9.1 单因素方差分析¶
暑假社团准备做一次学习方法分享。小率手里有一张活动记录:同学们被随机分到三种复习方式,最后都做了同一份小测。

| 复习方式 | 小测成绩 | 人数 | 平均分 |
|---|---|---|---|
| 刷题组 | 78, 82, 80, 79, 81 | 5 | 80.0 |
| 讲解组 | 83, 85, 84, 86, 82 | 5 | 84.0 |
| 混合组 | 88, 90, 89, 91, 87 | 5 | 89.0 |
9.1.1 先别急着两两比较¶
三组一共有 3 对比较:刷题 vs 讲解、刷题 vs 混合、讲解 vs 混合。若有 5 组,就有 10 对;若有 8 组,就有 28 对。每次都按 0.05 显著性水平判断,整体犯一次错的概率会明显升高。
单因素方差分析(One-Way ANOVA)先做一个总检验:
ANOVA 的问题
如果所有复习方式的真实平均效果都一样,我们现在看到的组间差异是否仍然合理?
它的零假设不是“某两组相等”,而是:
备择假设也很克制:
所以 ANOVA 显著时,它只告诉我们“至少有一组不一样”,还没有告诉我们“到底哪两组不一样”。这个问题要留给 9.3 的事后检验。
9.1.2 F 值看的是组间差异和组内波动的比例¶
ANOVA 的核心图像很简单:如果三组的平均分差得很开,而每组内部同学成绩又很集中,那么“复习方式确实有影响”的证据就强。反过来,如果三组平均分差不多,或者每组内部本来就乱成一团,证据就弱。
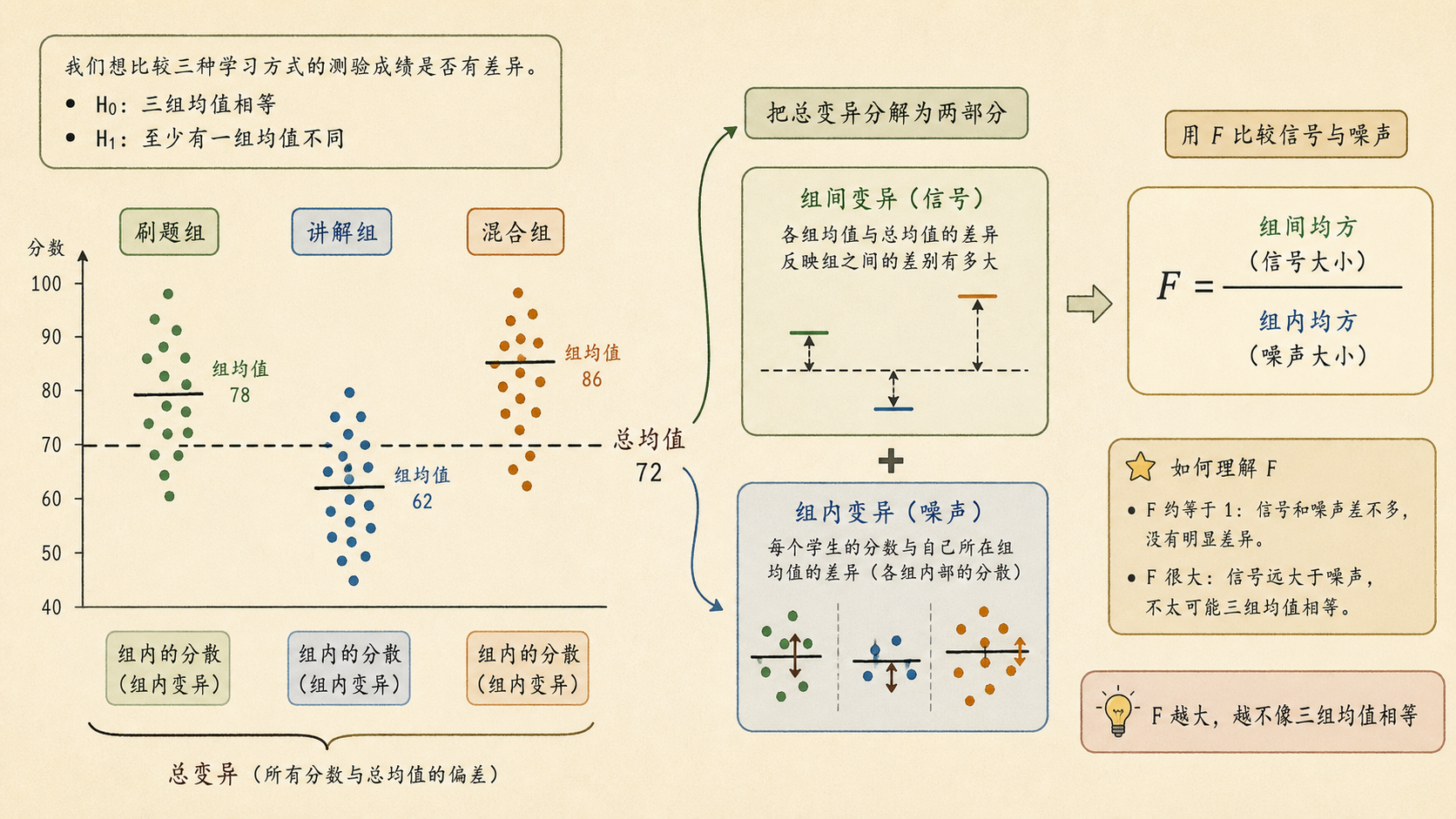
ANOVA 把总波动拆成两部分:
对应到平方和:
- 组间变异 SSB:每组平均分离总平均有多远。
- 组内变异 SSW:同一组内部的同学分数有多分散。
F 统计量就是把两种变异都换成“均方”以后相除:
如果 F 很大,说明组间差异相对于组内波动太大,不太像纯随机噪声。
9.1.3 从一张 ANOVA 表读出结论¶
ANOVA 表最常见的几列是:
| 来源 | 平方和 | 自由度 | 均方 | F | p |
|---|---|---|---|---|---|
| 组间 | SSB | k - 1 | MSB | MSB / MSW | p 值 |
