4.1 随机变量¶
暑假下午,小率把几枚硬币倒在均哥桌上。硬币落下之前,谁也不知道会出现几次正面;可一旦把“正面次数”写下来,原本乱糟糟的结果就变成了一个可以计算的数字。

硬币实验要记录什么
抛 2 枚硬币时,样本空间里有 4 种结果;如果只关心“正面有几次”,就可以把每种结果映射成 0、1 或 2。
| 实验结果 | 正面次数 \(X\) |
|---|---|
| 反反 | 0 |
| 正反 | 1 |
| 反正 | 1 |
| 正正 | 2 |
4.1.1 从事件到数字¶
小率把硬币重新排了一遍。
第 3 章里我一直算事件概率。这里为什么突然开始写 $X=1$?
因为很多随机问题,最后要问的是一个数字,不是一句发生或没发生。
随机变量(Random Variable)不是“会随机乱变的变量”,而是一个函数:它把样本空间里的每个结果,映射到一个数字。
\[
\text{随机结果} \longrightarrow \text{数字}
\]
用字母写,就是:
\[
X:\Omega \rightarrow \mathbb{R}
\]
这里 \(\Omega\) 是样本空间,\(X\) 是我们定义的随机变量,\(\mathbb{R}\) 表示实数集合。
先问一句
看到随机问题时,先问:我要把每个结果记录成什么数字?这个数字就是随机变量。
4.1.2 同一个数字可能来自多个结果¶
