8.8 小结¶
学完本章你应能:
- 区分相关与因果, 计算并解读 r
- 拟合简单/多元线性回归, 解读系数与 \(R^2\)
- 做诊断 (残差图、Cook D、VIF) 并修正
- 使用逻辑回归处理二分类
- 用多项式 + 正则化在过/欠拟合之间找平衡
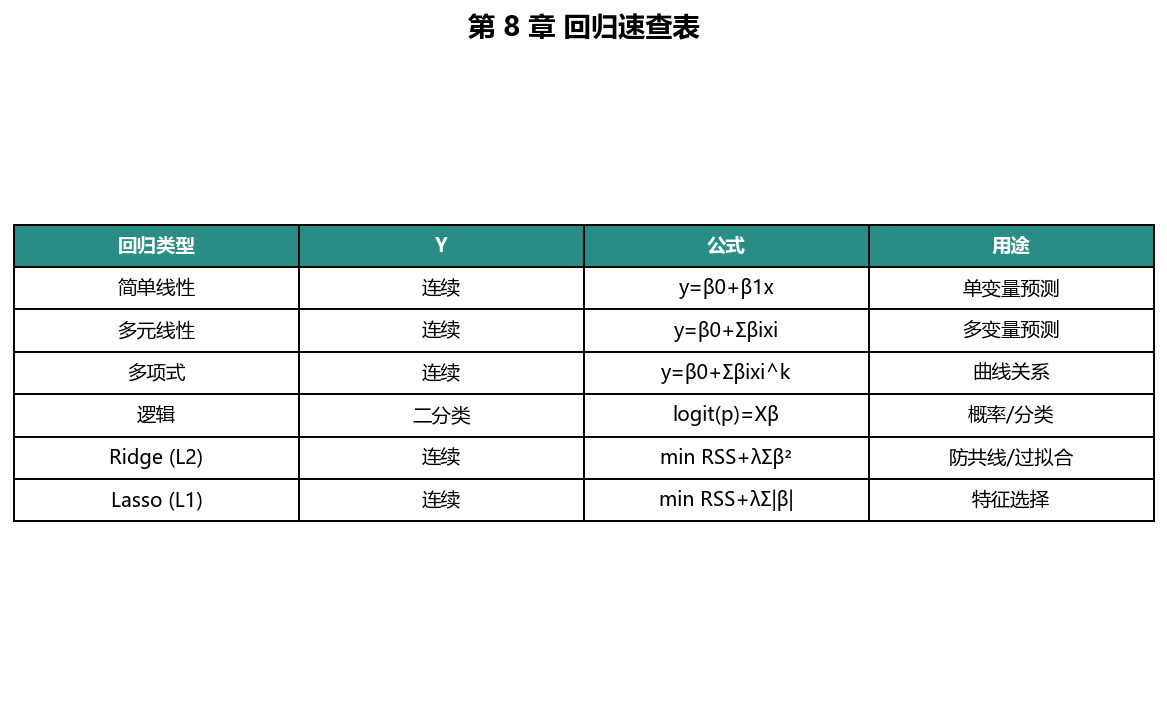
8.8.1 第 8 章 cheatsheet¶
8.8.2 概念地图¶
X 与 Y 关系?
│
┌───────────────┼─────────────────┐
│ │
仅相关 (§8.1) 建模 Y = f(X)
│
┌─────────────────────────┴───────────────┐
Y 连续 Y 二分类
│ │
┌───────┴───────┐ 逻辑回归 (§8.5)
线性 (§8.2/8.3) 非线性 (§8.6) │
│ 评估: AUC/F1/混淆
诊断 (§8.4) ─→ 异方差/非正态/影响点
│
过拟合? → 正则化 (§8.7) Ridge / Lasso / EN
8.8.3 速查公式¶
OLS 闭式 : \(\hat{\beta} = (X^\top X)^{-1} X^\top y\)
\(R^2\) : \(1 - \text{SSE}/\text{SST}\), 多元用 adj-\(R^2\)
系数 t: \(t = \hat{\beta}_j / \text{SE}(\hat{\beta}_j) \sim t_{n-p-1}\)
整体 F: \(F = (\text{SSR}/p) / (\text{SSE}/(n-p-1))\)
VIF: \(1/(1 - R_j^2)\), > 5 警惕
Cook D: \(\dfrac{e_i^2}{(p+1)s^2} \cdot \dfrac{h_{ii}}{(1-h_{ii})^2}\)
Logit: \(\log(p/(1-p)) = X\beta\), OR \(= e^{\beta}\)
Ridge: \(\hat{\beta} = (X^\top X + \lambda I)^{-1} X^\top y\)
8.8.4 图¶
预测变量 Y 类型?
