15.8 小结¶
学完这一章,小率把桌上的卡片收进背包:神经网络像分层工具箱,激活函数像闸门,反向传播像配方反馈,CNN 像滑动观察窗,RNN/LSTM 像路线记忆卡,Transformer 像给每个词拉起关联线。
深度学习的知识很多,但主线并不乱:表示、预测、损失、梯度、更新。

15.8.1 本章主线可以压成五步¶
- 把输入表示成向量、矩阵或序列。
- 用网络结构逐层变换表示。
- 用输出层得到预测。
- 用损失函数衡量预测和真实答案的差距。
- 用反向传播和优化器更新参数。
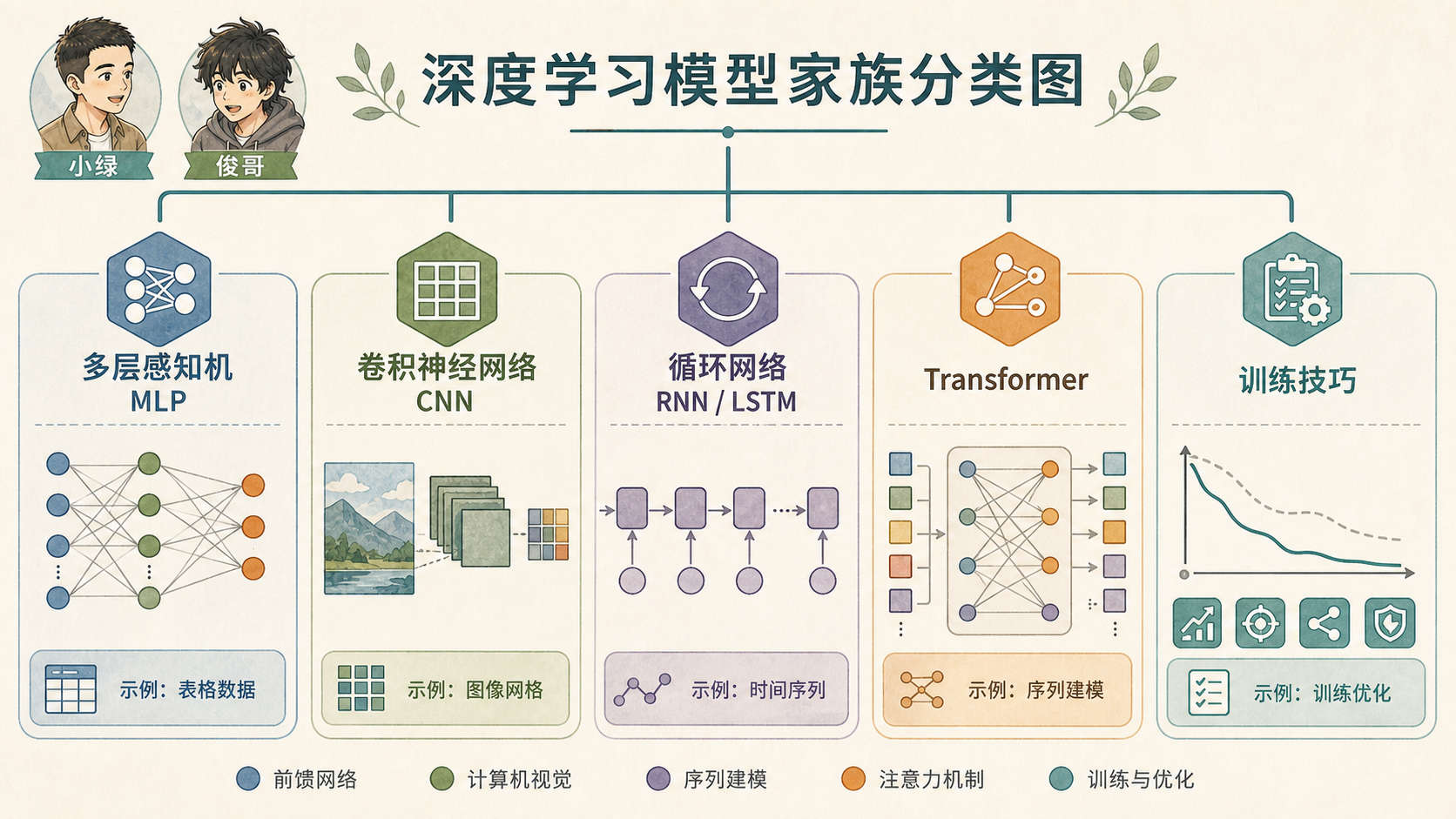
15.8.2 模型家族各有擅长场景¶
| 模型 | 最适合的直觉 | 常见任务 |
|---|---|---|
| MLP | 表格特征的层层组合 | 简单分类、回归、特征融合 |
| CNN | 局部窗口扫描图像 | 图像分类、检测、医学影像 |
| RNN/LSTM | 按顺序更新记忆 | 短序列、时间序列、早期 NLP |
| Transformer | 任意位置互相关注 | 语言模型、翻译、多模态 |
| 训练技巧 | 让模型稳定学起来 | 调参、泛化、部署前验证 |
15.8.3 几个容易混淆的点¶
不要把深度学习神秘化
神经网络本质上仍是参数化函数。它强大,是因为函数族足够灵活、数据足够多、优化方法足够成熟,而不是因为它跳出了统计学习的基本逻辑。
不要把训练损失当成最终成绩
训练集表现好,只说明模型在见过的数据上拟合得好。真正关心泛化时,要看验证集和测试集。
不要只背架构名字
CNN、LSTM、Transformer 不是标签,而是结构假设。先问数据有什么结构:空间邻近、时间顺序、长程依赖,还是多模态关系。
15.8.4 后续学习路线¶
建议按这个顺序继续走:
- 用 PyTorch 训练一个 MLP,完整记录训练/验证曲线。
- 用 CNN 做一个小图像分类任务。
