11.4 判别分析¶
植物园的实践作业里,小率拿到一批花的测量记录:花萼长、花萼宽、花瓣长、花瓣宽,并且每朵花已经知道类别。他不只是想画图,而是想找一条最能把类别分开的方向。

PCA 找的是方差最大方向。可我现在有类别标签,能不能找“最会分类”的方向?
这就是判别分析。它让类与类尽量远,让同一类内部尽量紧。
11.4.1 PCA 看散布,LDA 看分开¶
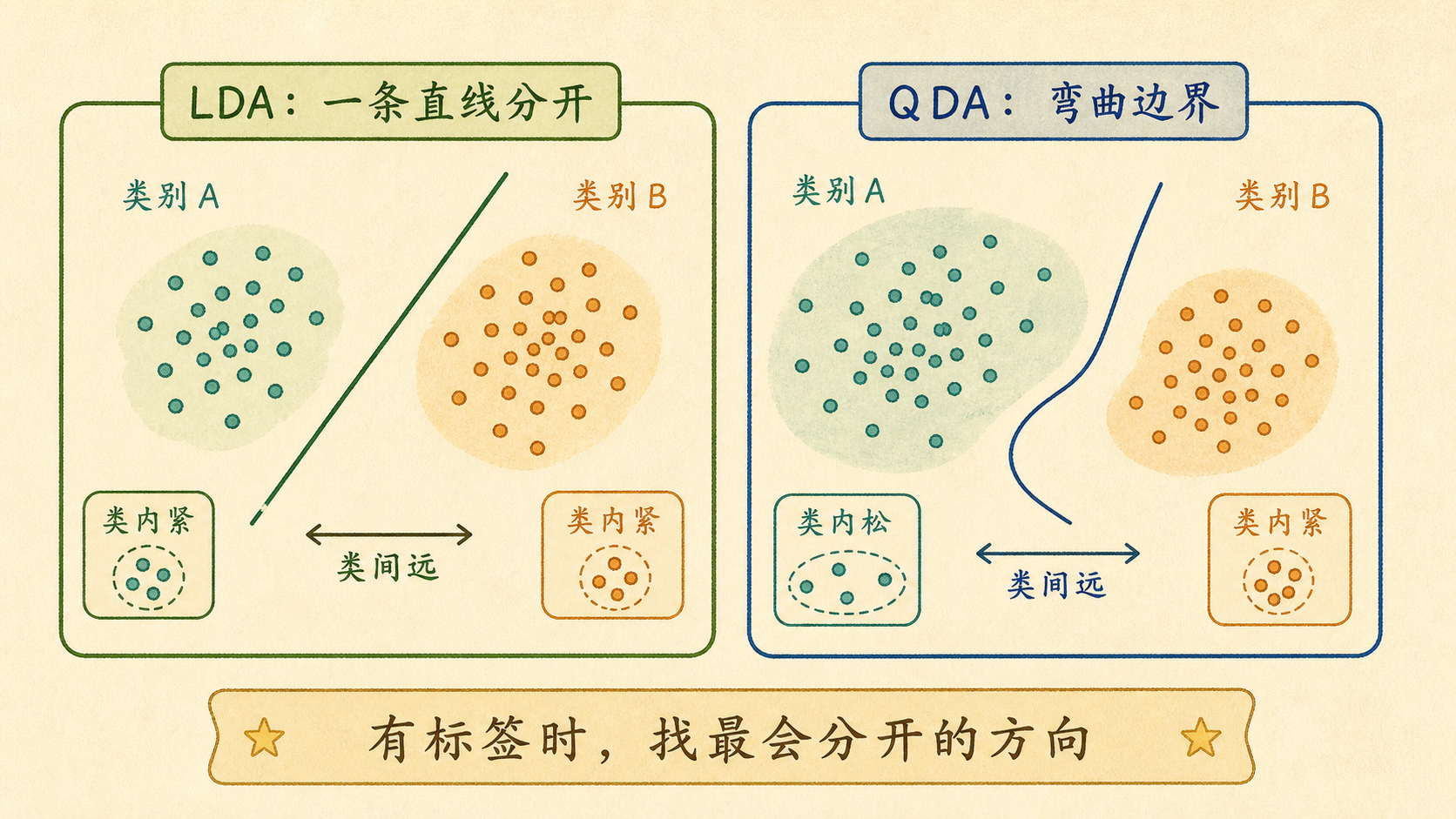
线性判别分析(Linear Discriminant Analysis, LDA)和 PCA 都能降维,但目标不同:
- PCA 不看标签,只找整体方差最大的方向。
- LDA 看标签,找最能分开类别的方向。
- QDA 允许不同类别有不同协方差,因此边界可以弯曲。
11.4.2 Fisher 准则:类间远,类内紧¶
设要找投影方向 \(w\)。投影后,我们希望:
- 不同类别的中心距离大。
- 同一类别内部散布小。
类间散布矩阵:
\[
S_B=\sum_k n_k(\mu_k-\mu)(\mu_k-\mu)^\top
\]
类内散布矩阵:
\[
S_W=\sum_k\sum_{x_i\in C_k}(x_i-\mu_k)(x_i-\mu_k)^\top
\]
Fisher 准则写成:
\[
J(w)=\frac{w^\top S_B w}{w^\top S_W w}
\]
分子希望大,分母希望小,所以就是“类间远 / 类内紧”。
你已经抓到 LDA 的心脏了。
11.4.3 LDA 的概率视角¶
LDA 也可以从贝叶斯分类推出来。假设每个类别内部都服从多元正态分布,并且共享同一个协方差矩阵:
\[
X\mid Y=k\sim N(\mu_k,\Sigma)
\]
此时类别 \(k\) 的判别函数是:
\[
\delta_k(x)=x^\top\Sigma^{-1}\mu_k-\frac12\mu_k^\top\Sigma^{-1}\mu_k+\log\pi_k
\]
把样本分给 \(\delta_k(x)\) 最大的类别。
两个视角一件事
Fisher 视角强调“投影后最分开”;概率视角强调“共享协方差的高斯分类”。在 LDA 里,它们会走到同一个分类规则。
11.4.4 QDA 为什么会弯¶
二次判别分析(Quadratic Discriminant Analysis, QDA)放宽了 LDA 的共享协方差假设:
