + C(rack)", data=df).fit()
print(sm.stats.anova_lm(model, typ=2))
原来 ANOVA 的可信度,不只取决于公式,还取决于实验有没有设计好。
对。统计软件只能分析你给它的数据,不能替你修好一开始混乱的设计。
小率的笔记本
实验设计先于统计检验。重复用来估计误差,随机化用来减少系统偏差,区组用来控制已知干扰。ANOVA 表里的每一行,最好都能追溯到实验设计里的一个清楚安排。