2.8 偏度与峰度¶
小率已经会看中心,也会看离散。可他盯着一张外卖等待时间图,还是觉得哪里不对。
大多数订单 10 分钟以内就送到了,少数订单却拖到 35 分钟、45 分钟,甚至 90 分钟。均值被拉高了,标准差也变大了,但这些数字都没有直接说出一个很重要的事实:
这组数据右边拖着一条长长的尾巴。

描述统计不只要回答“中心在哪里”“散得多开”,还要回答:
- 分布是不是歪的?
- 尾巴是不是很长?
- 极端值是不是更容易出现?
这就是偏度(Skewness)和峰度(Kurtosis)要处理的问题。
到这里,我们已经有了中心和离散两个视角。但很多数据光有这两个视角还不够。两组数据的均值和标准差可能差不多,一组左右对称,另一组却右边拖着长尾;它们带来的风险和解释完全不同。偏度和峰度,就是为了补上“形状”这块拼图。
2.8.1 偏度:分布往哪边拖尾¶
偏度(Skewness) 描述分布的不对称程度。
如果右侧拖着长尾,就叫右偏;如果左侧拖着长尾,就叫左偏;如果左右差不多,就近似对称。
| 形状 | 直觉 | 常见例子 |
|---|---|---|
| 右偏 | 大多数值较小,少数特别大 | 工资、房价、等待时间、医疗费用 |
| 近似对称 | 左右形状接近 | 稳定工艺下的容量误差、测量误差 |
| 左偏 | 大多数值较大,少数特别小 | 容易考试中的高分集中、设备寿命接近上限时 |
