5.8 小结¶
小率把第 5 章的卡片摊在桌上:抽样、抽样分布、CLT、LLN、SE、样本量。均哥说,这章不是在背公式,而是在学统计推断的入口:怎样从一小部分数据,合理地谈整体。

5.8.1 一页速查图¶
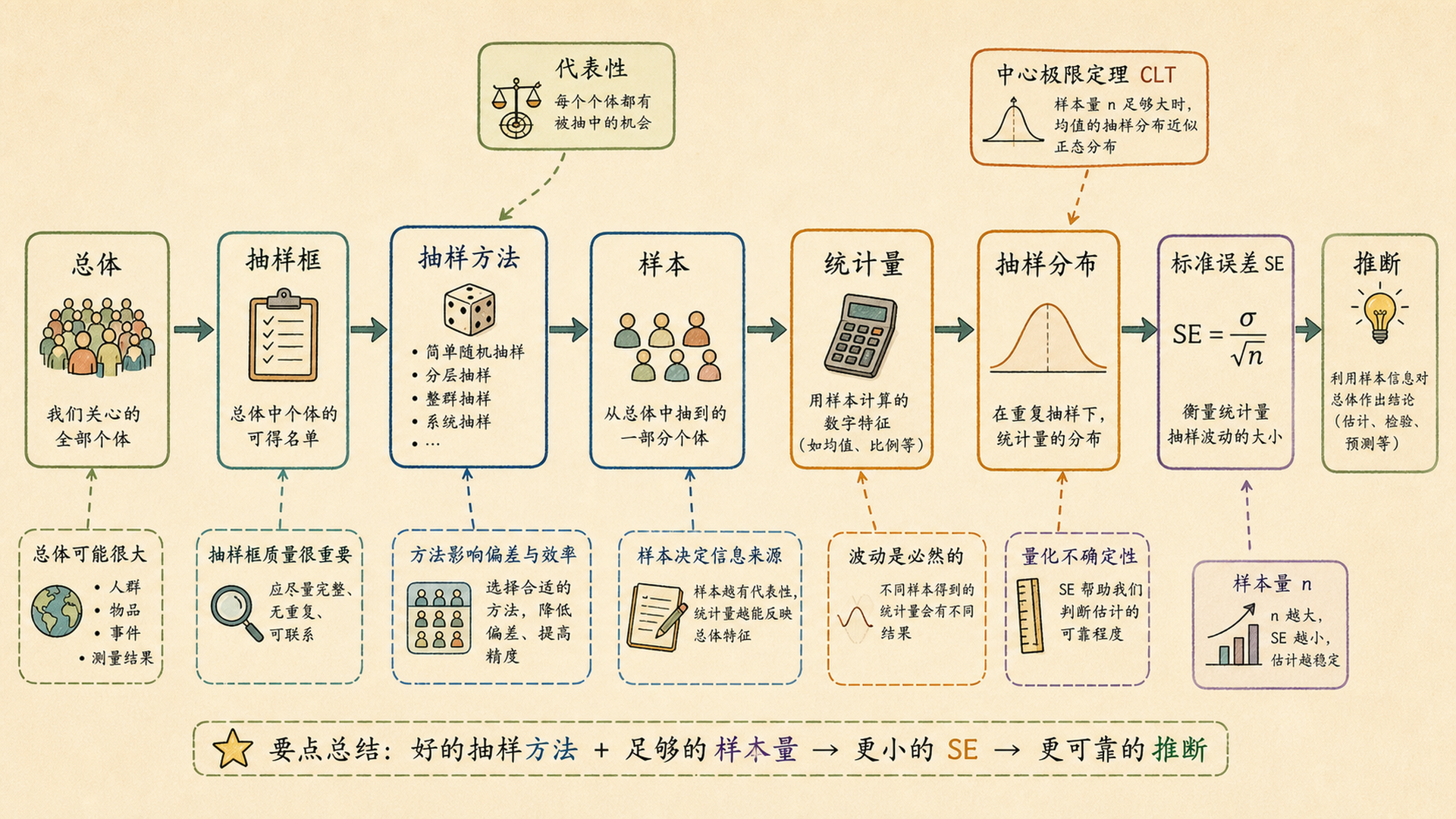
5.8.2 核心知识地图¶
Abstract
- 抽样方法决定样本能不能代表总体。
- 抽样分布描述统计量在重复抽样中的波动。
- 大数定律说明均值会靠近期望。
- 中心极限定理说明样本均值近似正态。
- 标准误差把“估计有多晃”变成一个数。
- 样本量公式把“想要多准”换成“需要多少数据”。
5.8.3 抽样推断速查表¶
抽样分布关键值
CLT 标准化
样本量
有限总体修正 FPC
设计效应 deff
5.8.4 抽样问题决策树¶
| 如果你关心 | 先看 | 常用工具 |
|---|---|---|
| 样本是否代表总体 | 抽样框、回应率、抽样方法 | SRS / 分层 / 整群 / 系统 |
| 统计量会不会晃 | 抽样分布 | 模拟重复抽样 |
| 均值能否近似正态 | 样本量、尾部、方差 | CLT |
| 估计有多精确 | SE | \(\sigma/\sqrt{n}\) 或 \(s/\sqrt{n}\) |
| 要抽多少人 | 允许误差和置信水平 | 样本量公式 / FPC / deff |
5.8.5 常见误区 Top 5¶
误区 1: 样本量越大越好
样本量决定方差; 抽样方法决定偏差。带偏的百万样本不如无偏的千例样本。
误区 2: SD 和 SE 一回事
SD 描述数据离散度 (与 n 无关); SE 描述估计精度 (= SD/√n)。论文报误差棒前必须区分。
误区 3: CLT 适用于所有情况
CLT 要求方差有限。Cauchy / 极重尾分布的均值不收敛, CLT 失败。
误区 4: 大数定律 = 赌徒补偿
LLN 是『比例靠拢期望』, 不是『绝对差额回 0』。每次硬币独立, 没有『扳回来』。
误区 5: 把『此次样本数据』当『抽样分布』
样本数据分布是这一次抽到的 n 个具体观测的直方图; 抽样分布是反复抽样的统计量分布。两者形状、宽度都不同。
5.8.6 综合大题:从头串到尾¶
某城市成年人收入 (右偏): \(\mu = 5000\) 元/月, \(\sigma = 3000\) 元/月。某调查公司想估计 \(\mu\), 95% CI 误差 ≤ ±100 元。
(1) 样本量?
\(n = (1.96 \cdot 3000 / 100)^2 = 3457\) 人。
(2) 由 CLT, x̄ 的分布?
\(\bar{X} \approx N(5000, (3000/\sqrt{3457})^2) = N(5000, 51^2)\), SE ≈ 51 元。
