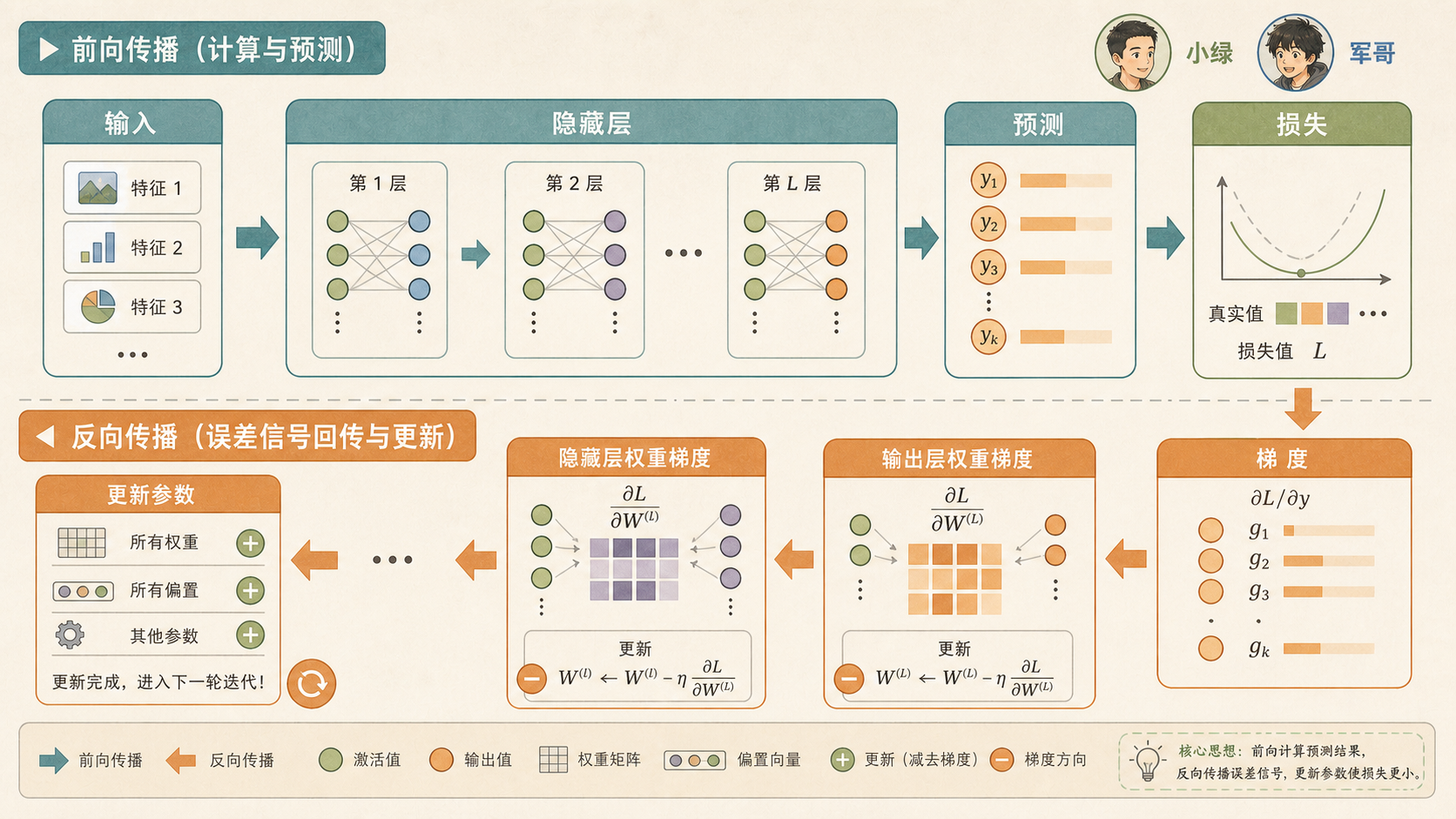
15.1 神经网络基础¶
下午,小率把一盒彩色弹珠倒在桌上,想做一个“自动分拣机”:蓝色弹珠进蓝盒,橙色弹珠进橙盒,混合颜色再看大小和轨道方向。均哥没有急着讲公式,只是把几层木块轨道搭起来:第一层看颜色,第二层看大小,第三层把前两层的判断合起来。
“这有点像模型在一层层处理信息。”小率说。
“对,”均哥点头,“神经网络(Neural Network)就是很多简单计算单元连在一起。单个单元不神奇,层层组合以后,函数就变得很灵活。”

15.1.1 一个神经元先做加权打分¶
先看最小的零件:神经元(Neuron)。它接收几个输入,把每个输入乘以一个权重(Weight),再加上偏置(Bias),得到一个分数。
如果写成向量形式,就是:
这里的直觉很朴素:权重大,说明这个特征更影响判断;偏置像默认门槛,让模型不用每次都从零开始。
| 弹珠特征 | 数值 | 权重 | 贡献 |
|---|---|---|---|
| 蓝色程度 | 0.9 | 2.0 | 1.8 |
| 大小 | 0.4 | 0.5 | 0.2 |
| 轨道速度 | 0.7 | -0.8 | -0.56 |
若偏置 \(b=-0.3\),则 \(z=1.8+0.2-0.56-0.3=1.14\)。分数是正的,模型倾向于把它送往“蓝盒”。
15.1.2 多层网络把简单判断组合起来¶
一层神经元只能做一批加权打分。深度网络(Deep Network)的关键,是把上一层的输出继续交给下一层。
其中 \(g\) 是激活函数(Activation Function),负责加入非线性;\(f\) 是输出层函数,分类任务常用 Softmax,回归任务可以直接输出数值。
均哥的小提醒
如果中间层没有激活函数,多层线性变换仍然等价于一层线性变换。深度学习真正的表达力,来自“线性变换 + 非线性激活”的反复组合。
15.1.3 用 Python 搭一个最小前向传播¶
下面不用任何深度学习框架,只用 NumPy 算一次前向传播。
import numpy as np
x = np.array([0.9, 0.4, 0.7])
W1 = np.array([
[1.2, -0.3, 0.8],
[-0.5, 1.1, 0.2],
])
b1 = np.array([0.1, -0.2])
W2 = np.array([[1.5, -0.7]])
b2 = np.array([0.05])
def relu(z):
return np.maximum(z, 0)
h = relu(W1 @ x + b1)
score = W2 @ h + b2
prob = 1 / (1 + np.exp(-score))
print("hidden:", h)
print("blue-box probability:", float(prob))
输出的概率不是“真理”,而是当前参数下的判断。训练就是让参数不断改,让判断越来越接近真实标签。
小率的笔记本
神经网络先把输入做加权求和,再通过激活函数产生中间表示。多层网络不是因为“层数多”才聪明,而是因为每一层都能把上一层的表示重新组合,逐渐形成更适合任务的特征。