4.8 联合分布与边际分布¶
小率把班级兴趣调查表递给均哥。表里不止一个问题:每位同学每周运动几次,睡眠质量又属于“好、中、差”哪一档。单独看运动频率是一回事,单独看睡眠质量也是一回事;但真正有意思的问题是:它们会不会一起变化?

班级调查要回答什么
如果只知道“运动频率”的分布,或只知道“睡眠质量”的分布,都还不够。我们还想知道:高运动频率是否更常和好睡眠一起出现?
4.8.1 一张表同时放两个变量¶
一个随机变量有自己的分布。那两个随机变量一起出现时,分布长什么样?
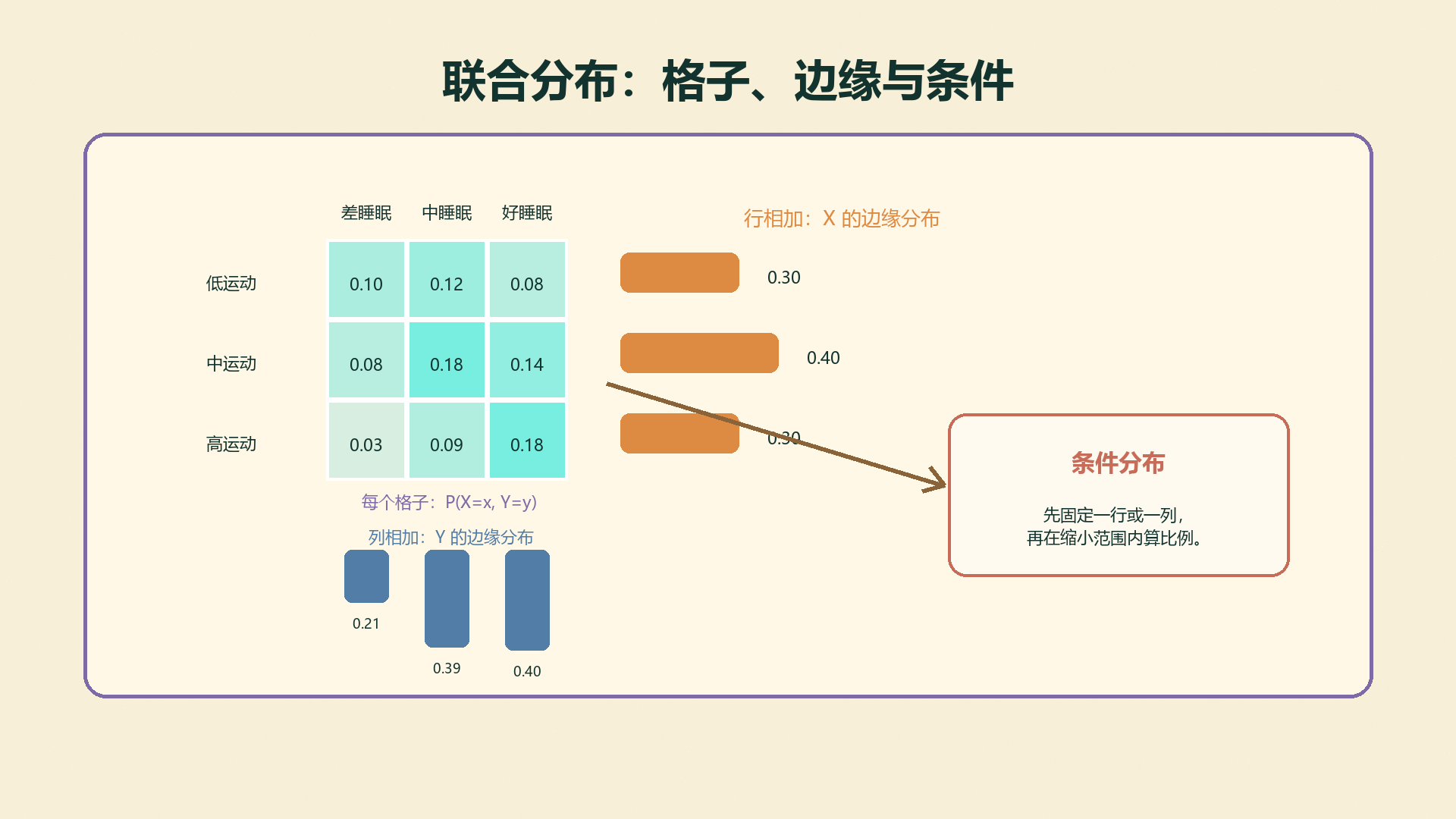
长成一张二维表。每个格子记录一对取值同时出现的概率。
联合分布(Joint Distribution)描述两个随机变量同时取值的概率:
\[
p_{X,Y}(x,y)=P(X=x,Y=y)
\]
例如 \(X\) 表示每周运动频率,\(Y\) 表示睡眠质量,一格可以表示:
\[
P(X=\text{高运动},Y=\text{好睡眠})
\]
4.8.2 联合表的热图¶
颜色最深的格子,就是最常一起出现的组合?
