6.7 自助法¶
小率现在已经会给均值和比例做区间了。但他又遇到一个新问题:社团记录了 30 位同学一周运动时长,分布明显右偏。小率不想估均值,而想估 中位数 的置信区间。
中位数不像均值那样有一个好背的标准误公式。怎么办?

没有现成公式,还能给区间吗
可以用 Bootstrap 方法(Bootstrap Method)。它把原始样本当作总体的替身,从样本中有放回地反复重抽样,用计算模拟统计量的抽样分布。
中位数、相关系数、分位数这些东西,难道每个都要推一个公式?
不一定。公式难推时,可以让电脑替我们重复抽样。
6.7.1 把样本当成总体的替身¶
Bootstrap 的步骤非常固定:
- 有一份原始样本 \(x_1,\ldots,x_n\)。
- 从这份样本中 有放回 抽 \(n\) 个值,得到一个 Bootstrap 样本。
- 在这个新样本上计算统计量,比如中位数。
- 重复很多次,得到一堆统计量 \(\hat\theta^*\)。
- 用这些 \(\hat\theta^*\) 的分布估计标准误和置信区间。
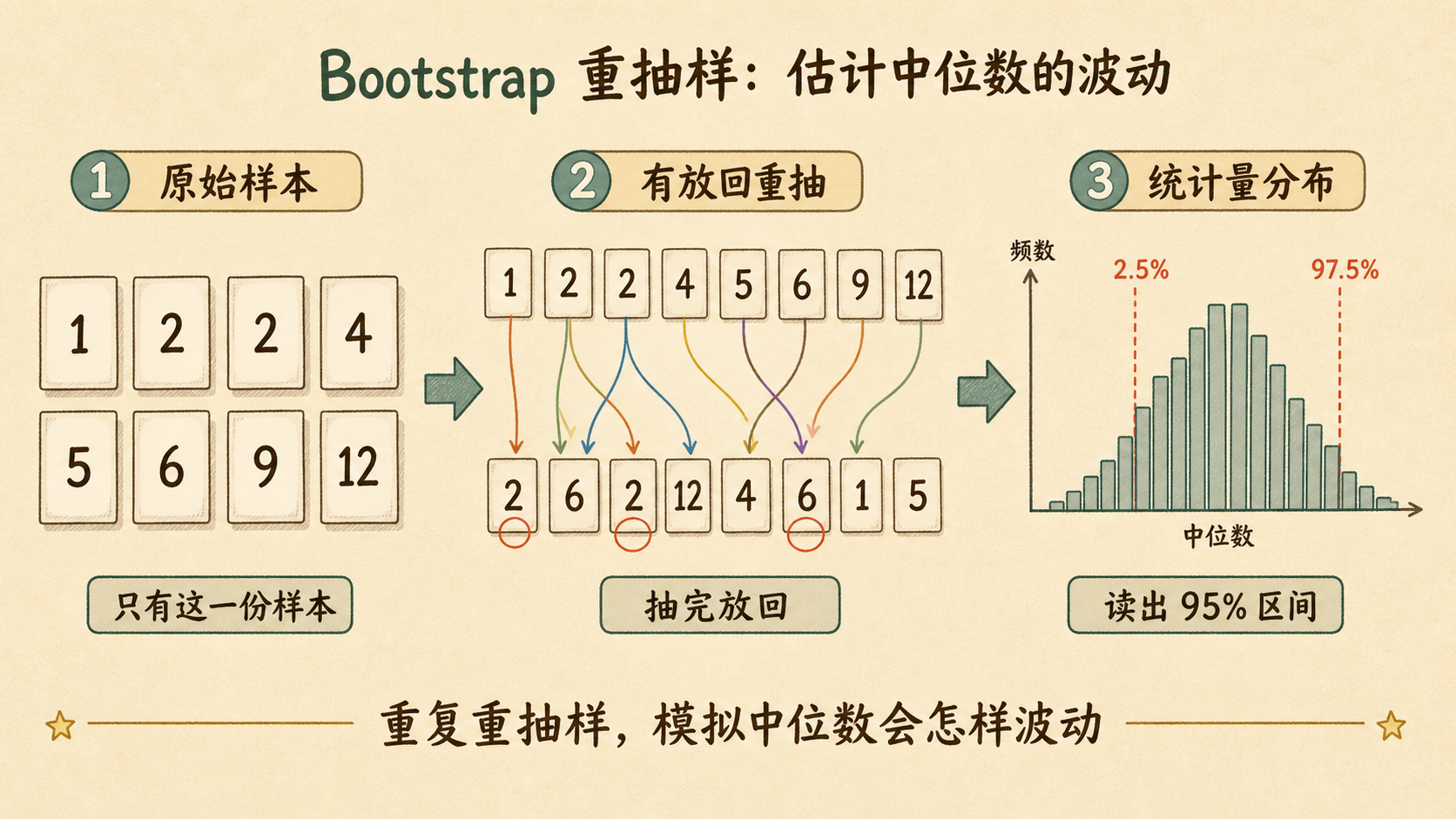
为什么要有放回
有放回抽样会让某些原始观测重复出现,另一些观测缺席。这样才能模拟“如果重新抽一次样本,统计量会怎么变”的随机性。
6.7.2 百分位区间最直观¶
若重复 \(B=5000\) 次,得到 5000 个 Bootstrap 中位数。把它们从小到大排序,取第 2.5% 和第 97.5% 分位数,就得到一个 95% Bootstrap 百分位区间:
\[
\left[
Q_{0.025}(\hat\theta^*),
Q_{0.975}(\hat\theta^*)
\right]
\]
这不需要正态假设,也不需要你推导中位数的标准误。
也就是说,区间直接从重抽样结果里读出来?
对。Bootstrap 的魅力就是用计算力换公式推导。
6.7.3 Bootstrap 不是万能按钮¶
Bootstrap 很通用,但不是无条件可靠。
适合:
- 均值、中位数、分位数、相关系数等常见统计量。
- 分布偏态、解析公式不方便时。
- 样本量不太小,原始样本能代表总体时。
谨慎:
- 极值,如最大值、最小值。
- 强时间依赖数据,如股价序列。
- 样本量极小,原样本本身很不代表总体。
时间序列不能随便打乱
普通 Bootstrap 会破坏时间顺序和相邻相关性。若数据是时间序列,要考虑 Block Bootstrap 等专门方法。
6.7.4 Python 给中位数做 Bootstrap 区间¶
import numpy as np
rng = np.random.default_rng(2026)
exercise_hours = rng.gamma(shape=2.0, scale=2.0, size=30)
B = 5000
boot_medians = []
for _ in range(B):
sample = rng.choice(exercise_hours, size=len(exercise_hours), replace=True)
boot_medians.append(np.median(sample))
lo, hi = np.percentile(boot_medians, [2.5, 97.5])
print(f"样本中位数 = {np.median(exercise_hours):.2f} 小时")
print(f"Bootstrap 95% CI = [{lo:.2f}, {hi:.2f}]")
完整脚本见:
小率的笔记本
Bootstrap 的核心是“从样本中有放回重抽样”。它适合公式难推、分布偏态或统计量复杂的场景。普通 Bootstrap 依赖原样本能代表总体,遇到极值、强时间依赖或极小样本时要谨慎。