(3) 抽到样本均值 < 4900 的概率?
\(z = (4900 - 5000) / 51 \approx -1.96\), \(P \approx 0.025 = 2.5\%\) — 这正是 95% CI 单边的尾巴。
(4) 若用 100 个小区整群 (每区 35 人), ICC = 0.04, 实际有效样本量?
\(\mathrm{deff} = 1 + 34 \cdot 0.04 = 2.36\), \(n_{\text{eff}} = 3500 / 2.36 \approx 1483\) — 名义 3500 人, 等效只 1483, 必须扩到 ~8200 名义样本才能补偿。
(1)-(4) 串起了样本量、CLT、抽样分布、设计效应——本章四大支柱的合奏。
5.8.7 练一练 · 综合自测¶
练习 5.8.1 — 三个分布
分别用一句话描述 (a) 总体分布 (b) 样本数据分布 © 抽样分布。
参考答案
(a) 总体里所有个体取值的分布 (固定); (b) 你这一次抽样得到的 n 个观测构成的直方图 (一次性, 随机); © 假设反复抽样, 每次算的统计量 (如 x̄) 的分布 (概念性, 由概率论决定)。
练习 5.8.2 — CLT 应用
某省高考成绩 (右偏) μ=480, σ=80。任抽 100 名考生, 平均分超过 500 的概率?
参考答案
SE = 80/10 = 8。z = (500-480)/8 = 2.5。P = 1 - Φ(2.5) ≈ 0.0062 = 0.62%。CLT 适用 (n=100 远大于 30)。
练习 5.8.3 — 综合判定 (对/错)
(1) 抽样的样本量越大, 抽样分布越窄; (2) 总体方差越小, 我们对均值估计就越准; (3) 整群抽样的方差总比 SRS 小; (4) SE 总比 SD 小。
参考答案
(1) 对。SE = σ/√n, n 大 SE 小。 (2) 对。SE ∝ σ, σ 小 SE 也小。 (3) 错。整群通常方差更大 (deff > 1), 用它换的是成本节约。 (4) 对。SE = SD/√n ≤ SD (n ≥ 1)。
5.8.8 下章预告¶
第 6 章关键词预览:
- 点估计 (Point Estimate) — 矩估计、最大似然 MLE
- 置信区间 (Confidence Interval, CI)
- \(t\) 分布 (σ 未知时替代 z)
- \(\chi^2\) 分布 (用于方差 CI)
- 自助法 Bootstrap (现代非参数 CI)
走起!
5.8.9 练一练¶
本章核心练习题汇总。建议先动笔再看参考答案。
练习 5.1.1 — 偏差识别
某网站让用户给商品打 5 星, 结果 80% 都是 5 星。这反映出哪种偏差?