├─ 连续 → 线性回归 family
│ ├─ 关系曲线? → 多项式/样条/GAM (§8.6)
│ ├─ 多变量+共线/过拟合? → Ridge/Lasso/EN (§8.7)
│ ├─ 异方差? → WLS / 稳健 SE (§8.4)
│ └─ 时间序列? → 第 12 章
└─ 二分类 → 逻辑回归 (§8.5)
└─ K 类 → 多项式逻辑 / 第 14 章 ML
8.8.5 Top 7 误区¶
误区 1: r 高就有因果
永远先想混杂、反向、巧合。
误区 2: R² 越高模型越好
加变量必涨; 看 adj-R²、CV、AIC; 警惕过拟合。
误区 3: 不看残差图就定稿
诊断比 R² 重要 10 倍。
误区 4: 系数显著就重要
大样本下小系数也能显著, 看效应大小。
误区 5: 多重共线下用 OLS 系数解释
系数不稳, 该用 Ridge 或剔变量。
误区 6: 二分类用 OLS
用逻辑回归; OLS 概率会越界。
误区 7: 正则化前不标准化
各变量尺度差异巨大, 罚不平衡, 结果错。
8.8.6 综合大题¶
某电商收集 500 用户数据, 预测下单概率与下单金额。
(a) 想预测金额 (连续), 5 个连续 + 2 个分类自变量, 怎么开始?
→ OLS 多元 + 哑变量编码; 看 adj-\(R^2\)、F、VIF; 残差诊断。
(b) 发现残差喇叭形, 怎么办?
→ log(amount) 变换 + 重新拟合, 或 WLS, 或 HC3 稳健 SE。
© 30 个候选变量, 想选最有解释力的 5-10 个?
→ Lasso CV; 标准化后跑, 看非零系数; 或前向 stepwise (老派)。
(d) 改预测"是否下单"二分类?
→ Logistic 回归; 看 OR; 用 ROC-AUC 评估; 不平衡数据用加权或 SMOTE。
(e) AUC=0.78 算好吗?
→ 业务 OK; 关注阈值平衡精确召回; 与 baseline 对比 (随机=0.5, 业务规则可能 0.7)。
8.8.7 综合自测¶
练习 8.8.1
简单线性回归 \(\hat{y} = 3 + 2x\), 残差 SE = 1.5, \(R^2 = 0.7\), n=30。 X=5 时给出预测和 95% PI (粗略)。
参考答案
\(\hat{y} = 13\)。 PI ≈ 13 ± 2.05 × 1.5 × √(1 + 1/30 + 小项) ≈ 13 ± 3.1 = [9.9, 16.1]。
练习 8.8.2
逻辑回归 logit(p) = -2 + 0.5·X. X=4 时 P(Y=1)?
参考答案
z = -2 + 2 = 0, p = 1/(1+1) = 0.5。
练习 8.8.3
Lasso CV 选出 λ=0.1, 5 个非零系数。 接下来该?
参考答案
用这 5 个变量做常规 OLS (即"post-Lasso"或"relaxed Lasso") 得无偏系数, 用于解释; Lasso 本身系数有偏。
8.8.8 下章预告¶
第 9 章关键词:
- 单因素 ANOVA & SST 分解
- F 分布与 F 检验
- 双因素 + 交互效应
- 事后比较: Tukey HSD, Bonferroni, Scheffé
- 实验设计基本原则: 重复、随机化、区组化
8.8.9 练一练¶
本章核心练习题汇总。建议先动笔再看参考答案。
练习 8.1.1
研究发现『家里书多的孩子学习成绩好』。 这意味着多买书能提高成绩吗?