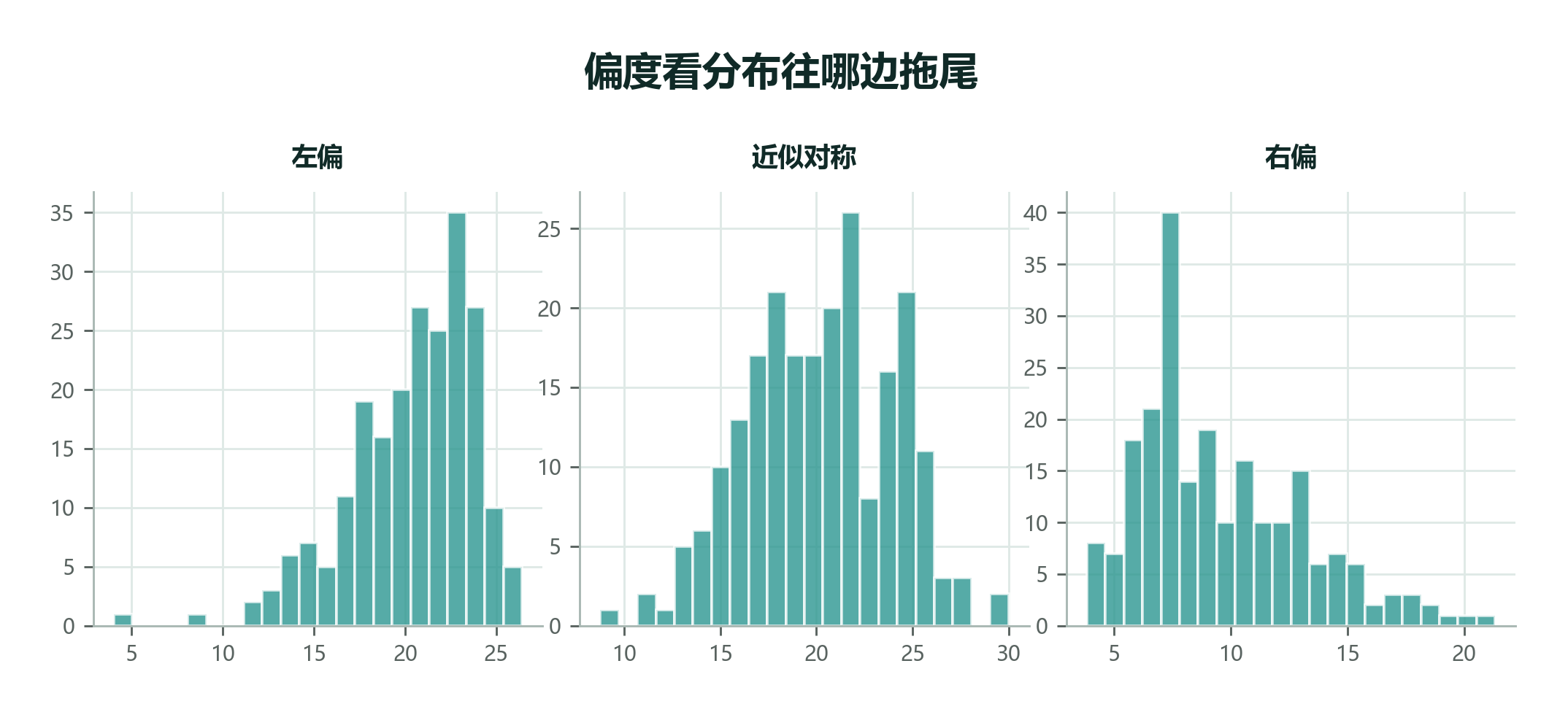
右偏数据里,均值往往大于中位数。不是因为均值算错了,而是因为右侧少数大值把它拉过去了。
判断偏度的第一步永远是看图,而不是急着算一个偏度系数。初学时可以先记住三种画面:
- 右边拖长尾:少数特别大的值把尾巴拉向右边。
- 左边拖长尾:少数特别小的值把尾巴拉向左边。
- 左右差不多:分布大致对称。
如果右偏很明显,均值通常会被拉到中位数右边;如果左偏很明显,均值通常会被拉到中位数左边。这是读图时很有用的快速判断。
2.8.2 右偏数据为什么常见¶
生活里很多数据天然有下限,却没有严格上限。
等待时间不能小于 0 分钟,但可能因为堵车、漏单、暴雨拖到很久。月薪不能低于 0,但少数高薪岗位可能非常高。医疗费用多数人不高,但少数重症病例费用会很大。
这类数据很容易右偏。
右偏数据最容易带来两个误会:
- 只看均值,会高估大多数人的典型体验。
- 只看标准差,会知道“波动大”,但不知道波动主要来自右侧长尾。
所以遇到右偏数据,常见报告方式是:
- 先画直方图或箱线图。
- 报告中位数和 IQR。
- 必要时说明极端值来源。
- 如果后续要建模,再考虑对数变换。
