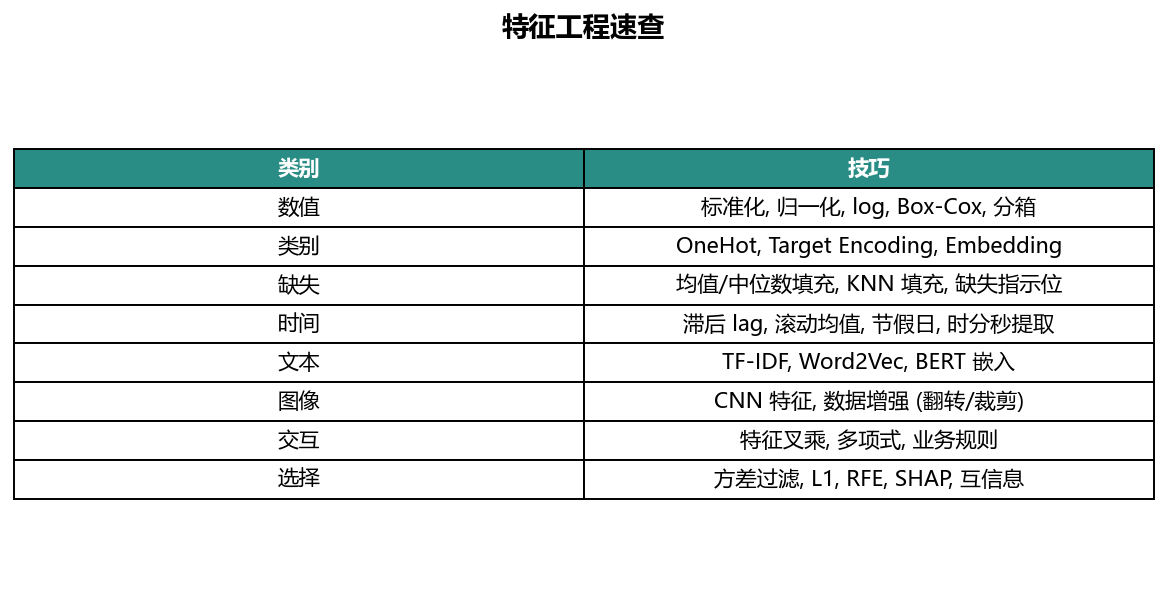
13.6 特征工程¶
小率把“年龄、通勤距离、过去 30 天活动次数、兴趣标签”直接喂给模型。结果模型几乎只盯着通勤距离,因为距离用米表示,数值动不动就是几千;兴趣分只有 0 到 1,像被淹没在表格里。
机器学习不是把原始表格原样倒进去就结束。把原始信息整理成模型能好好使用的变量,叫 特征工程(Feature Engineering)。
明明兴趣也很重要,为什么模型像没看见它?
因为你给模型的尺子不公平。数值范围大的特征会先把距离类模型牵走。
13.6.1 数值特征先摆正尺子¶
数值特征常见处理包括:
- 标准化(Standardization):减均值、除标准差。
- 归一化(Normalization):缩放到固定区间。
- 截尾(Winsorization):限制极端值影响。
- 对数变换(Log Transform):压缩长尾分布。
标准化公式是:
\[
z=\frac{x-\bar x}{s}
\]
其中 \(\bar x\) 是样本均值,\(s\) 是样本标准差。标准化后,通勤距离和兴趣分都变成“离平均水平几个标准差”,距离计算才更公平。
原来不是模型偏心,是我把变量放在了不同单位的尺子上。
对。特征工程第一步常常是把尺子摆正。
13.6.2 类别、时间、文本都要翻译¶
模型通常吃数字,但现实数据不只数字。
| 原始信息 | 常见做法 | 注意事项 |
|---|---|---|
| 城市、年级、渠道 | One-Hot、Target Encoding | 高基数类别要防泄漏 |
| 日期时间 | 周几、月份、是否考试周 | 周期变量可用 sin/cos |
| 文本 | 词袋、TF-IDF、Embedding | 分词和停用词会影响结果 |
| 缺失值 | 填充 + 是否缺失指示位 | 缺失本身可能有信息 |
比如“报名时间 2026-06-06 21:30”本身不容易学习,但拆成“周末、晚上、期末前一周”就更像可用信号。
13.6.3 好特征来自对问题的理解¶
在活动推荐里,原始列可能是“最近 30 天浏览活动页次数”和“最近 30 天报名次数”。派生一个“浏览后报名率”:
\[
\text{报名转化率}=\frac{\text{报名次数}}{\text{浏览次数}+1}
\]
这个特征比两个原始数字更接近“兴趣是否转成行动”。
所以特征工程不是玄学,是把问题翻译成模型更容易学的变量。
没错。模型会算,但人要帮它把问题摆成好算的样子。
13.6.4 用 Pipeline 避免处理流程泄漏¶
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.linear_model import LogisticRegression
X = np.array([
[1.2, 1200, "艺术"],
[0.3, 3500, "运动"],
[0.8, 800, "公益"],
[1.5, 1500, "艺术"],
], dtype=object)
y = np.array([1, 0, 1, 1])
preprocess = ColumnTransformer([
("num", StandardScaler(), [0, 1]),
("cat", OneHotEncoder(handle_unknown="ignore"), [2]),
])
model = make_pipeline(preprocess, LogisticRegression())
model.fit(X, y)
print(model.predict([[1.0, 1000, "艺术"]]))
把预处理放进 Pipeline,可以确保交叉验证时每一折只用训练折拟合标准化参数和编码规则,避免提前偷看验证集。
特征工程最怕数据泄漏
Target Encoding、缺失填充、标准化、特征选择,都必须在训练折内部完成。先用全量数据处理再交叉验证,会让验证分数虚高。
小率的笔记本
特征工程就是把原始信息变成模型能有效学习的信号。数值要处理尺度,类别要编码,时间和文本要拆出结构,派生特征要贴近问题。所有预处理都要放进可验证的流程里。