6.2 估计量的性质¶
小率把奶茶等待时间的样本均值算出来后,又翻到作业里另一道题:样本方差到底该除 \(n\),还是除 \(n-1\)?
他把两张便签贴在桌上,一张写“除 \(n\)”,一张写“除 \(n-1\)”。均哥没有直接给答案,而是拿出几张靶纸:先看一把“估计的枪”打得准不准。

两个公式都能算,凭什么选一个
估计量不是“能算出数”就够了。统计学通常从 无偏性(Unbiasedness)、有效性(Efficiency)、一致性(Consistency) 和 均方误差(Mean Squared Error, MSE) 四个角度评价它。
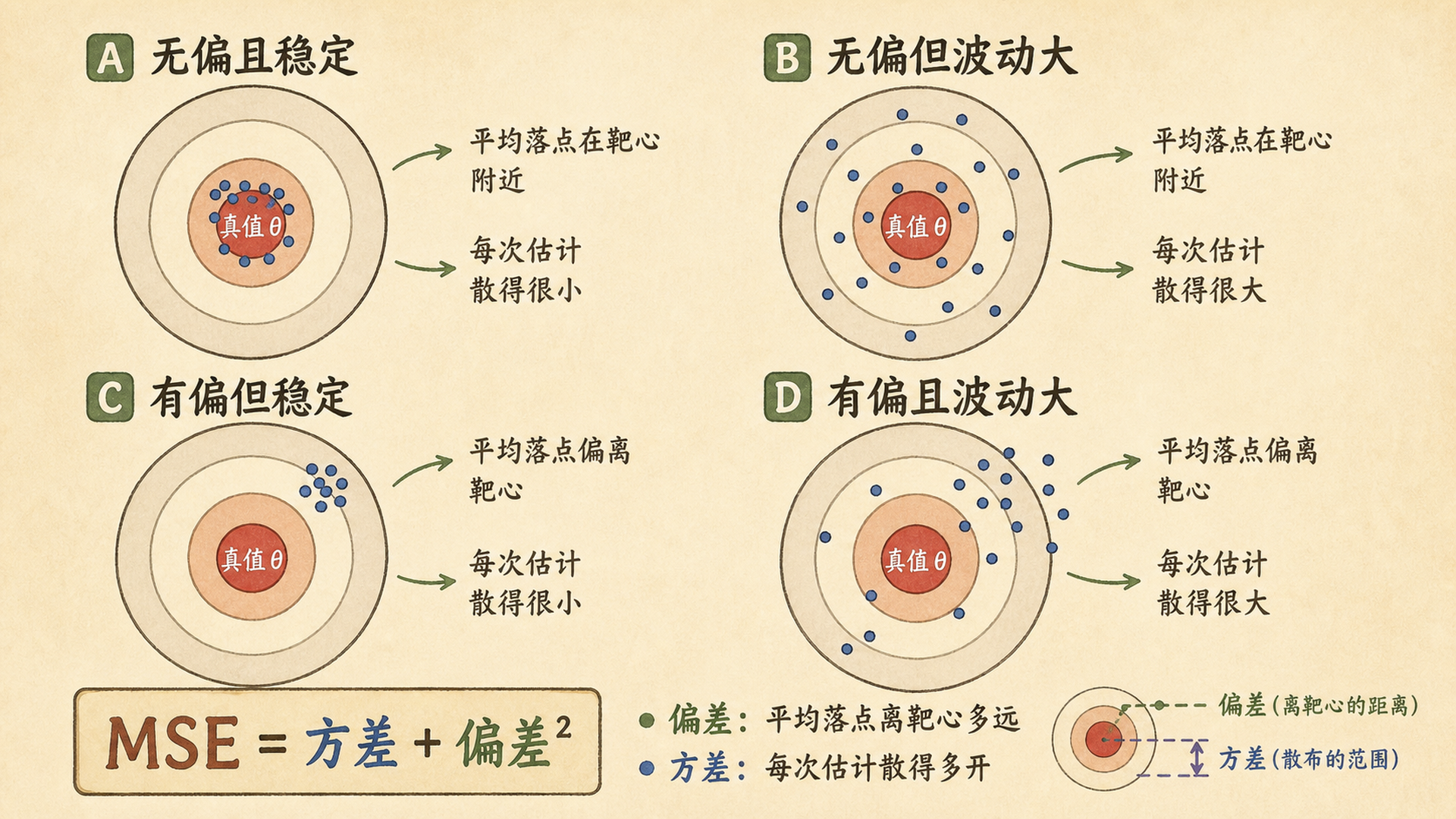
6.2.1 无偏:平均落点不偏离靶心¶
如果重复抽样很多次,每次都算一个估计值。把这些估计值看成靶纸上的落点,真值 \(\theta\) 就是靶心。
当估计量的平均落点正好在靶心时,我们说它是 无偏估计量(Unbiased Estimator):
例如样本均值满足:
所以 \(\bar X\) 是总体均值 \(\mu\) 的无偏估计量。
6.2.2 方差:落点散得多开¶
只看平均落点还不够。两把枪都可能平均命中靶心,但一把很集中,另一把到处乱飞。
估计量的方差描述它每次抽样时抖动有多大:
如果两个估计量都无偏,方差更小的那个通常更 有效(Efficient)。
一句话判断
偏差看“中心离靶心多远”,方差看“落点散得多开”。一个估计量可能不偏但很抖,也可能有点偏但很稳定。
6.2.3 MSE:把偏差和方差合成一个分数¶
如果只追求无偏,可能会接受很大的波动;如果只追求稳定,又可能接受系统性偏差。于是我们需要一个综合指标:均方误差(Mean Squared Error, MSE)。
其中:
6.2.4 样本方差为什么常除 n−1¶
设总体方差是 \(\sigma^2\)。两个常见估计量是:
和
关键事实是:
所以 \(S_n^2\) 会系统性低估总体方差。把分母从 \(n\) 改成 \(n-1\) 后:
这就是 贝塞尔修正(Bessel's Correction)。
不要把 n−1 当成魔法
除 \(n-1\) 是为了让样本方差成为总体方差的无偏估计。它不是说样本里真的少了一个人,而是因为我们先用样本均值 \(\bar X\) 替代了未知的 \(\mu\),损失了一个自由度。
6.2.5 一致性:样本越多越靠近真值¶
估计量还要经得起大样本考验。若样本量 \(n\) 越来越大时,估计量越来越接近真值,就称它具有 一致性(Consistency):
样本均值的一致性来自大数定律:
6.2.6 用 Python 看 n 和 n−1 的差别¶
下面模拟一个真实方差为 4 的总体,重复抽样很多次,比较两种样本方差公式的平均值。
import numpy as np
rng = np.random.default_rng(2026)
true_var = 4.0
n = 8
repeats = 20_000
var_n = []
var_n_minus_1 = []
for _ in range(repeats):
sample = rng.normal(loc=0, scale=true_var ** 0.5, size=n)
var_n.append(sample.var(ddof=0))
var_n_minus_1.append(sample.var(ddof=1))
print(f"真实方差 = {true_var:.2f}")
print(f"除 n 的平均估计 = {np.mean(var_n):.2f}")
print(f"除 n-1 的平均估计 = {np.mean(var_n_minus_1):.2f}")
完整脚本见:
小率的笔记本
无偏看平均落点,方差看落点散布,一致性看样本量增大后能否靠近真值。MSE 把偏差和方差合成一个分数:\(\operatorname{MSE}=\operatorname{Var}+\operatorname{Bias}^2\)。样本方差除 \(n-1\) 是为了无偏。