8.4 回归诊断¶
本节学习目标
- 用 残差图 检验线性、同方差、独立、正态
- 识别 离群值、高杠杆点、强影响点
- 掌握 修正方法 : 变换、加权、稳健回归
8.4.1 \(R^2 = 0.78\) 也救不了的客单价模型¶
某电商团队上线了一版 预测客单价 ** 的 OLS 模型,\(R^2 = 0.78\),老板满意,PPT 上线。 三个月后报表对不上:高消费用户的预测严重 ** 系统性偏低 ,而几个超级 VIP 的成交把整个模型的斜率整体抬偏了,普通用户预测又系统性偏高。 数据科学家回头看才发现:
- 残差画出来呈 喇叭形 :客单越大,预测误差越大(异方差)
- 残差对拟合值还有 轻微 U 形 :模型漏了一项非线性
- 几个 VIP 是 强影响点 :删掉他们重跑,斜率从 0.42 掉到 0.31
\(R^2 = 0.78\) 这个漂亮数字什么也没保护——OLS 的 BLUE 假设悄悄被违反了。 本节的故事就是: 线拟好之后,必须做体检 。 不做诊断的回归就像不复盘的交易:盈亏全是运气。
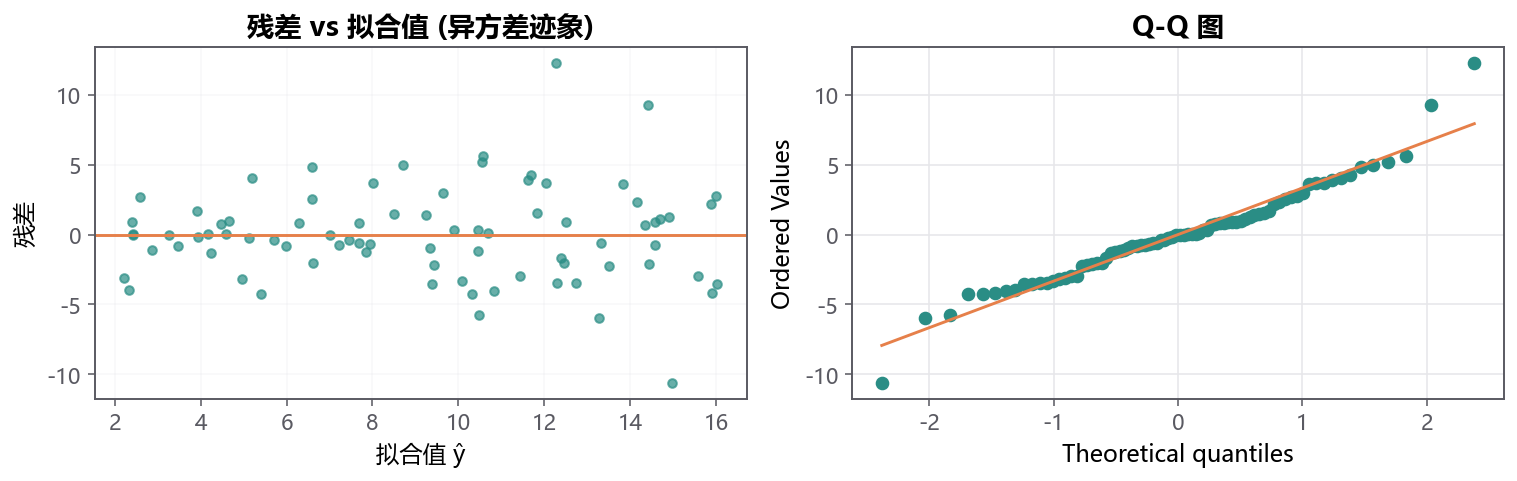
8.4.2 残差图与 Q-Q 图上的『指纹』¶
回到 §8.2 列的五条假设:线性、独立、同方差、正态、无强影响点。 怎么知道哪条破了?最有力的工具不是哪个 p 值,而是 两张图 :
- 残差 vs 拟合值 :横轴是模型预测 \(\hat{y}\),纵轴是残差 \(e\)。 理想情况下应该是一片『随机散布在 0 周围、宽窄一致』的云。
- Q-Q 图 :把残差按大小排序,与正态分布的理论分位数对比。 理想是一条直线。
每种『违反』在这两张图上都有自己的指纹:
- U 形 / 倒 U 形 → 漏了非线性项
- 喇叭形(左窄右宽) → 异方差
- 明显的趋势或周期 → 自相关 / 漏变量
- Q-Q 两端翘 → 重尾、有离群
下面的动画把这几种『指纹』并排放出来,让你一眼就能学会读图。
8.4.3 检查清单¶
把直觉落到一张表格——五条假设、对应的诊断手段、常见的修复方案:
| 假设 | 诊断 | 修正 |
|---|---|---|
| 线性 | 残差 vs 拟合值 | 加多项式、log 变换 |
| 独立 | Durbin-Watson、ACF | 时间序列模型 (ARIMA) |
| 同方差 | 残差 vs \(\hat{y}\) 散点;Breusch-Pagan | log Y、WLS、Huber-White 稳健 SE |
| 正态 | Q-Q 图、Shapiro | 大样本 CLT 救场,或 bootstrap |
| 无强影响点 | Cook's \(D\)、leverage | 稳健回归;删点要慎重 |
下面把表里的关键统计量逐个解释。
8.4.4 杠杆、学生化残差、Cook 距离¶
杠杆 (leverage) \(h_{ii}\) :第 \(i\) 个观测对自身预测 \(\hat{y}_i\) 的拉力。 \(X\) 离均值越远,\(h_{ii}\) 越大。 经验阈值:\(h_{ii} > 2(p+1)/n\) 视为高杠杆。
学生化残差 :把残差按局部尺度标准化,
\(|t_i| > 3\) 视为离群。
Cook 距离 :把『杠杆 + 残差大小』合成一个『删点影响力』指标——
\(D_i > 4/n\) 是经验报警线。 强影响点 = 高杠杆 + 大残差 ;只高杠杆但残差不大,并不一定致命。
8.4.5 异方差与自相关¶
Breusch-Pagan 检验 :把残差平方对 \(X\) 回归,看是否显著:
显著 → 拒绝同方差。 White 检验 是它的更通用版(含交叉项),不依赖具体分布。
Durbin-Watson 统计量 (检验一阶自相关):
DW \(\approx 2\) → 无自相关;DW \(< 1.5\) 或 \(> 2.5\) 警惕。 时间序列残差自相关 → 改用 ARMA / GLS。
正态性 ** 用 Shapiro-Wilk 与 Q-Q 图配合。 注意: 大样本下 Shapiro 极易拒** (任何小偏离都显著),但 OLS 推断对正态偏离 本来就稳健 ,不必苛求。
8.4.6 异常值的三步走¶
发现某点 Cook \(D = 0.5\)、\(|t_i| = 5\),怎么办?冲动是『删了重跑』,但这是数据造假的开场。 正确流程:
- 确认是不是录入错误 :打错小数点、单位混淆——这种优先剔。
- 评估影响 :删除前后对比 \(\hat{\beta}\) 与 \(R^2\),量化它对模型的贡献。
- 决策 :
