5.6 标准误差与标准差¶
小率在一篇实验报告里看到「平均值 = 15.2 ± 2.1」。他以为这说明每个学生的成绩都差不多在 15.2 附近。均哥问:这个 ±2.1 是在描述个体差异,还是在描述均值的估计精度?

误差棒到底代表什么
同样写成 mean ± X,X 可能是标准差(SD)、标准误差(SE)或置信区间半宽。读图之前必须先看图注。
5.6.1 SD 描述数据本身有多散¶
标准差(Standard Deviation, SD) 描述个体数据围绕均值的离散程度。
\[
s=\sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{x})^2}
\]
SD 大,是不是说明这个班学生差异大?
对。SD 是在说个体之间有多不一样。
5.6.2 SE 描述均值估计有多稳¶
标准误差(Standard Error, SE) 描述统计量在重复抽样中的波动。对样本均值来说:
\[
\mathrm{SE}(\bar{X})=\frac{\sigma}{\sqrt{n}}
\]
如果总体标准差未知,实际常用样本标准差代替:
\[
\widehat{\mathrm{SE}}(\bar{X})=\frac{s}{\sqrt{n}}
\]
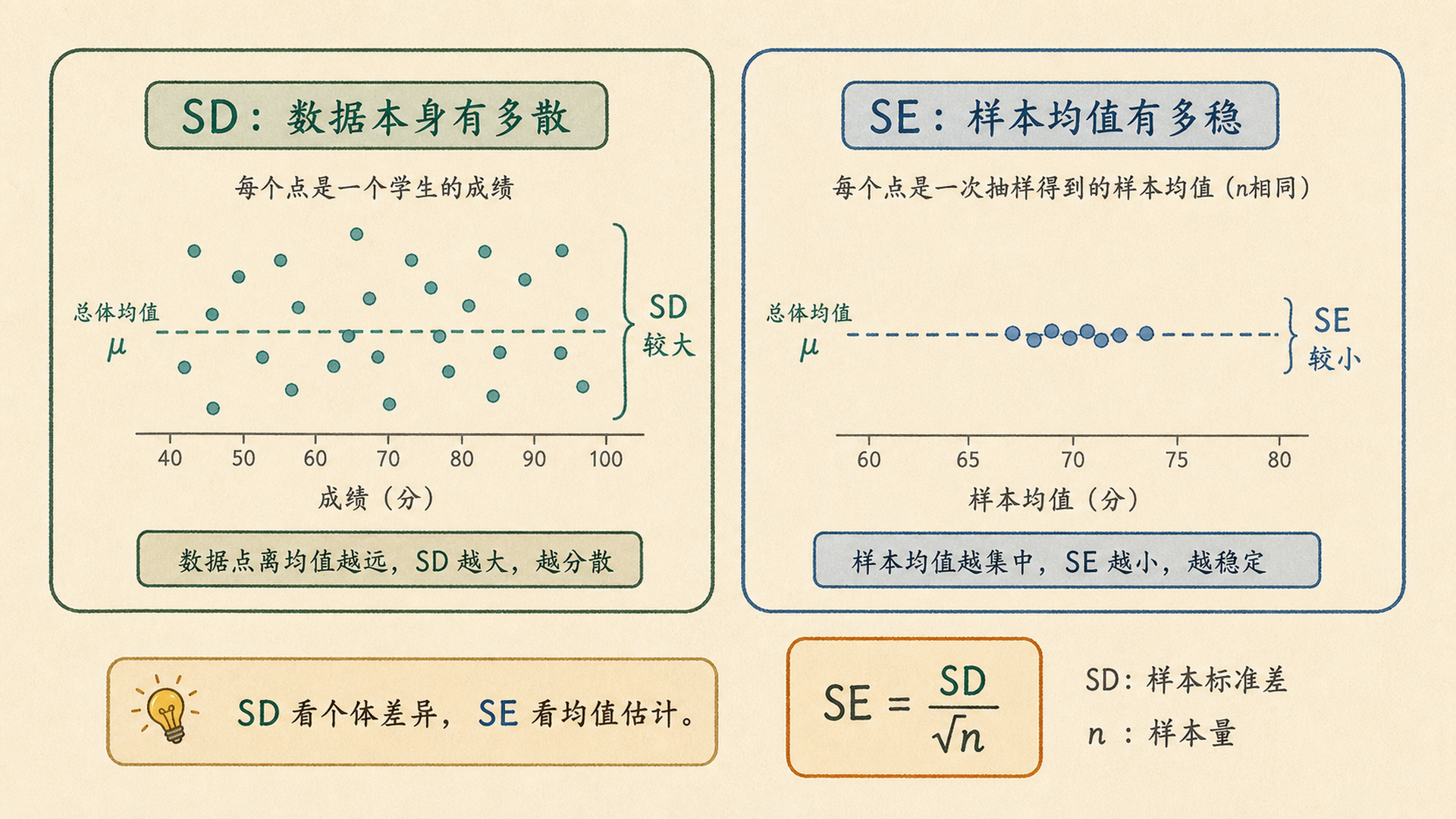
所以 n 变大,SE 会变小,但 SD 不一定变小?
正是。多抽人会让均值更稳,但不会让人和人之间本来就更像。
5.6.3 用一个班级成绩算一遍¶
import numpy as np
scores = np.array([11, 13, 14, 15, 15, 16, 17, 18, 20, 23])
mean = scores.mean()
sd = scores.std(ddof=1)
se = sd / np.sqrt(len(scores))
print(f"平均分 = {mean:.2f}")
print(f"SD = {sd:.2f},描述学生之间的差异")
print(f"SE = {se:.2f},描述平均分估计的波动")
5.6.4 论文图怎么读¶
| 图注写法 | 读法 |
|---|---|
| mean ± SD | 个体数据大多分布在哪 |
| mean ± SE | 样本均值估计有多稳定 |
| mean ± 95% CI | 总体均值可能落在哪 |
可视化误读
如果论文用 SE 画误差棒,误差棒会随着 n 变大而变短。它不能说明个体差异变小,只能说明均值估计更稳定。
5.6.5 什么时候用哪个¶
使用建议
想描述数据本身,用 SD;想报告均值估计精度,用 SE 或置信区间;想让读者比较实际个体差异,不要只给 SE。
我以后看到 mean ± X,会先找图注,不直接脑补。
这就是读统计图的基本礼貌。
小率的笔记本
- SD 描述数据本身的离散程度。
- SE 描述统计量的抽样波动。
- 均值的 SE 约等于 \(s/\sqrt{n}\)。
- n 增大通常让 SE 变小,但不会自动改变 SD。