6.6 比例的置信区间¶
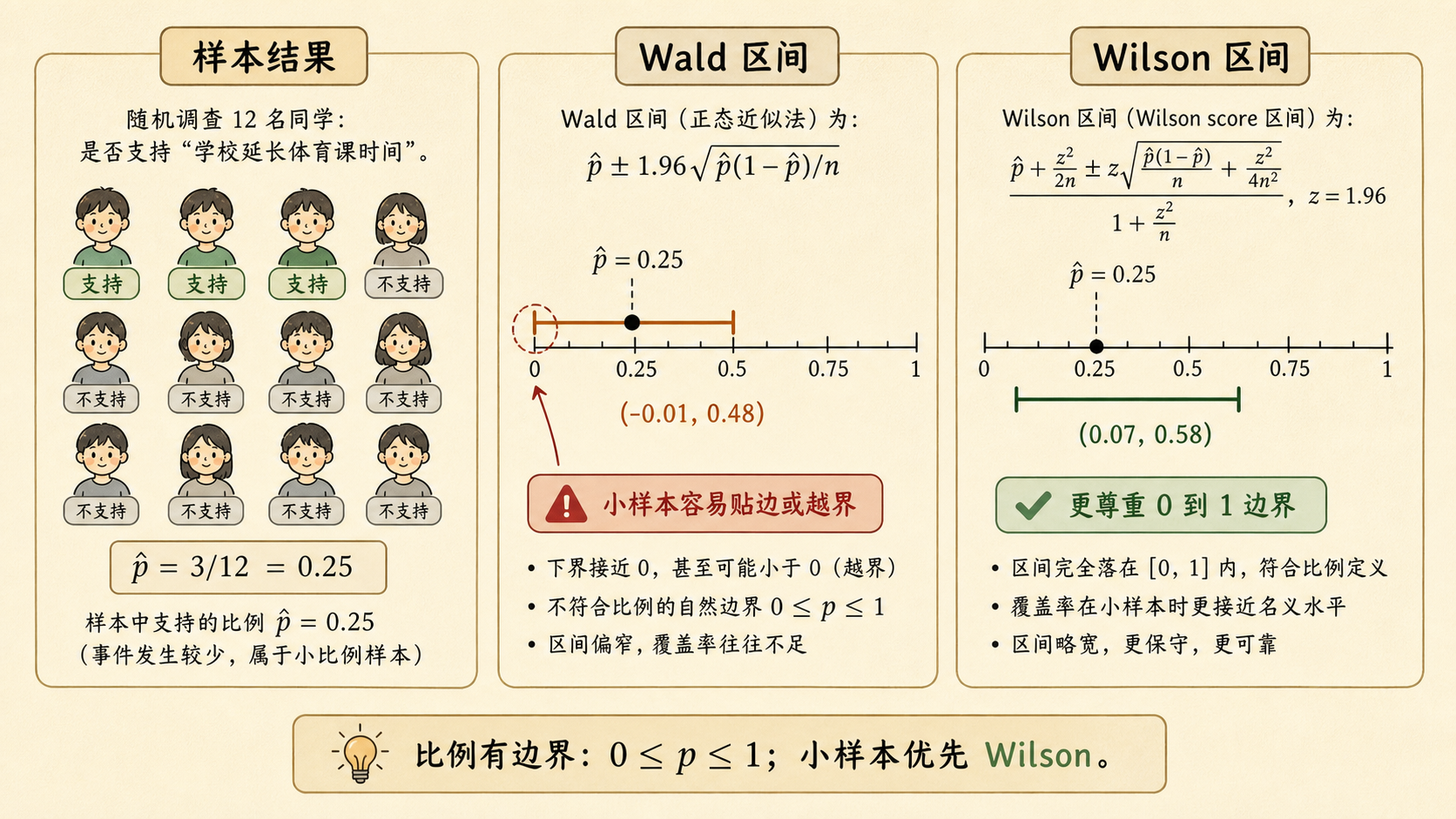
班级要不要周末开一个自习小组?小率问了 12 位同学,其中 3 人支持。样本比例是:
| 回答 | 人数 | 记成 0/1 |
|---|---|---|
| 支持 | 3 | 1 |
| 不支持 | 9 | 0 |
| 合计 | 12 | - |
问题看起来很像均值:比例也是 0/1 数据的平均数。但比例有边界,不能小于 0,也不能大于 1。很多看似自然的公式,在小样本里会翻车。

比例区间为什么不能随便套公式
比例的标准误包含 \(p(1-p)\),而 \(p\) 自己未知。若直接把 \(p\) 替换成 \(\hat p\),在小样本或极端比例下,区间可能越过 0 和 1 的边界。
6.6.1 Wald 区间:简单但容易翻车¶
最经典的比例区间叫 Wald 区间(Wald Interval):
用小率的例子:
标准误为:
95% Wald 区间:
这次勉强没有越界,但已经非常贴近 0。若样本更小或支持人数更少,下限很容易变成负数。
Wald 的三个坑
小样本时覆盖率不稳;\(\hat p\) 接近 0 或 1 时容易越界;当成功数为 0 或全成功时,区间会退化得过于自信。
6.6.2 Wilson 区间:更稳的默认选择¶
现代实践更推荐 Wilson 区间(Wilson Score Interval)。它不是把 \(\hat p\) 填进标准误里就完事,而是反过来问:
哪些 \(p\) 与观测到的 \(\hat p\) 足够接近?
公式为:
Wilson 区间的好处是:
- 更尊重 \(0\leq p\leq1\) 的边界。
- 小样本覆盖率通常更接近标称水平。
- 工业和论文中比 Wald 更稳。
6.6.3 双样本比例差:A/B 测试的基本语言¶
若比较两个比例,比如旧版页面转化率 10%,新版页面转化率 13%,我们关心的是:
大样本下,比例差的近似区间是:
如果这个区间不包含 0,就说明“新版可能真的比旧版高”;如果包含 0,就说明样本波动还不能排除“其实没差”。
A/B 测试读区间
对比例差来说,0 是关键线。区间全在 0 上方,新方案更好;全在 0 下方,新方案更差;跨过 0,则证据不足。
6.6.4 Python 比较 Wald 和 Wilson¶
from statsmodels.stats.proportion import proportion_confint
success = 3
n = 12
wald = proportion_confint(success, n, alpha=0.05, method="normal")
wilson = proportion_confint(success, n, alpha=0.05, method="wilson")
print(f"样本比例 = {success / n:.3f}")
print(f"Wald 95% CI = [{wald[0]:.3f}, {wald[1]:.3f}]")
print(f"Wilson 95% CI = [{wilson[0]:.3f}, {wilson[1]:.3f}]")
完整脚本见:
小率的笔记本
比例区间不能忘记 0 到 1 的边界。Wald 简单但小样本容易翻车,Wilson 更稳,适合作为默认方法。比较两个比例时,看比例差区间是否包含 0。