- 用 LSTM 或一维 CNN 做一个短时间序列任务。
- 手写一个小型 self-attention。
- 阅读 Transformer 的编码器和解码器结构。
- 学习数据增强、正则化、学习率调度和模型评估。
15.8.5 练一练¶
练习 15.1
如果一个多层网络中所有激活函数都是线性的,它和单层线性模型有什么关系?
参考答案
多个线性变换复合后仍然是线性变换,因此整体等价于一个单层线性模型。非线性激活才让深度网络有更强表达力。
练习 15.2
为什么 Sigmoid 在深层网络中容易带来梯度消失?
参考答案
Sigmoid 两端很平,导数接近 0。反向传播时多个很小的导数相乘,早期层得到的梯度会迅速变小。
练习 15.3
反向传播和梯度下降分别负责什么?
参考答案
反向传播负责计算每个参数的梯度;梯度下降或 Adam 等优化器负责根据梯度更新参数。
练习 15.4
CNN 为什么比把整张图直接接全连接层更适合图像?
参考答案
CNN 利用局部连接和参数共享,能更高效地学习边缘、纹理和局部模式,也减少了参数量。
练习 15.5
LSTM 比普通 RNN 多出的关键设计是什么?
参考答案
LSTM 有细胞状态和门控机制,包括遗忘门、输入门和输出门,用来控制旧信息保留、新信息写入和当前输出。
练习 15.6
自注意力中的 Query、Key、Value 可以怎样直觉理解?
参考答案
Query 表示当前位置想找什么,Key 表示每个位置能提供什么线索,Value 表示被关注后真正传递的内容。
练习 15.7
新任务训练前,为什么建议先让一个小 batch 过拟合?
参考答案
如果模型连极小数据都背不下来,通常说明实现、数据、标签、损失或学习率有问题。先排除基础错误,再做大规模训练。
小率的笔记本
深度学习可以看作“可微函数 + 数据 + 优化”。先理解每个结构为什么适合某类数据,再学习更大的模型,会比直接背模型名字走得稳。