- 真实但极端 → 用 稳健回归 (Huber、RANSAC、分位数回归),保留点但降权
- 报告时 透明声明 处理过程
陷阱:看不顺眼就删
挑掉所有让 \(R^2\) 不好看的点,等于给数据剃掉胡子。 模型在论文上漂亮,落地就翻车。 任何点的删除都必须有 业务上 的理由,而不是 统计上的方便 。
8.4.7 诊断到修正的工作动线¶
这一节工具多,给一条工作动线:
- 看图先于看数 :残差 vs \(\hat{y}\)、Q-Q、Cook D 三张图过一遍
- 哪条假设破了 → 选对应修正
- 非线性 → 加多项式(§8.6)/ 样条 / GAM
- 异方差 → log 变换、WLS、HC3 稳健 SE
- 自相关 → ARIMA / GLS(→ 第 12 章)
- 强影响点 → 稳健回归、Huber、RANSAC
- 修正后重诊断 ——一次没解决就再来一轮
应用场景
所有上线前的回归模型都该走一遍诊断:信用打分、价格弹性、医疗剂量响应、房价估值、用户 LTV 预测——任何决策依赖『系数解读』或『预测区间』的场合,没做诊断的模型都是黑盒赌博。
8.4.8 BP 检验、DW 与 Cook 距离实测¶
import numpy as np, statsmodels.api as sm
import matplotlib.pyplot as plt
from statsmodels.stats.diagnostic import het_breuschpagan
from statsmodels.stats.stattools import durbin_watson
from scipy import stats
rng = np.random.default_rng(0)
n = 80
x = rng.uniform(0, 10, n)
y = 2 + 1.5*x + rng.normal(0, 1.5 + 0.3*x, n) # 异方差
X = sm.add_constant(x)
m = sm.OLS(y, X).fit()
e = m.resid
# 异方差
bp = het_breuschpagan(e, X)
print(f"BP test p = {bp[1]:.4f}") # < 0.05 → 异方差
# DW
print(f"Durbin-Watson = {durbin_watson(e):.2f}")
# 正态
print(f"Shapiro p = {stats.shapiro(e).pvalue:.3f}")
# 影响点
inf = m.get_influence()
cooks = inf.cooks_distance[0]
print(f"max Cook's D = {cooks.max():.3f}")
# 修正: 用稳健 SE 重跑
m_robust = sm.OLS(y, X).fit(cov_type='HC3')
print(m_robust.summary())
最后那行 cov_type='HC3' 是『懒人福音』:系数估计完全不变,但 SE 与 p 值都被换成对异方差稳健的版本,几乎是默认就该开。
8.4.9 稳健回归¶
当『删不删』成了难题,把决策权交给 稳健回归 :
- Huber 损失 :小残差用平方(高效),大残差用线性(不被极端点拽歪)
- RANSAC :随机采样找最大内点集,对高离群率非常友好
- 分位数回归 :拟合中位数(而不是均值),天然抗异常值
from sklearn.linear_model import HuberRegressor
hr = HuberRegressor().fit(x.reshape(-1,1), y)
print(hr.coef_, hr.intercept_)
你知道吗
Cook 距离的提出者 R. Dennis Cook 在 1977 年发表的那篇论文里只有 4 页,定义出奇简洁,却成了现代回归诊断的核心工具之一。 它的精妙在于把『移除一个点对所有预测的总扰动』压成一个标量——你不需要真把每个点删一遍重跑 \(n\) 次模型,公式里 \(h_{ii}\) 已经把这件事代数化了。
8.4.10 本节小结¶
- 一定要看 残差图 + Q-Q + Cook D ,而不是只看 \(R^2\)。
- 异方差用 WLS / 稳健 SE(HC3 几乎是默认),自相关用 GLS / ARIMA。
- 异常值要 诊断而非盲删 :录入错→删;真实但极端→稳健回归。
- 大样本下正态性偏离不必苛求;模型修正后 必须重诊断 。
- 下节 §8.5 把回归扩展到 二分类问题 :逻辑回归。