9.3 事后检验¶
单因素 ANOVA 告诉小率:三种复习方式的平均成绩并不全都一样。可小率马上遇到第二个问题:到底是刷题组和讲解组不同,还是混合组把差异拉开了?

ANOVA 已经显著了,我现在是不是可以放心做三次 t 检验?
还不能。显著以后再乱做很多次比较,还是会把假阳性率抬高。事后检验就是带着校正去定位差异。
9.3.1 ANOVA 只告诉我们至少一组不同¶
ANOVA 的备择假设是“至少有一组均值不同”。它不负责指出哪一组不同。事后检验(Post Hoc Tests)是在总检验显著之后,对具体组别差异做有控制的比较。
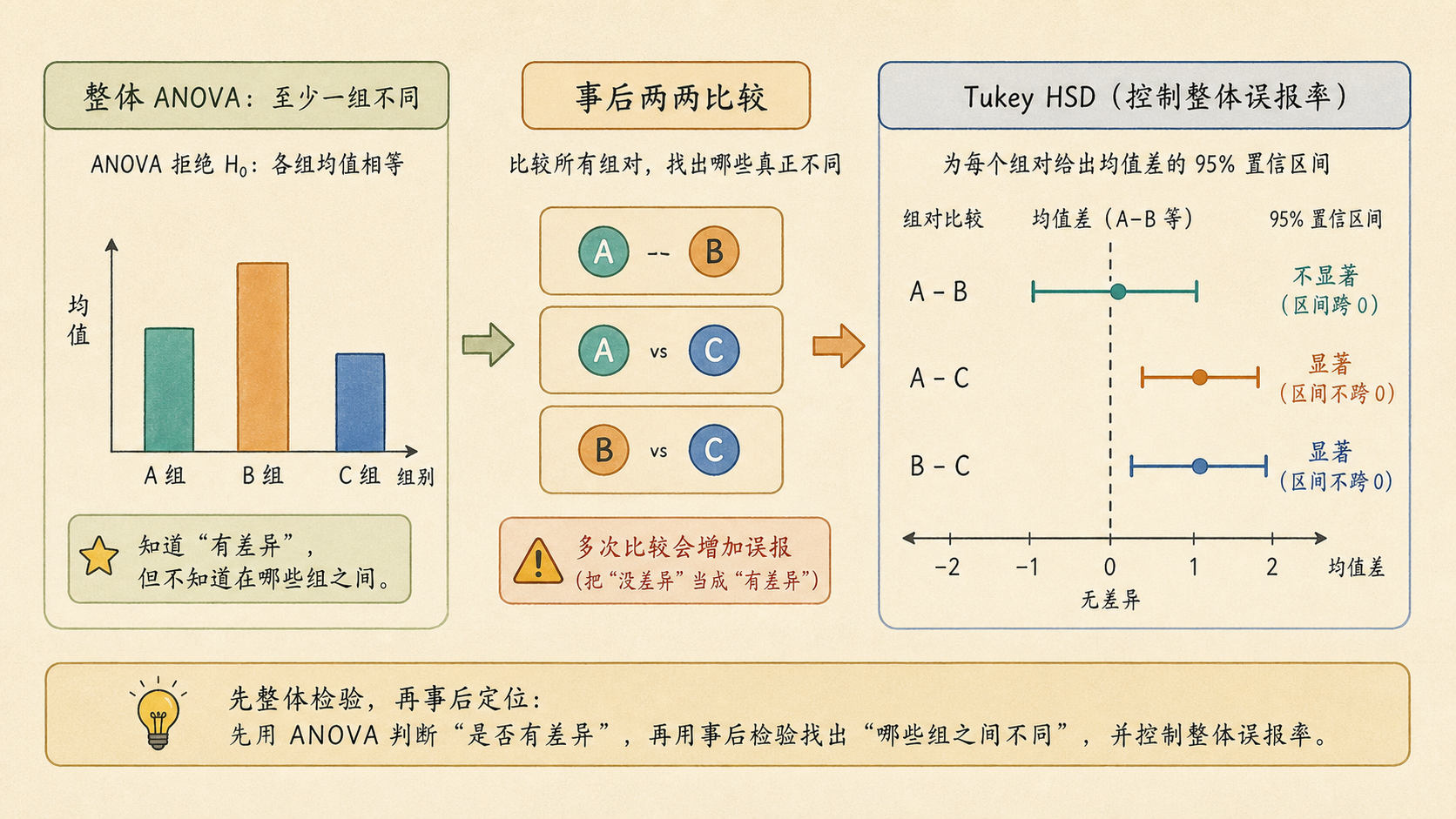
常见思路是:每比较一对组,都给出均值差、置信区间和校正后的 p 值。如果置信区间不包含 0,说明这一对均值差异比较站得住。
9.3.2 Tukey HSD 适合全部两两比较¶
Tukey HSD(Honestly Significant Difference)常用于“所有组都想两两比较”的场景。比如三种复习方式都互相比较:
| 比较 | 直觉问题 |
|---|---|
| 刷题组 - 讲解组 | 只听讲解是否比刷题高? |
| 刷题组 - 混合组 | 混合方式是否明显更高? |
| 讲解组 - 混合组 | 混合是否比单纯讲解更高? |
选择哪种事后检验
Tukey 适合所有组两两比较;Dunnett 适合多个处理组都和一个对照组比较;Games-Howell 更适合方差不齐、样本量不齐的情况;Bonferroni 和 Holm 是更通用的多重比较校正方法。
9.3.3 别把事后检验当成显著性清单¶
事后检验最好和效应量、置信区间一起读。比如“混合组比刷题组高 9 分”比“p < 0.05”更有解释力。读者真正关心的不是星号,而是差异有多大、方向是什么、是否值得采取行动。
先验计划更重要
如果你在看完数据后才临时决定比较一大堆组合,就很容易变成“找显著”。更好的做法是在实验前写清楚主要比较和次要比较。
9.3.4 用 Python 做 Tukey HSD¶
配套脚本放在:
核心代码如下:
import pandas as pd
from statsmodels.stats.multicomp import pairwise_tukeyhsd
df = pd.DataFrame({
"method": ["刷题组"] * 5 + ["讲解组"] * 5 + ["混合组"] * 5,
"score": [78, 82, 80, 79, 81, 83, 85, 84, 86, 82, 88, 90, 89, 91, 87],
})
result = pairwise_tukeyhsd(endog=df["score"], groups=df["method"], alpha=0.05)
print(result)
所以流程是:先 ANOVA 看整体,再事后检验找具体差异。
没错。先问“有没有”,再问“在哪里”,统计推断也要讲顺序。
小率的笔记本
事后检验用于 ANOVA 显著之后定位差异。Tukey HSD 适合全部两两比较,重点读均值差、置信区间和校正后的 p 值。不要在看完数据后无限追加比较。