5.7 样本量与有效样本量¶
小率想做一份城市月薪调查。他说:我希望误差不超过 500 元。均哥没有立刻给数字,而是先问:你愿意为这个精度付多少钱?因为样本量公式背后,其实是一条预算曲线。

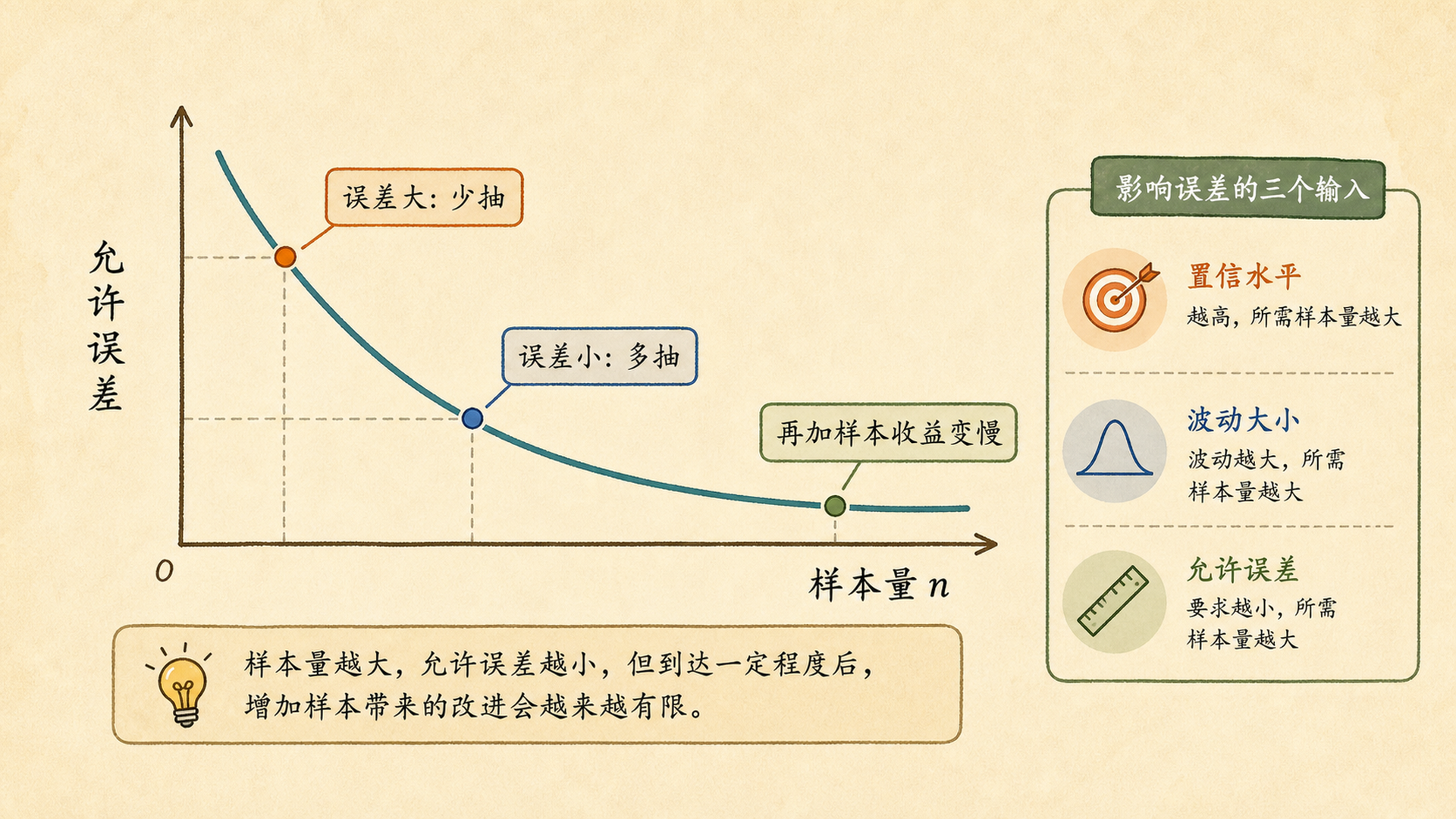
想更准,要多抽多少人
样本量不是越大越好,而是在精度、成本、时间和抽样设计之间做权衡。
5.7.1 从允许误差反推 n¶
如果要估计总体均值,希望 95% 置信水平下误差不超过 \(E\),常用近似公式是:
\[
n \ge \left(\frac{z_{\alpha/2}\sigma}{E}\right)^2
\]
95% 置信水平常用 \(z_{\alpha/2}=1.96\)。
公式里最刺眼的是 $E^2$。它是不是说明误差减半,样本量变四倍?
对,这就是样本量最贵的地方。
5.7.2 估计比例时的样本量¶
估计满意比例、支持率、转化率时,常用:
\[
n \ge \frac{z_{\alpha/2}^2 p(1-p)}{E^2}
\]
如果事先不知道 \(p\),最保守取 \(p=0.5\),因为此时 \(p(1-p)\) 最大。
比例样本量的保守算法
95% 置信水平、误差不超过 ±3%,且不知道真实比例时:
\(n \ge 1.96^2 \times 0.5 \times 0.5 / 0.03^2 \approx 1068\)。
5.7.3 有效样本量:名义 n 不等于信息量¶
如果使用整群抽样,同一群内个体很相似,名义样本量可能高估真实信息量。常用设计效应(Design Effect)调整:
\[
n_{\text{eff}}=\frac{n}{\mathrm{deff}}
\]
其中 \(n_{\text{eff}}\) 是有效样本量。
我明明调查了 1000 人,为什么有效样本量可能只有 600?
因为这 1000 人如果来自少数几个相似群体,提供的新信息没有 1000 个独立人那么多。
5.7.4 有限总体修正:总体很小时可以少抽¶
当总体 \(N\) 不大,且抽样不放回时,可以用有限总体修正(Finite Population Correction, FPC):
\[
n=\frac{n_0}{1+n_0/N}
\]
这里 \(n_0\) 是按无限总体算出的样本量。
什么时候 FPC 有用
如果总体有 80 万人,FPC 几乎没影响;如果总体只有 800 人,FPC 可能让所需样本量明显下降。
5.7.5 一段代码算三个常用 n¶
import math
def n_for_mean(sigma, error, z=1.96):
return math.ceil((z * sigma / error) ** 2)
def n_for_proportion(error, p=0.5, z=1.96):
return math.ceil((z ** 2) * p * (1 - p) / error ** 2)
def fpc_adjust(n0, N):
return math.ceil(n0 / (1 + n0 / N))
print("估计月薪,σ=6000,误差±500:", n_for_mean(6000, 500))
print("估计满意比例,误差±3%:", n_for_proportion(0.03))
print("总体 N=800 时的 FPC 修正:", fpc_adjust(683, 800))
5.7.6 样本量不是万能药¶
样本量的边界
样本量公式默认抽样设计合理、测量误差可控、回应机制不严重偏。若问卷问题诱导、样本框漏人或无回应严重,增加样本量只会更精确地重复错误。
小率的笔记本
- 均值样本量:\(n \ge (z\sigma/E)^2\)。
- 比例样本量:\(n \ge z^2p(1-p)/E^2\)。
- 误差减半,样本量约变四倍。
- 整群抽样要看有效样本量,有限总体可用 FPC 修正。