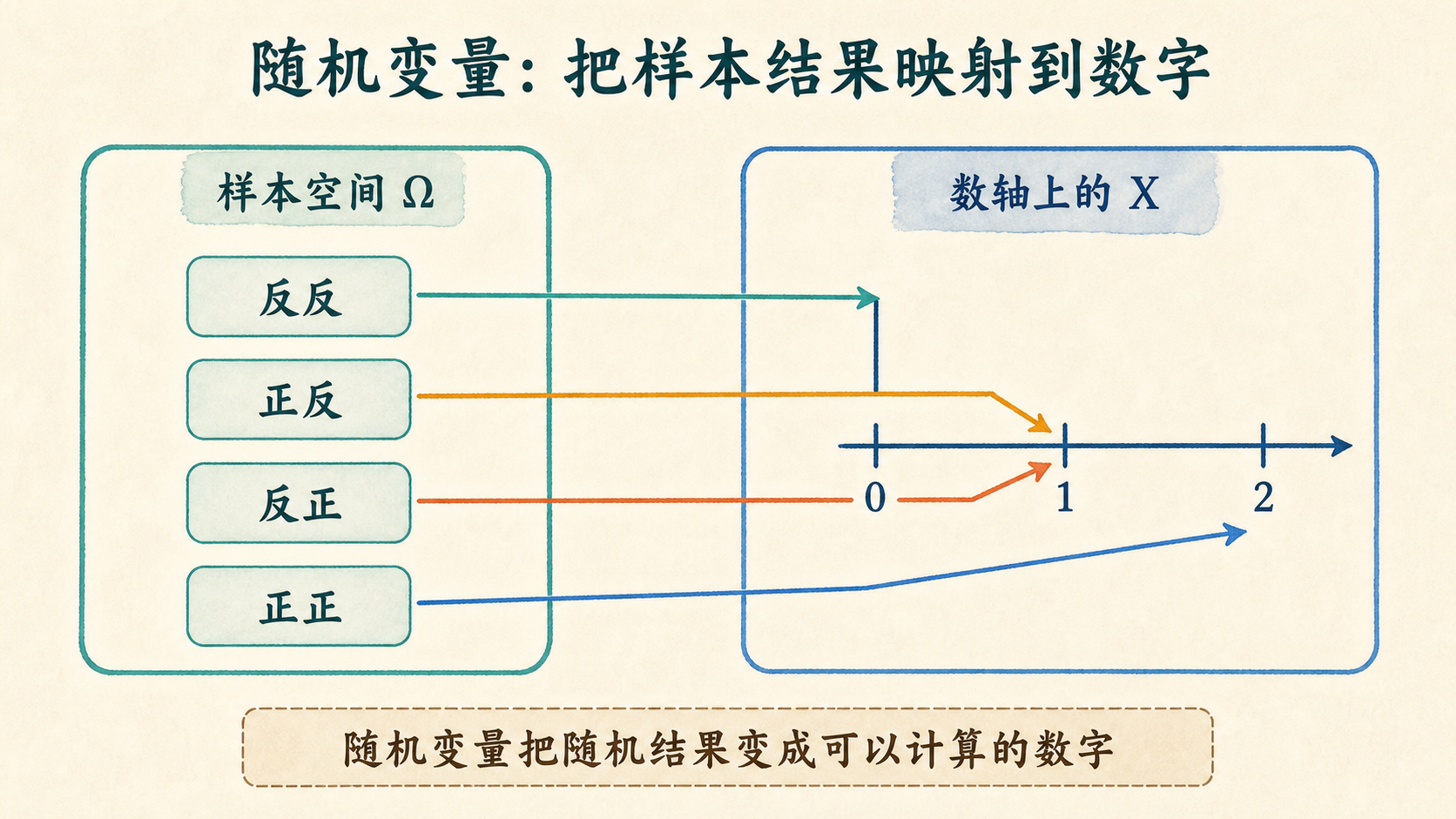
所以 $X=1$ 不是一个原始结果,而是一组结果的合并?
对。随机变量会把我们关心的信息保留下来,把不关心的细节压缩掉。
比如抛两枚硬币时,如果只关心正面次数,就不必区分“正反”和“反正”。这两个结果都贡献给事件 \(\{X=1\}\)。
\[
P(X=1)=P(\text{正反})+P(\text{反正})=\frac{1}{2}
\]
4.1.3 PMF 与 CDF 是两张说明书¶
随机变量定义好以后,我们还要描述它取不同值的概率。
离散随机变量常用概率质量函数(Probability Mass Function, PMF):
\[
p_X(x)=P(X=x)
\]
累积分布函数(Cumulative Distribution Function, CDF)则问“到这里为止的概率有多少”:
\[
F_X(x)=P(X\le x)
\]
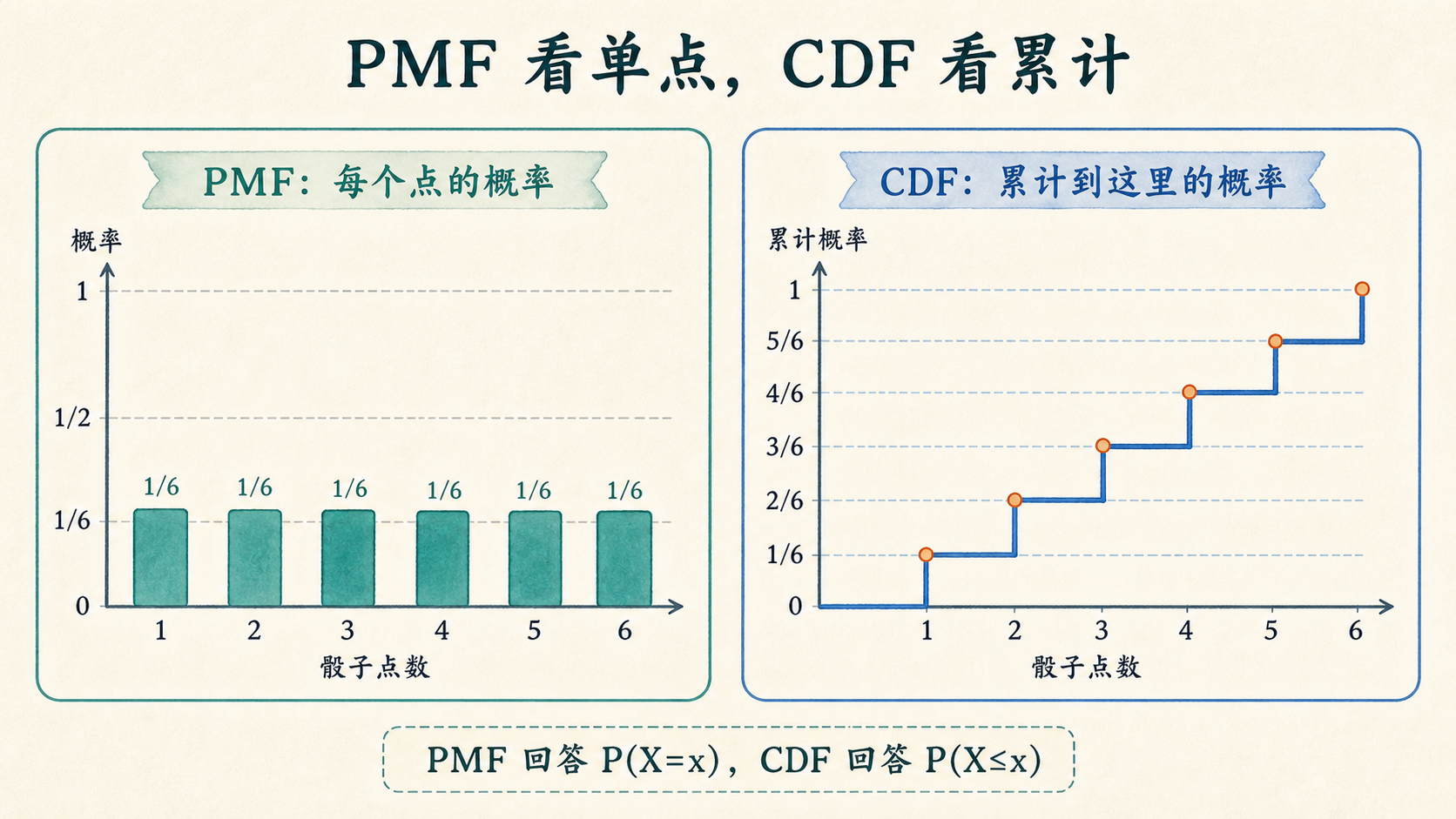
PMF 和 CDF 都描述分布,为什么要两张图?
PMF 适合看“某一点”,CDF 适合看“不超过某个值”。题目问法不同,工具也不同。
4.1.4 离散还是连续¶
随机变量大致分两类:
| 类型 | 典型问题 | 概率怎么读 |
|---|---|---|
