10.2 先验、似然与后验¶
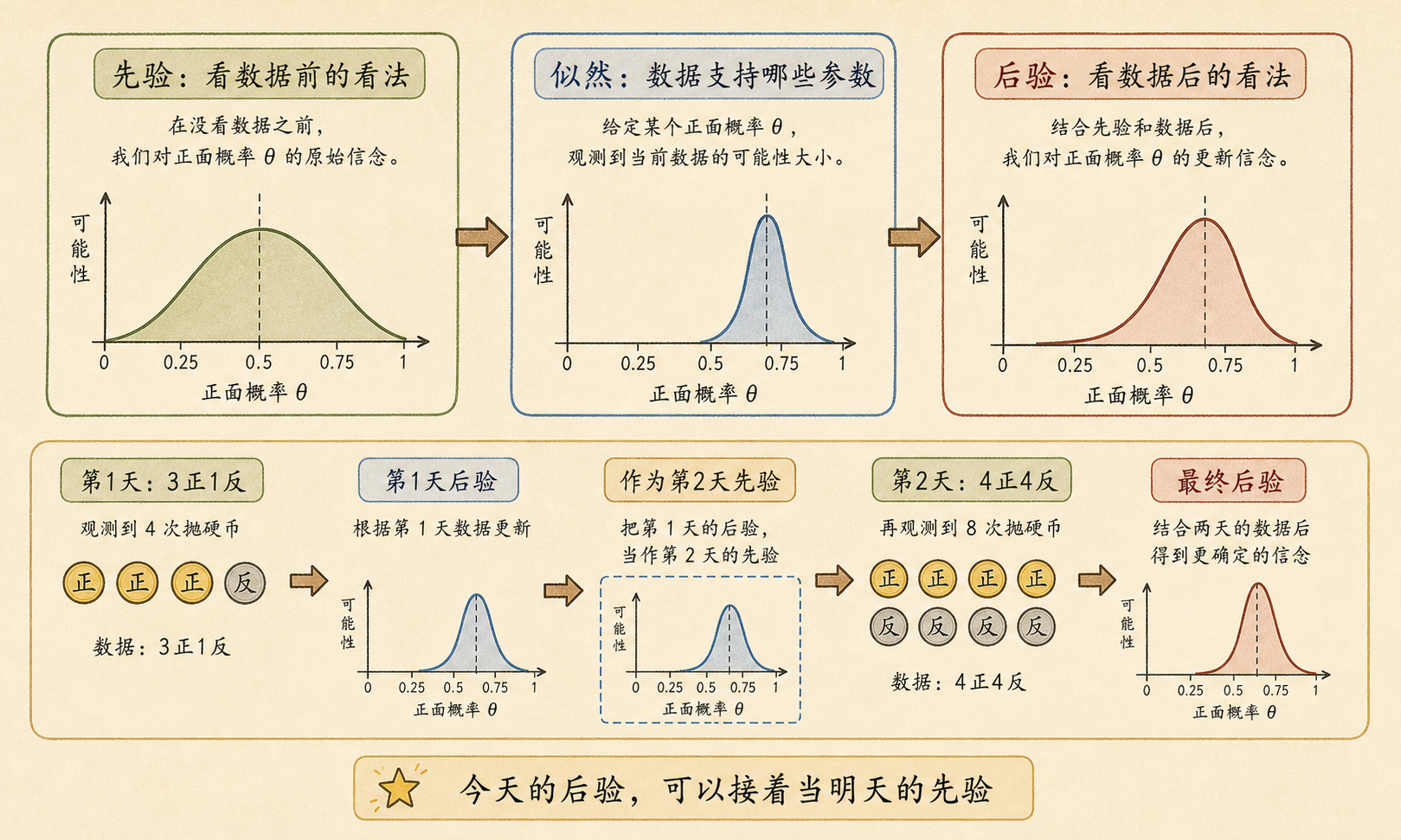
第二天,小率又带来了新记录。第一天抛了 4 次,3 正 1 反;第二天抛了 8 次,4 正 4 反。他的问题变得更实际:每天都有新数据时,难道要从头重算一遍吗?

