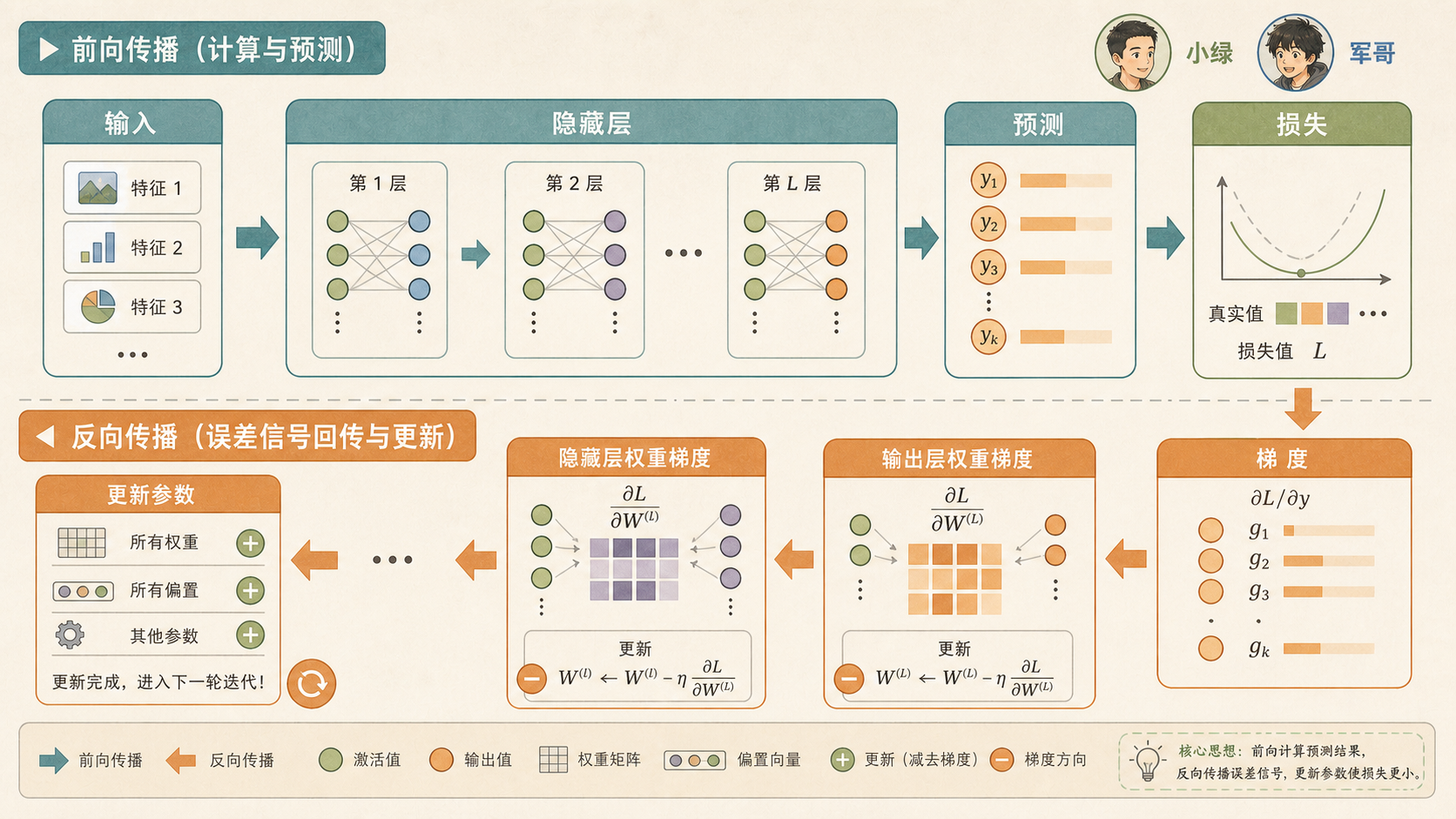
15.3 反向传播¶
小率在烘焙店尝了一口蛋糕:“太甜,还有点干。”均哥没有直接把蛋糕丢掉,而是拿出配方表:糖少一点,牛奶多一点,烤箱温度降一点,搅拌时间也要调整。
深度学习训练也是这样。模型先做出预测,损失函数(Loss Function)告诉它“错了多少”;反向传播(Backpropagation)再把这个错误沿着网络往回传,告诉每个参数该往哪个方向改。
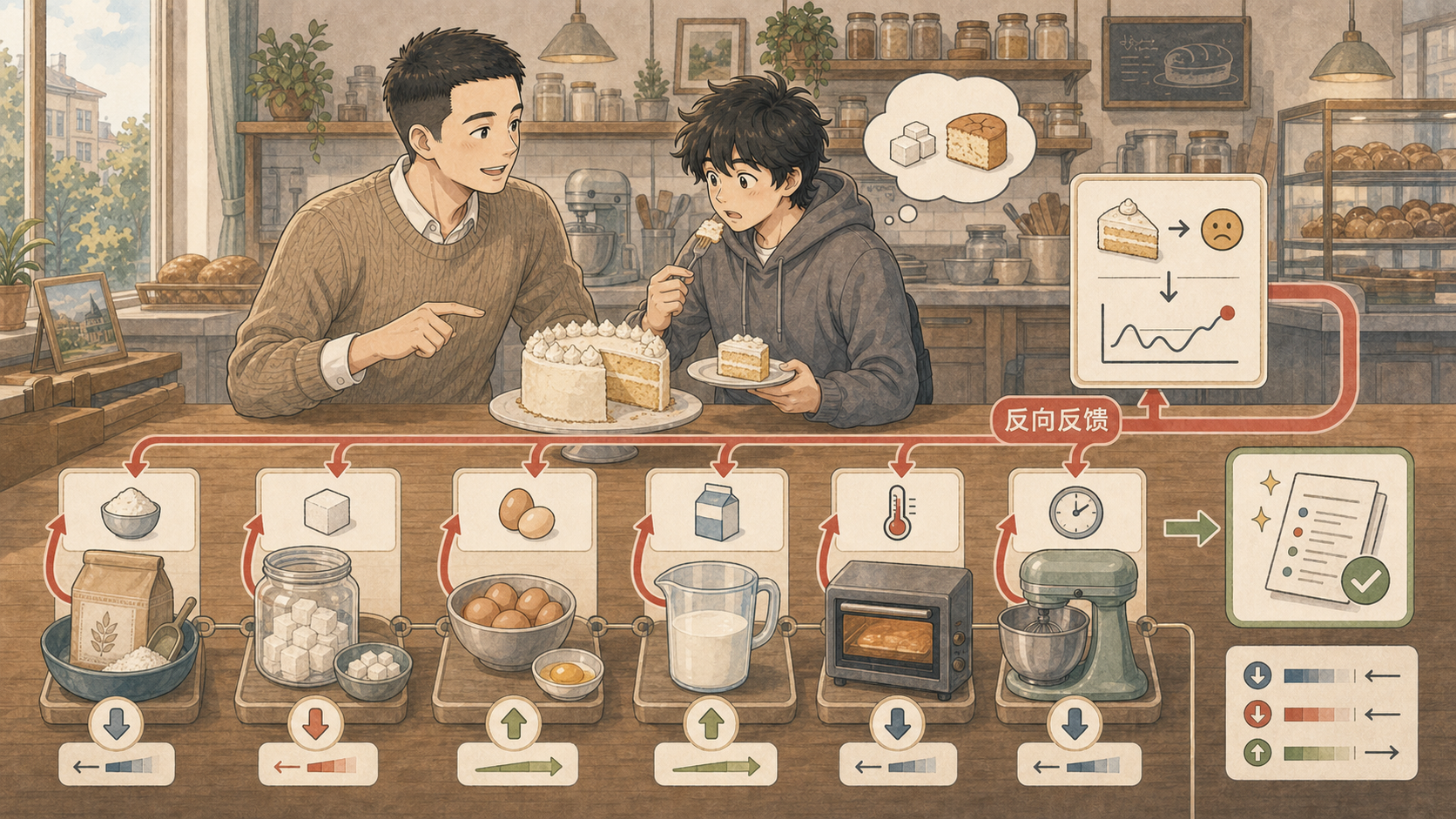
15.3.1 损失先给出最后的反馈¶
假设蛋糕甜度预测值是 \(\hat{y}\),真实期望是 \(y\)。回归任务常用均方误差(Mean Squared Error):
\[
L = \frac{1}{2}(\hat{y}-y)^2
\]
为什么前面有 \(\frac{1}{2}\)?因为求导后会抵消平方带来的 2,让式子更清爽:
\[
\frac{\partial L}{\partial \hat{y}} = \hat{y}-y
\]
这个导数就是“最后输出应该往哪边动”的信号。
15.3.2 链式法则把反馈传回每一层¶
如果网络只有一个神经元:
\[
\hat{y} = wx + b
\]
那么参数的梯度是:
\[
\frac{\partial L}{\partial w}
= \frac{\partial L}{\partial \hat{y}}
\frac{\partial \hat{y}}{\partial w}
= (\hat{y}-y)x
\]
\[
\frac{\partial L}{\partial b}
= \hat{y}-y
\]
多层网络只是把这件事重复很多次。后面一层的误差信号,乘上当前层的局部导数,就能得到当前层该怎么改。
15.3.3 梯度下降像小步改配方¶
得到梯度后,参数更新通常写成:
\[
w \leftarrow w - \eta \frac{\partial L}{\partial w}
\]
其中 \(\eta\) 是学习率(Learning Rate)。学习率太小,改配方很慢;学习率太大,可能越改越离谱。
import torch
torch.manual_seed(0)
x = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[2.2], [4.1], [6.0], [8.2]])
model = torch.nn.Linear(1, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
loss_fn = torch.nn.MSELoss()
for epoch in range(80):
y_hat = model(x)
loss = loss_fn(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("weight:", float(model.weight))
print("bias:", float(model.bias))
常见误解
反向传播不是“从答案里偷看规则”,它只是用链式法则计算梯度。真正决定模型学到什么的,是数据、模型结构、损失函数和优化过程。
小率的笔记本
前向传播负责得到预测,损失函数负责衡量错误,反向传播负责把错误分配给每个参数,优化器负责按梯度更新参数。四件事连起来,才叫一次训练迭代。