10.3 贝叶斯推断¶
社团准备把活动报名页改版。A 版是旧页面,B 版是新页面。小率收集到一小批数据后,不想只听“显著/不显著”,他更想知道:B 版比 A 版好的概率有多大?提升幅度大概是多少?

| 版本 | 访问人数 | 报名人数 |
|---|---|---|
| A 版 | 80 | 12 |
| B 版 | 80 | 18 |
我能不能直接说:B 版优于 A 版的概率是多少?
这正是贝叶斯推断擅长回答的问题。先给每个版本的转化率算后验,再比较两条后验样本。
10.3.1 后验分布可以直接回答决策问题¶
贝叶斯推断(Bayesian Inference)拿到后验分布后,可以做四件事:
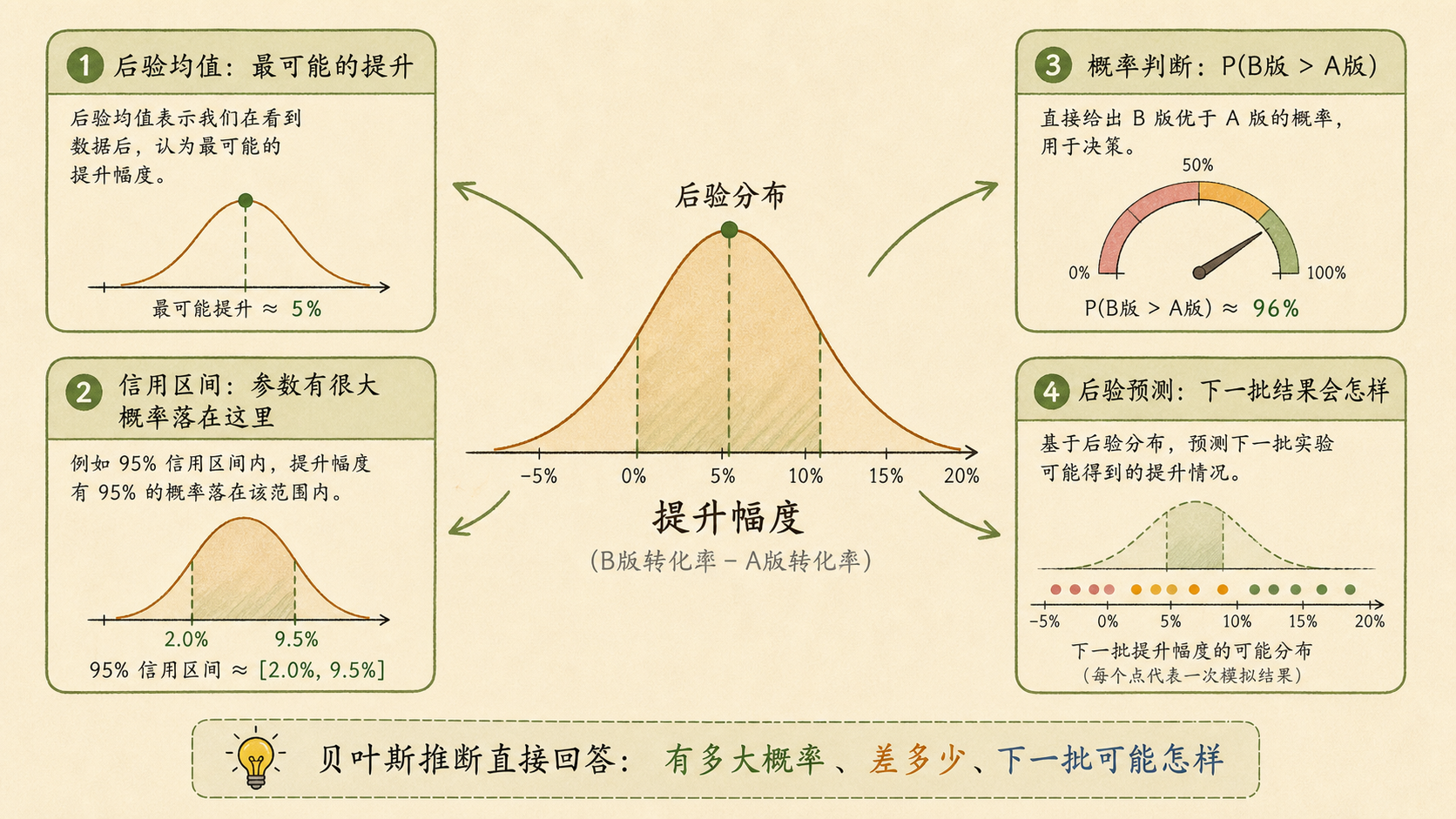
| 输出 | 含义 |
|---|---|
| 后验均值 | 参数的一个综合估计 |
| 信用区间 | 参数有很大概率落入的范围 |
| 概率判断 | 例如 \(P(B>A\mid D)\) |
| 后验预测 | 下一批数据可能长什么样 |
信用区间的直觉
贝叶斯 95% 信用区间可以读作:在当前模型和数据下,参数有 95% 的后验概率落在这个区间内。
10.3.2 从两个转化率后验开始¶
对 A 版和 B 版都使用弱信息先验:
\[
p_A,p_B\sim \text{Beta}(2,2)
\]
观察数据后:
\[
p_A\mid D_A\sim \text{Beta}(2+12,2+68)=\text{Beta}(14,70)
\]
\[
p_B\mid D_B\sim \text{Beta}(2+18,2+62)=\text{Beta}(20,64)
\]
如果我们从这两条后验分布里各抽很多样本,就能计算:
\[
P(p_B>p_A\mid D)
\]
这比“p 值小于 0.05 吗”更贴近决策语言。
10.3.3 后验预测看下一批可能怎样¶
后验不只估计当前参数,还能预测未来。比如下一批各来 100 个访问者,我们可以:
- 从 \(p_A\) 的后验抽一个转化率。
- 用这个转化率模拟 A 版 100 人里有多少报名。
- 对 B 版也做同样的事。
- 重复很多次,得到下一批结果的预测分布。
别把后验概率当成绝对真理
后验概率依赖模型、先验和数据质量。如果流量来源偏了、实验没有随机分流,后验再漂亮也会建立在有偏数据上。
10.3.4 用 Python 计算 B 优于 A 的概率¶
配套脚本放在:
import numpy as np
from scipy import stats
rng = np.random.default_rng(42)
a_post = (2 + 12, 2 + 80 - 12)
b_post = (2 + 18, 2 + 80 - 18)
a_samples = rng.beta(*a_post, size=100_000)
b_samples = rng.beta(*b_post, size=100_000)
lift = b_samples - a_samples
print(f"P(B > A) = {(b_samples > a_samples).mean():.3f}")
print(f"提升幅度后验均值 = {lift.mean():.3%}")
print("提升幅度 95% 信用区间 =", np.quantile(lift, [0.025, 0.975]))
所以贝叶斯推断不是只换了一个检验,而是直接把“决策想问的话”算出来。
对。后验分布是一个工具箱,估计、区间、概率判断、预测都从里面拿。
小率的笔记本
贝叶斯推断从后验分布出发。它可以给后验均值、信用区间、某个方案更好的概率,也可以做后验预测。解释结果时要同时说明先验、模型和数据来源。