5.3 抽样分布¶
均哥让小率想象一个电池工厂:同一批电池有成千上万节,每节寿命不同。小率第一次抽 30 节,平均寿命是 998 小时;第二次再抽 30 节,平均可能变成 1006 小时。问题来了:这些「样本平均值」本身会形成怎样的分布?

为什么每次样本均值都不同
不是计算错了,而是样本本来就是随机的。抽样分布研究的不是某一次样本,而是“反复抽样时统计量怎样波动”。
5.3.1 一次样本不是抽样分布¶
我已经有 30 节电池的数据了,画它们的直方图不就是抽样分布吗?
不是。那叫样本数据分布。抽样分布要把“抽 30 节并算均值”这件事重复很多次。
三个分布要分清:
| 名称 | 里面放的是什么 | 是否真实看到 |
|---|---|---|
| 总体分布 | 所有电池寿命 | 通常看不到完整总体 |
| 样本数据分布 | 这一次抽到的 30 个寿命 | 看得到 |
| 抽样分布 | 很多次样本均值 \(\bar{X}\) | 概念上重复,电脑可模拟 |
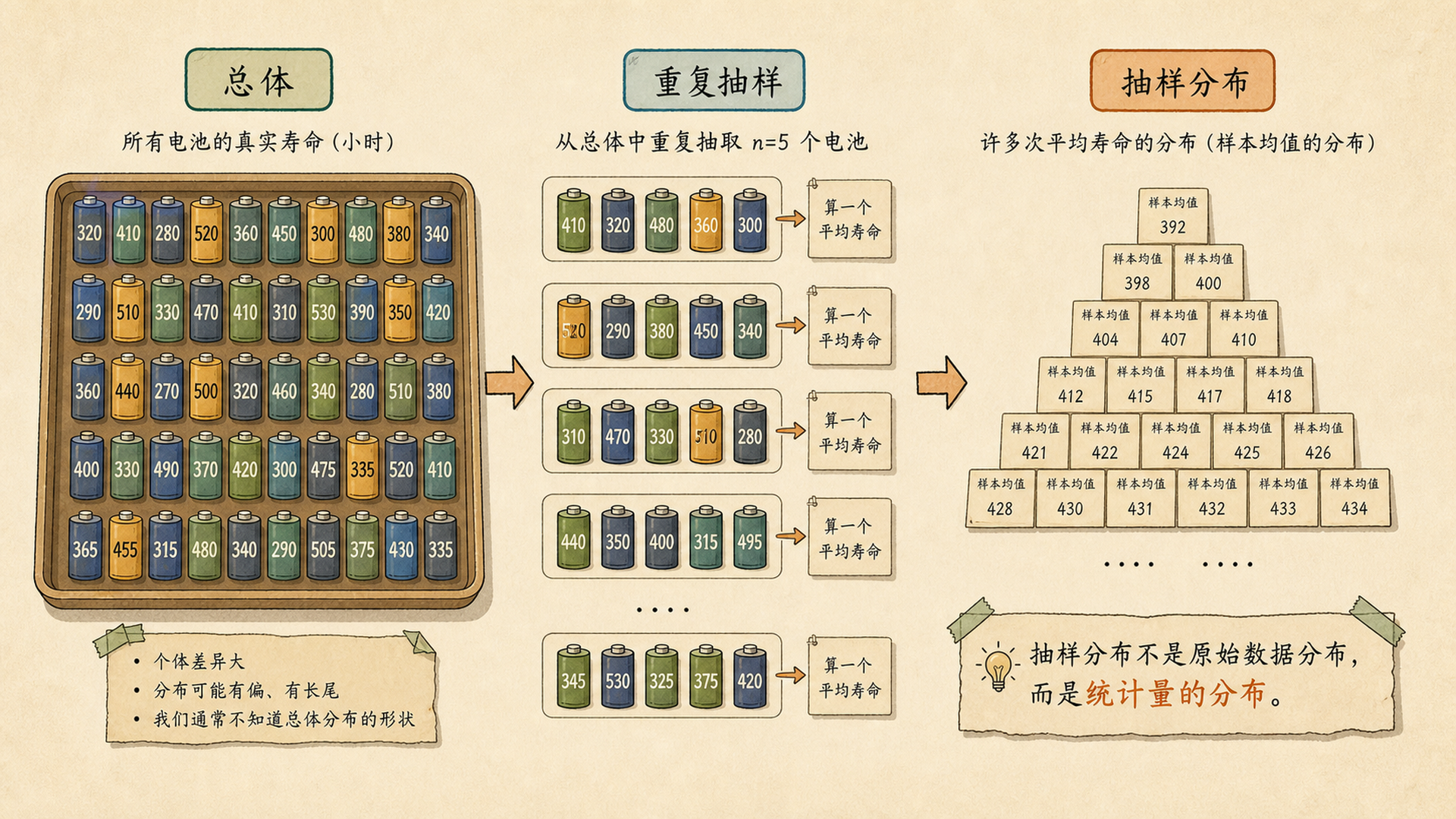
5.3.2 统计量也是随机变量¶
样本均值 \(\bar{X}\) 是由随机样本算出来的,所以它本身也是随机变量。
\[
\bar{X}=\frac{X_1+X_2+\cdots+X_n}{n}
\]
如果抽样无偏,样本均值的长期中心会落在总体均值上:
\[
E[\bar{X}] = \mu
\]
如果个体标准差是 \(\sigma\),样本均值的波动大小是:
\[
\mathrm{SE}(\bar{X})=\frac{\sigma}{\sqrt{n}}
\]
所以 $\bar{X}$ 不是一个固定答案,而是一群可能答案?
对。抽样分布就是这些可能答案的地图。
5.3.3 电脑上重跑 5000 次抽样¶
import numpy as np
rng = np.random.default_rng(2026)
# 拟真总体:电池寿命,右偏但均值有限
population = rng.gamma(shape=8, scale=125, size=100_000)
true_mean = population.mean()
sample_means = []
for _ in range(5000):
sample = rng.choice(population, size=30, replace=False)
sample_means.append(sample.mean())
sample_means = np.array(sample_means)
print(f"总体均值 μ ≈ {true_mean:.1f}")
print(f"抽样分布中心 ≈ {sample_means.mean():.1f}")
print(f"抽样分布标准差 SE ≈ {sample_means.std(ddof=1):.1f}")
看见抽样分布的办法
真实世界不可能倒带 5000 次,但电脑模拟可以帮我们看见“如果反复抽样,会发生什么”。这就是后面理解标准误差和置信区间的入口。
5.3.4 不只均值有抽样分布¶
任何由样本算出的统计量都有抽样分布:中位数、样本比例、样本方差、回归系数、相关系数都一样。第 6 章和第 7 章的估计与检验,都是在问:这个统计量在重复抽样中会怎样波动。
常见误解
抽样分布不是“样本很大时才有”。只要统计量来自随机样本,它就有抽样分布;样本量越大,只是抽样分布通常越窄。
小率的笔记本
- 样本数据分布:一次抽样里的个体值。
- 抽样分布:反复抽样后统计量的分布。
- \(\bar{X}\) 是随机变量,中心是 \(\mu\),波动是 \(\sigma/\sqrt{n}\)。
- 推断的本质,是用抽样分布描述估计的不确定性。