| 组内 | SSW | N - k | MSW | ||
| 总计 | SST | N - 1 |
读表顺序
先看 p 值是否小于设定的显著性水平,再看效应量。显著不等于差异很大,样本量很大时很小的差异也可能显著。
常用效应量是 \(\eta^2\):
它表示“总波动中有多少比例可以被组别解释”。比如 \(\eta^2=0.62\),可以粗略理解为:成绩总差异中约 62% 和复习方式分组有关。
9.1.4 什么时候要小心使用 ANOVA¶
单因素 ANOVA 常见前提有三个:
- 每个观察值相互独立。
- 各组残差大致接近正态。
- 各组方差大致相近。
这些前提不是用来吓人的,而是提醒我们别把错误的数据结构硬塞进模型。
需要换工具的情况
如果方差明显不齐,可以考虑 Welch ANOVA;如果分布严重偏斜、样本量又很小,可以考虑 Kruskal-Wallis 检验;如果同一个人被重复测量,不能当成普通独立样本 ANOVA。
9.1.5 用 Python 做一次单因素 ANOVA¶
配套脚本放在:
核心代码如下:
import pandas as pd
from scipy import stats
scores = {
"刷题组": [78, 82, 80, 79, 81],
"讲解组": [83, 85, 84, 86, 82],
"混合组": [88, 90, 89, 91, 87],
}
f_stat, p_value = stats.f_oneway(*scores.values())
print(f"F = {f_stat:.3f}, p = {p_value:.4f}")
df = pd.DataFrame(
[(group, score) for group, values in scores.items() for score in values],
columns=["复习方式", "成绩"],
)
print(df.groupby("复习方式")["成绩"].agg(["count", "mean", "std"]))
小率的笔记本
单因素 ANOVA 用来比较三组及以上均值。它把总波动拆成组间和组内两部分,用 \(F=MSB/MSW\) 判断组间差异是否大到不像随机波动。显著以后,还要用事后检验回答“哪几组不同”。