| 离散随机变量 | 正面次数、来电数、答对题数 | 某个取值有概率 |
| 连续随机变量 | 等待时间、身高、温度 | 区间有概率 |
如果是“等公交几分钟”,好像不能列出所有可能值。
对,那就是连续随机变量。它通常不问恰好某个点,而问落在某个区间。
一个常见误读
连续随机变量里,\(P(X=168.5)\) 通常等于 0,并不表示“168.5 不可能出现”。它表示单个点没有面积;真正有意义的是 \(P(168.4<X<168.6)\) 这样的区间概率。
4.1.5 用 Python 看一眼分布¶
from scipy import stats
# 抛两枚公平硬币,X = 正面次数
dist = stats.binom(n=2, p=0.5)
for x in [0, 1, 2]:
print(f"P(X={x}) = {dist.pmf(x):.2f}")
print(f"P(X<=1) = {dist.cdf(1):.2f}")
输出会告诉你:
原来
pmf 问某个点,cdf 问累计到哪里。记住这句话,后面离散分布、连续分布都会反复用到。
小率的笔记本
- 随机变量是一个函数,把随机结果变成数字。
- 先定义 \(X\) 表示什么,再谈 \(P(X=x)\)。
- PMF 看某个取值的概率,CDF 看“不超过某个值”的概率。
- 离散变量可以数点,连续变量通常看区间。