参考答案
不一定。 家庭社会经济地位是混杂: 有钱、重视教育的家庭既会买书, 也会以其他方式支持学习。 RCT (随机给一些家庭送书) 才能证明因果。
练习 8.1.2
判断: 当 r=0 时, X 与 Y 一定独立。
参考答案
错。 r=0 只意味着无线性关系。 例: \(Y = X^2\), \(X \sim\) 对称分布, 则 r=0 但 X 与 Y 函数依赖。
练习 8.2.1
n=20 数据求得 \(\hat{\beta}_1 = 2.5, \text{SE} = 0.6\)。 95% CI? 显著吗?
参考答案
df = 18, t* ≈ 2.101。 CI = 2.5 ± 2.101×0.6 = [1.24, 3.76]。 不含 0 → 显著。
练习 8.2.2
R² = 0.6 意味着模型预测精度有多高?
参考答案
R² 度量解释方差比, 不是预测准确率。 R²=0.6 即解释 60% 总变异; 残差还占 40%。 实际预测精度看 RMSE / 残差 SE。
练习 8.3.1
area 系数 0.3 (SE=0.05) p<0.001, bedrooms 系数 -2 (SE=10) p=0.84 — 矛盾吗?
参考答案
不矛盾。 bedrooms 系数大但 SE 也大, 可能与 area 高度共线 (大房子卧室多)。 检查 VIF; 若高, 二选一保留。
练习 8.3.2
模型 A 用 5 变量 R²=0.65, 模型 B 用 8 变量 R²=0.68。 谁更好?
参考答案
要看 adj-R². 若调整后 A>B, 说明多加 3 个变量贡献微小, 应选 A (更简单, 防过拟合)。
练习 8.4.1
残差 vs ŷ 图呈 U 形, 怎么改?
参考答案
模型缺非线性项。 加二次项 \(X^2\) 或对 X、Y 做 log 变换 (若值正)。
练习 8.4.2
某点 leverage h=0.4, 学生化残差 = 0.2, Cook D=?
参考答案
高杠杆但残差小 → Cook D 不大。 D 同时需要大残差才大。 高杠杆点未必是强影响点。
练习 8.5.1
系数 \(\beta = -0.5\), 解读?
参考答案
OR = \(e^{-0.5} \approx 0.61\)。 X 每增 1, 几率乘以 0.61, 即下降 39%。 反向影响。
练习 8.5.2
AUC=0.50 与 AUC=0.95 各意味着什么?
参考答案
0.50 = 完全瞎猜 (随机模型水平); 0.95 = 模型对正负样本排序非常好 (顶级模型)。 一般业务 AUC>0.7 可用, >0.8 优秀。
练习 8.6.1
用 d=8 拟合 30 个数据点, 训练 R² = 0.999, 测试 R² = 0.4。 诊断?
参考答案
严重过拟合。 30 数据用 8 次约 9 参数, 自由度太低。 改 d=2 或 3, 或加正则化 (Ridge)。
练习 8.6.2
样条相比高次多项式有什么优势?
参考答案
分段低次, 局部灵活而无 Runge 震荡; 节点位置可控; 易加平滑惩罚。
练习 8.7.1
用 OLS R²(训) = 0.95, R²(测) = 0.62; 用 Ridge 在 λ=1 时 R²(训) = 0.85, R²(测) = 0.78。 选谁?
参考答案
选 Ridge。 测试集是真衡量泛化能力的; OLS 过拟合明显, Ridge 偏差略升但方差大降, 整体更优。
练习 8.7.2
Lasso 把 50 个变量中 45 个的系数压到 0, 这意味着什么?
参考答案
模型实际只用 5 个变量。 它们是被 Lasso 视为最有解释力的; 但不能直接说其他 45 个无意义 (可能与选中的 5 个共线 → 被替代)。