参考答案
主要是 选择偏差 + 无回应偏差 : 满意者倾向打分 (尤其 5 星), 不满者要么差评, 要么沉默离开。 解决: 主动随机邀请已购顾客打分, 而非依赖自发打分。
练习 5.1.2 — 普查 vs 抽样
什么场景下普查仍是必要的? 至少举两例。
参考答案
(1) 国家人口普查 (法律强制, 每 10 年一次, 用于行政区划/选举席位)。 (2) 安全审计 — 飞行器全部螺丝、核电站每根燃料棒。 (3) 小总体且重要 — 上市公司高管薪酬披露。 一般规则: 总体小、个体重要、要绝对值用普查; 总体大、要近似估计用抽样。
练习 5.1.3 — 设计抽样
某高校 4 万学生, 想了解平均周学习时间。提出一个无偏的抽样方案。
参考答案
(1) 从学籍系统拿全校学号列表; (2) 简单随机抽 500 个 (或按年级分层抽); (3) 微信/邮件多次提醒, 提高回应率到 70%+; (4) 对未回应者, 短信再访 100 人, 用差异校正 (无回应权重)。 样本量 n=500 → 95% CI 误差 ≈ ±0.5 小时 (假设 σ ≈ 6)。
练习 5.2.1 — 选方法
某高校 4 学院, 男女比例和专业方向差异很大, 想估计平均月生活费。最合适的方法?
参考答案
分层抽样 , 以"学院 × 性别"为分层变量, 各层比例分配。原因: 层间生活费差异大 (理工男生 vs 文科女生), 分层显著降低方差。
练习 5.2.2 — 系统陷阱
某医院按"床号"排列患者列表, 每隔 8 人抽 1 人调查满意度。结果重病房 (1-8 号) 几乎被忽略。问题在哪?
参考答案
抽样起点固定时, 若名单有周期性结构 (床号编排恰好让重病房集中在 1-4 号), 系统抽样会系统性漏掉某子集。 解决: 使用 SRS, 或随机化名单顺序后再系统抽。
练习 5.2.3 — 整群代价
抽 100 户调查家庭支出, 方案 A: 全国 SRS 100 户; 方案 B: 整群抽 5 个小区, 每小区 20 户。哪个方差小? 哪个成本低?
参考答案
方差 : A < B。整群内同质性高 (同小区收入相近), 等效样本量 < 100, 方差通常是 SRS 的 1.2 - 3 倍 (称『设计效应 deff』)。 成本 : A >> B。SRS 要全国跑, 整群只跑 5 个地点。 实际权衡: 通常牺牲一点精度换大量成本节约 + 加大 n 补偿。
练习 5.3.1 — 概念辨析
"样本数据分布" 与 "抽样分布" 一样吗?
参考答案
不一样 。 样本数据分布 = 你这一次抽到的 n 个具体数字的直方图; 它的均值就是 x̄。 抽样分布 = 假设你反复抽 1000 次, 每次算一个 x̄, 这 1000 个 x̄ 的分布; 它的均值是 μ, 标准差是 σ/√n。
练习 5.3.2 — SE 速算
总体 \(\sigma = 12\), 样本量从 4 升到 144, SE 怎么变?
参考答案
n=4: SE = 12/2 = 6; n=144: SE = 12/12 = 1。 样本量翻 36 倍, SE 减为 ⅙。一般规律: SE 缩小 k 倍 ⇔ n 增加 k² 倍。
练习 5.3.3 — 比例抽样分布
某产品次品率 p=0.02, 抽 500 个。次品比例 \(\hat{p}\) 的期望和 SE?
参考答案
\(E[\hat{p}] = p = 0.02\)。 \(\mathrm{SE} = \sqrt{p(1-p)/n} = \sqrt{0.02 \cdot 0.98 / 500} \approx 0.00626\)。 所以 95% CI 大致 \(0.02 \pm 1.96 \cdot 0.00626 \approx [0.008, 0.032]\)。
练习 5.4.1 — 概率计算
某车间零件重量 μ=10g, σ=2g, 总体不知形态。抽 100 个, 平均重量在 [9.7, 10.3] 内的概率?
参考答案
SE = 2/√100 = 0.2。 z₁ = (9.7-10)/0.2 = -1.5, z₂ = (10.3-10)/0.2 = 1.5。 P = Φ(1.5) - Φ(-1.5) = 2Φ(1.5) - 1 = 2 · 0.9332 - 1 = 0.8664。 约 87%。
练习 5.4.2 — 工程估计
某 App 用户日活时长非常右偏 (μ=20 min, σ=30 min)。要估计平均时长, 误差不超过 1 分钟 (95% 把握), 至少多少用户?
