6.4 置信区间¶
小率又拿出一张班级奶茶偏好调查。50 位同学里,有 26 位选择“珍珠奶茶”,样本支持率是 52%。
他皱着眉说:“52% 听起来像多数,但如果再问 50 个人,会不会变成 48%?只给一个数太没底了。”

支持率 52% 到底稳不稳
点估计只给一个数,置信区间(Confidence Interval, CI)给一个范围。它回答的不是“真值有多大概率在这里”,而是“这种构造区间的方法,长期来看有多大比例能盖住真值”。
6.4.1 置信区间是随机的区间¶
假设总体真值是 \(\theta\)。每次抽样都会得到一个点估计,也会构造出一个区间:
置信水平为 \(1-\alpha\) 的区间满足:
这里随机的是 \(L(X)\) 和 \(U(X)\),不是 \(\theta\)。真值是固定的,只是我们看不见。
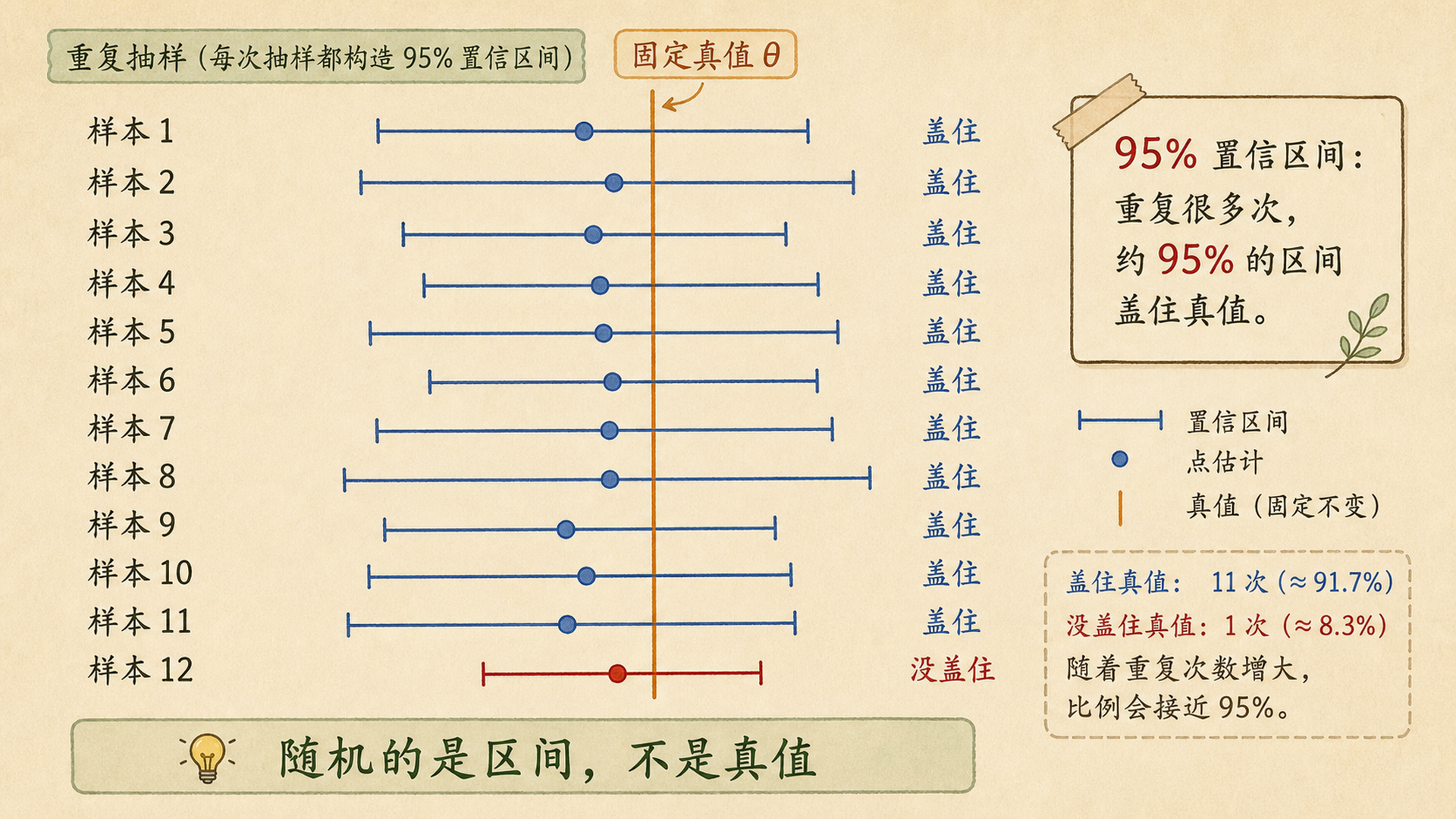
最常见误读
“95% CI 为 [0.42, 0.62]”不等于“真支持率有 95% 概率在 [0.42, 0.62]”。频率学派里真值固定,区间随机;这一次区间要么盖住真值,要么没盖住。
6.4.2 点估计 ± 临界值 × 标准误¶
大多数置信区间都有同一副骨架:
以均值为例,若总体标准差 \(\sigma\) 已知,由中心极限定理:
于是 95% 置信区间为:
更一般地写成:
| 置信水平 | \(z_{\alpha/2}\) |
|---|---|
| 90% | 1.645 |
| 95% | 1.960 |
| 99% | 2.576 |
模板记忆
临界值决定“想要多高把握”,标准误决定“点估计本身有多抖”。置信水平越高,临界值越大;样本量越大,标准误越小。
6.4.3 区间宽度不是免费午餐¶
区间半宽度是:
它由三件事控制:
| 因素 | 变大后区间怎样 |
|---|---|
| 总体波动 \(\sigma\) | 更宽 |
| 样本量 \(n\) | 更窄 |
| 置信水平 | 更宽 |
调查报告怎么写
比“支持率 52%”更完整的写法是:“根据 50 位同学样本,支持率点估计为 52%。在近似条件下,95% 置信区间约为 [38%, 66%]。”样本只有 50 人时,区间会很宽,这正是诚实表达不确定性。
6.4.4 Python 模拟覆盖率¶
下面模拟一个真均值为 10 的总体。重复抽样 200 次,每次构造 95% 区间,统计覆盖真值的比例。
import numpy as np
from scipy import stats
rng = np.random.default_rng(2026)
mu = 10
sigma = 2
n = 36
repeats = 200
z = stats.norm.ppf(0.975)
covered = 0
for _ in range(repeats):
sample = rng.normal(mu, sigma, n)
xbar = sample.mean()
margin = z * sigma / np.sqrt(n)
covered += (xbar - margin <= mu <= xbar + margin)
print(f"覆盖比例 = {covered / repeats:.3f}")
完整脚本见:
小率的笔记本
置信区间不是“真值随机落进去”,而是“区间构造方法长期有覆盖率”。大多数区间都可记成:点估计 ± 临界值 × 标准误。想要更窄的区间,通常要付出更多样本量。