对。联合分布先看组合,再看组合背后的关系。
4.8.3 边缘分布:把另一边加掉¶
如果只想知道 \(X\) 的分布,就把所有 \(y\) 加起来:
\[
P(X=x)=\sum_y P(X=x,Y=y)
\]
如果只想知道 \(Y\) 的分布,就把所有 \(x\) 加起来:
\[
P(Y=y)=\sum_x P(X=x,Y=y)
\]
这叫边缘分布(Marginal Distribution),因为在二维表里,它常常写在表格边缘。
4.8.4 条件分布:先缩小范围¶
如果已经知道某个同学运动频率高,再问他睡眠质量好的概率,就进入条件分布:
\[
P(Y=y\mid X=x)=\frac{P(X=x,Y=y)}{P(X=x)}
\]
这和第 3 章条件概率是同一件事吗?
完全同一件事。只是现在事件写成了随机变量的取值。
读联合表的三步
先看格子:联合概率;再加边缘:单个变量分布;最后固定一行或一列:条件分布。
4.8.5 独立性:联合概率能不能拆开¶
如果两个随机变量独立,那么每个组合概率都能拆成两个边缘概率的乘积:
\[
P(X=x,Y=y)=P(X=x)P(Y=y)
\]
这表示知道 \(X\) 的取值,不会改变你对 \(Y\) 的判断。
相关和独立不是同一层概念
独立性要求所有组合都能拆开;相关性通常只描述线性同变关系。\(r=0\) 不一定代表独立,除非有额外分布条件。
4.8.6 多维期望¶
两个变量一起出现后,我们常常会关心函数 \(g(X,Y)\) 的平均值:
\[
E[g(X,Y)]=\sum_x\sum_y g(x,y)P(X=x,Y=y)
\]
例如 \(g(X,Y)\) 可以是“运动频率和睡眠质量的综合评分”,也可以是两个变量相乘 \(XY\)。
4.8.7 用 numpy 算边缘和条件¶
import numpy as np
# 行:运动频率 低/中/高;列:睡眠质量 差/中/好
joint = np.array([
[0.10, 0.12, 0.08],
[0.08, 0.18, 0.14],
[0.03, 0.09, 0.18],
])
px = joint.sum(axis=1)
py = joint.sum(axis=0)
print("运动频率边缘分布:", px.round(2))
print("睡眠质量边缘分布:", py.round(2))
# 已知运动频率高,睡眠质量好的概率
cond_good_given_high = joint[2, 2] / px[2]
print(f"P(好睡眠 | 高运动) = {cond_good_given_high:.2f}")
原来联合表就是一张可以求和、切片、做条件的概率表。
对。二维随机变量的很多题,本质都是在这张表里找格子、加边缘、算比例。
小率的笔记本
- 联合分布描述两个随机变量同时取值的概率。
- 边缘分布是把另一个变量加掉。
- 条件分布是先固定一个变量,再在缩小后的范围内看另一个变量。
- 独立意味着联合概率可以拆成边缘概率的乘积。
- 联合分布是理解协方差、相关性和多变量模型的入口。