\[
X\mid Y=k\sim N(\mu_k,\Sigma_k)
\]
每一类都有自己的协方差矩阵,决策函数里保留二次项,所以边界可以弯曲。它更灵活,但参数更多,小样本时更容易过拟合。
| 方法 | 边界 | 假设 | 风险 |
|---|---|---|---|
| LDA | 线性 | 各类共享协方差 | 欠拟合复杂边界 |
| QDA | 二次 | 各类协方差不同 | 小样本过拟合 |
11.4.5 用 Python 比较 LDA 和 QDA¶
完整脚本放在:
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.model_selection import cross_val_score
X, y = load_iris(return_X_y=True)
lda = LinearDiscriminantAnalysis(n_components=2)
Z = lda.fit_transform(X, y)
lda_score = cross_val_score(lda, X, y, cv=5).mean()
qda = QuadraticDiscriminantAnalysis()
qda_score = cross_val_score(qda, X, y, cv=5).mean()
print("LDA 投影形状:", Z.shape)
print("LDA 交叉验证准确率:", round(lda_score, 3))
print("QDA 交叉验证准确率:", round(qda_score, 3))
11.4.6 和逻辑回归怎么选¶
| 问题 | LDA/QDA | 逻辑回归 |
|---|---|---|
| 建模对象 | \(X\mid Y\) | \(Y\mid X\) |
| 假设 | 类内近似正态 | 对分布要求少 |
| 小样本 | LDA 常较稳 | 也可用正则化 |
| 可视化 | LDA 投影很直观 | 不主打降维 |
需要注意
LDA 最多只能降到 \(K-1\) 维,其中 \(K\) 是类别数。二分类 LDA 只有一条判别轴。
小率的笔记本
PCA 找整体方差最大的方向,LDA 找类别最分开的方向。LDA 适合共享协方差、线性边界;QDA 允许弯曲边界,但更吃样本量。已有标签且目标是分类时,LDA 常常比 PCA 更贴题。