6.3 极大似然估计¶
小率从口袋里摸出 10 张实验卡:7 张写着“正”,3 张写着“反”。这是他刚做的硬币实验。
他问均哥:如果这枚硬币正面朝上的概率是 \(p\),那看到“7 正 3 反”以后,最合理的 \(p\) 应该是多少?

哪个 p 最像这次数据
极大似然估计(Maximum Likelihood Estimation, MLE)的核心不是“参数给定后数据会怎样”,而是“数据已经发生后,哪个参数最能解释它”。
6.3.1 概率和似然只是视角不同¶
先看概率。若参数 \(p\) 已知,比如 \(p=0.5\),我们可以问:
抛 10 次,出现 7 正 3 反的概率是多少?
这时变量是“数据”。
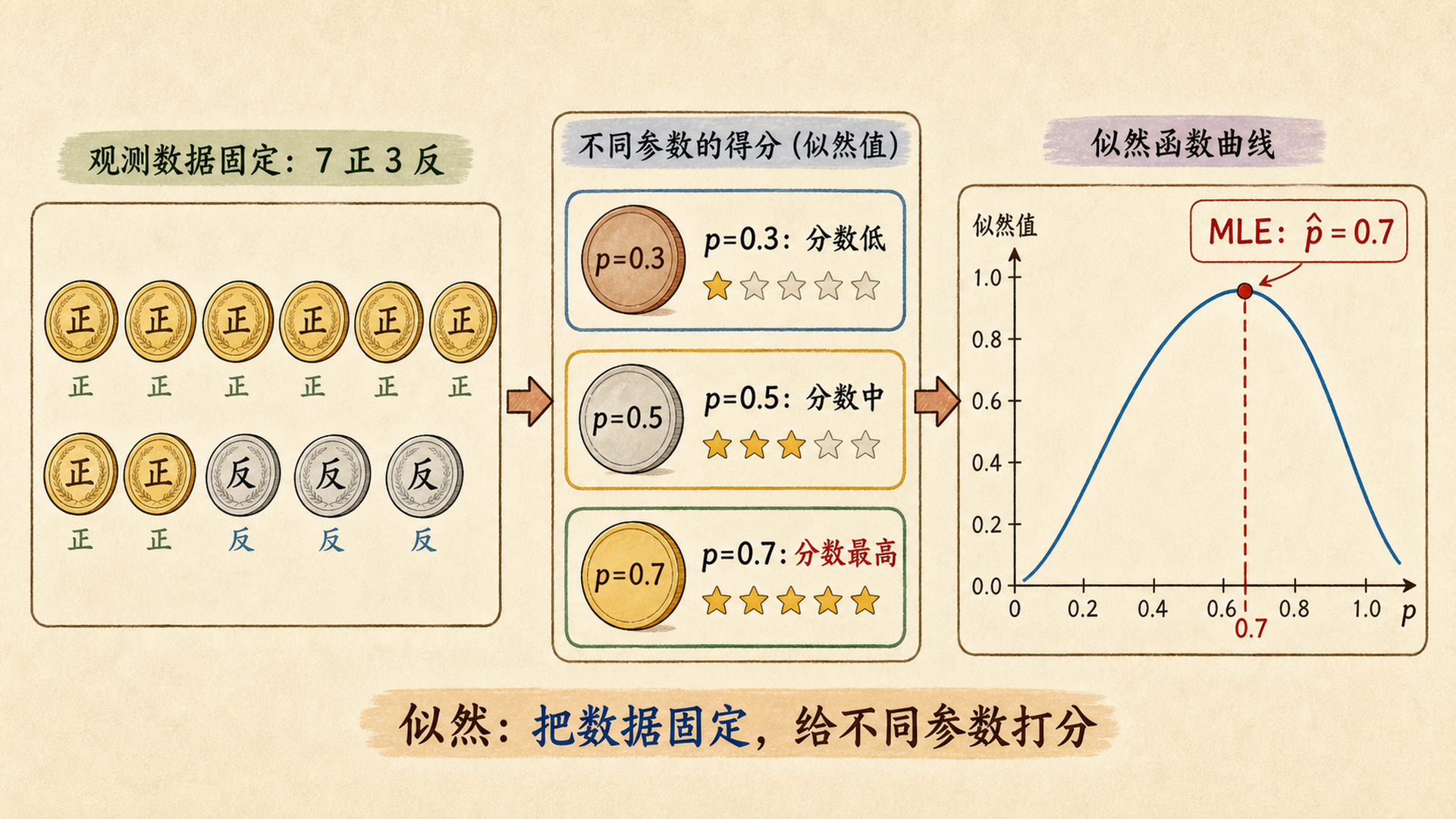
现在反过来。数据已经固定为 7 正 3 反,我们把 \(p\) 当成候选值,一个一个评分:
- \(p=0.3\):很难解释 7 次正面,分数低。
- \(p=0.5\):还能解释,分数中等。
- \(p=0.7\):最符合这次结果,分数最高。
这种把数据固定、给参数打分的函数,就是 似然函数(Likelihood Function)。
概率 vs 似然
概率是 \(P(\text{数据}\mid\text{参数})\),把参数当已知,问数据会不会出现。似然是 \(L(\text{参数}\mid\text{数据})\),把数据当已知,问哪个参数更像。
6.3.2 伯努利例子:7 正 3 反¶
把正面记为 1,反面记为 0。若 \(X_i\sim\operatorname{Bernoulli}(p)\),10 次里有 \(k=7\) 次正面,那么似然函数是:
代入 \(n=10,k=7\):
为了方便求最大值,常取对数:
对 \(p\) 求导并令其为 0:
解得:
6.3.3 MLE 的四步套路¶
多数模型都可以按同一套路走:
- 写出单个观测的概率或密度 \(f(x_i\mid\theta)\)。
- 假设样本独立,把它们相乘得到似然:
- 取对数,把乘法变加法:
- 找到让 \(\ell(\theta)\) 最大的参数:
为什么常用对数似然
对数函数单调递增,所以最大化 \(L(\theta)\) 和最大化 \(\ell(\theta)=\log L(\theta)\) 的位置相同。取对数后,乘积变成求和,数值也更稳定。
6.3.4 正态和泊松也能套同一招¶
如果 \(X_i\sim N(\mu,\sigma^2)\),极大似然估计会给出:
以及
注意这里方差分母是 \(n\),不是 \(n-1\)。这说明 MLE 并不保证无偏,它追求的是“让观测数据最像”的参数。
如果 \(X_i\sim \operatorname{Poisson}(\lambda)\),极大似然估计是:
6.3.5 用 Python 画出 7 正 3 反的似然¶
import numpy as np
n = 10
k = 7
p_grid = np.linspace(0.01, 0.99, 99)
log_likelihood = k * np.log(p_grid) + (n - k) * np.log(1 - p_grid)
p_hat = p_grid[np.argmax(log_likelihood)]
print(f"MLE p̂ = {p_hat:.2f}")
完整脚本见:
模型设错,MLE 也会跟着错
MLE 很强,但它依赖你先写出一个合理的概率模型。若硬币实验不是独立的,或者数据来自完全不同机制,再漂亮的似然最大化也会给出误导性的答案。
小率的笔记本
MLE 的核心是:把数据固定,给不同参数打分,选择分数最高的参数。概率看 \(P(\text{数据}\mid\text{参数})\),似然看 \(L(\text{参数}\mid\text{数据})\)。常用流程是写似然、取对数、求最大值。