参考答案
\(1.96 \cdot \sigma/\sqrt{n} \leq 1 \Rightarrow n \geq (1.96 \cdot 30)^2 = 3458\) 人。 总体右偏没关系, n=3458 远超 30, CLT 适用。
练习 5.4.3 — CLT 失效
Cauchy 分布的 CLT 适用吗? 给出原因。
参考答案
不适用。Cauchy 分布没有期望和方差 (积分发散), CLT 的前提条件不满足。事实上 Cauchy 样本均值依然是 Cauchy (不会变窄!), 这与 CLT/LLN 都背道而驰。 实际中遇到的『重尾但有限方差』分布 (如 Pareto α>2), CLT 仍然适用, 只是 n 要更大。
练习 5.5.1 — 赌徒谬误识别
"我抛硬币连出 5 次正, 下一次反面概率应该 > 50%。" 错在哪?
参考答案
硬币每次独立, P(反 | 前 5 次正) = P(反) = 0.5。 LLN 说『长期 1000 次中正反比例趋于 50:50』, 不是说『下一局有补偿』。 若硬币真公平, 即使前 5 正, 下次仍是 0.5。
练习 5.5.2 — LLN vs CLT
一句话各自概括 LLN 和 CLT 的内容。
参考答案
LLN: 样本均值 x̄ 会收敛到真期望 μ (方向)。 CLT: 样本均值 x̄ 怎么收敛 —— 形状近似正态, 速率 σ/√n (路径)。
练习 5.5.3 — 蒙特卡洛
用蒙特卡洛估计积分 ∫₀¹ e^x dx (真值 ≈ 1.7183)。说明大致需要多大的 n 才能精确到 ±0.001 (95% 把握)。
参考答案
被积函数 g(U) = e^U, U~Unif(0,1)。 σ² = E[e^(2U)] - (E[e^U])² = (e²-1)/2 - (e-1)² ≈ 3.194 - 2.952 = 0.242, σ ≈ 0.492。 要 1.96 σ/√n ≤ 0.001 → n ≥ (1.96 × 0.492 / 0.001)² ≈ 930,000。约百万级别。
练习 5.6.1 — 概念辨析
若 n=400, σ = 20。SD 与 SE 各是多少?
参考答案
SD = σ = 20 (描述数据本身的离散度)。 SE = σ/√n = 20/20 = 1.0 (描述 x̄ 估计 μ 的精度)。 SD : SE = 20 : 1, 相差 √n = 20 倍。
练习 5.6.2 — 反推样本量
报道说 mean = 75, SE = 0.5, σ = 10。问 n?
参考答案
SE = σ/√n → 0.5 = 10/√n → √n = 20 → n = 400。
练习 5.6.3 — 误差棒识别
某论文一组对照 (n=20) 误差棒 ≈ 1.0; 另一组实验 (n=200) 误差棒 ≈ 0.3。它们都标 mean ± X。 X 是 SD 还是 SE? 给出判断依据。
参考答案
几乎肯定是 SE 。 若两组数据同分布 (期望同 SD), SD 应大致相同。 现在大 n 那组误差棒小很多 — 比例接近 √(200/20) ≈ 3.16, 与 1.0/0.3 ≈ 3.33 吻合, 完美符合 SE = SD/√n。 所以这是 SE 误差棒, 不能用来判断"个体差异"。
练习 5.7.1 — 比例样本量
某商场满意度调查, 想 99% CI 内 ±5% 估计满意比例, 至少抽多少人? (z₀.₀₀₅ = 2.576)
参考答案
最坏情况 p=0.5: \(n = 2.576^2 / (4 \cdot 0.05^2) = 663\) 人。
练习 5.7.2 — 均值样本量 + FPC
某厂 800 名工人, 想 95% CI ±0.3 估计平均工龄。预试验 σ ≈ 4 年。 (a) 不修正: n = ? (b) FPC 修正: n = ?
参考答案
(a) \(n_0 = (1.96 \cdot 4 / 0.3)^2 \approx 683\)。 (b) \(n = 683 / (1 + 683/800) \approx 369\)。修正后只需 369, 节省近半。
练习 5.7.3 — Power 角度
检验"新设计能否提高购买率 1.5 个百分点 (从 5% → 6.5%)", 双侧 α=0.05, power=0.80, 每组多少用户?
参考答案
比例差 d 用 Cohen's h 或简化公式: \(n \approx (z_{\alpha/2} + z_\beta)^2 \cdot [p_1(1-p_1) + p_2(1-p_2)] / (p_1 - p_2)^2\) \(= (1.96 + 0.84)^2 \cdot (0.05 \cdot 0.95 + 0.065 \cdot 0.935) / 0.015^2\) \(= 7.84 \cdot 0.1083 / 0.000225 \approx 3771\) /组。 所以 A/B 测试要近 8000 人才能可靠检出 1.5pp 差异 — 小效应需大样本。