| 批次 | 正面 | 反面 |
|---|---|---|
| 第 1 天 | 3 | 1 |
| 第 2 天 | 4 | 4 |
昨天算完了后验,今天又来了数据。我要把昨天的数据翻出来一起重算吗?
不用。贝叶斯最漂亮的一点就是:今天的后验,可以直接当明天的先验。
10.2.1 三个分布各管一件事¶
贝叶斯公式里最容易混的就是三件套:
| 名称 | 符号 | 负责的问题 |
|---|---|---|
| 先验 Prior | \(P(\theta)\) | 看数据前,我怎么想? |
| 似然 Likelihood | \(P(D\mid\theta)\) | 如果参数是这个值,数据有多合理? |
| 后验 Posterior | \(P(\theta\mid D)\) | 看完数据后,我该怎么想? |
| 证据 Evidence | \(P(D)\) | 用来把后验归一化 |
贝叶斯公式写成:
\[
P(\theta \mid D)=\frac{P(D\mid\theta)P(\theta)}{P(D)}
\]
实际理解时先抓住比例关系:
\[
P(\theta \mid D)\propto P(D\mid\theta)P(\theta)
\]
10.2.2 后验是先验和似然的合力¶
如果先验很宽,说明你原来没有太强看法,数据就更容易主导后验。如果先验很窄,说明你原来很确信,少量数据不容易把它拉走。
似然不是参数的概率
似然把数据当作已经观察到的事实,比较不同参数对这批数据的解释力。它通常不对参数积分为 1,所以不要把似然直接叫作“参数的概率分布”。
在硬币问题里,若先验是:
\[
p\sim \text{Beta}(2,2)
\]
第一天观察到 3 正 1 反,后验是:
\[
p\mid D_1\sim \text{Beta}(2+3,2+1)=\text{Beta}(5,3)
\]
这就是 Beta-Binomial 的便利之处:成功次数加到第一个参数,失败次数加到第二个参数。
10.2.3 顺序更新不用从头开始¶
第二天又观察到 4 正 4 反。我们可以把第一天的后验当作第二天的先验:
\[
\text{Beta}(5,3)+4\text{ 正}+4\text{ 反}
=\text{Beta}(9,7)
\]
如果把两天合并起来一次算:
\[
\text{Beta}(2+7,2+5)=\text{Beta}(9,7)
\]
结果完全一样。
分批更新和一次合并竟然一样?
是的。只要模型一致,贝叶斯更新天然支持“接力”。
10.2.4 先验可以强,也可以弱¶
不同先验表达不同信息量:
| 先验类型 | 例子 | 含义 |
|---|---|---|
| 弱信息先验 | Beta(2, 2) | 大概觉得硬币公平,但允许数据改变看法 |
| 平坦先验 | Beta(1, 1) | 0 到 1 之间都差不多可能 |
| 强信息先验 | Beta(50, 50) | 非常相信硬币接近公平 |
| 偏向先验 | Beta(8, 2) | 事前相信正面概率偏高 |
强先验不是不能用,但要能解释来源。比如来自长期历史数据、物理机制、前期实验,才比较站得住。
敏感性分析
重要结论最好换几个合理先验再跑一次。如果后验结论变化很大,说明当前数据还不足以压过先验,报告时要诚实说明。
10.2.5 用 Python 演示两天接力¶
配套脚本放在:
from scipy import stats
a, b = 2, 2
for day, heads, tails in [("第1天", 3, 1), ("第2天", 4, 4)]:
a += heads
b += tails
mean = a / (a + b)
lo, hi = stats.beta.ppf([0.025, 0.975], a, b)
print(day, f"后验 Beta({a},{b})", f"均值={mean:.3f}", f"95% CrI=({lo:.3f},{hi:.3f})")
小率的笔记本
先验回答“数据前怎么想”,似然回答“数据支持哪些参数”,后验回答“数据后怎么想”。贝叶斯更新可以分批接力:上一批数据得到的后验,可以直接作为下一批数据的先验。