右偏数据还有一个生活化特征:多数人的体验集中在“普通范围”,少数人的体验特别极端。比如大多数外卖 30 分钟内送达,但少数订单可能等 90 分钟;大多数网页获得几十次点击,但少数爆款文章获得几十万次点击。
这时只报平均数会让普通体验显得比实际更高。更完整的说法应该像这样:
这批订单的中位送达时间是 24 分钟,IQR 是 18 到 32 分钟;少数订单超过 60 分钟,使均值上升到 31 分钟。
这句话同时告诉读者主体和长尾,比单独说“平均 31 分钟”诚实得多。
2.8.3 峰度:重点是尾巴,不只是峰顶¶
峰度(Kurtosis) 常被误解成“峰顶有多尖”。这只说对了一小部分。
更实用的理解是:峰度提醒我们尾部有多重,极端值是否更容易出现。
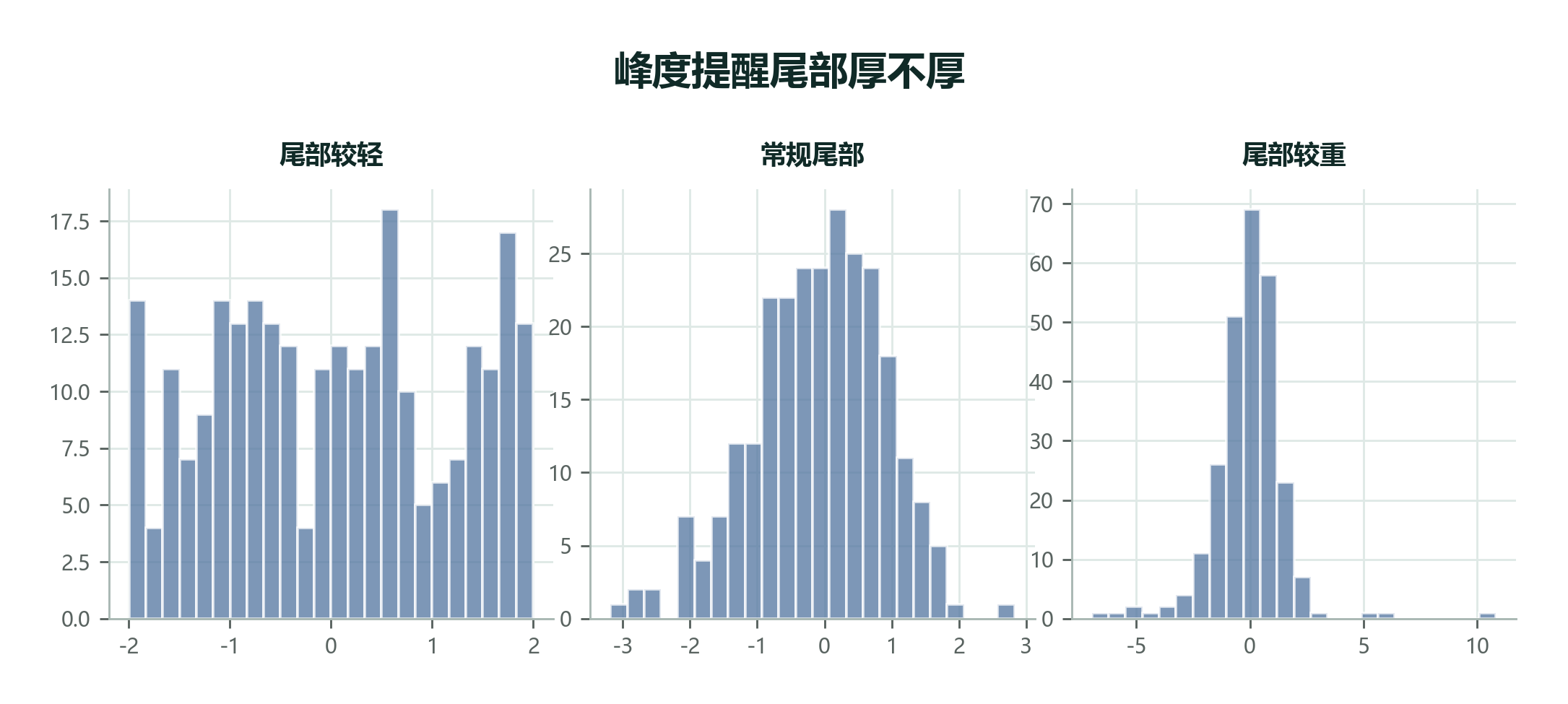
为什么这很重要?
因为很多现实风险不在“中间”,而在“尾巴”。
- 平均送达时间不错,但少数订单特别久,会影响差评。
- 平均收益不错,但少数极端亏损,可能让账户承受不了。
- 平均设备寿命够长,但少数设备很早坏,会影响售后。
峰度不是让我们欣赏曲线尖不尖,而是提醒我们:尾部事件要不要认真对待。
峰度不是只看峰顶
很多教材把峰度画成“尖峰”和“平峰”,容易让人误以为它只关心中间有多尖。实际使用时,更应该把它理解为尾部厚度和极端值风险的信号。
对初学者来说,峰度不必一开始就背公式。更重要的是知道它在提醒什么:有些分布平时看起来很安静,但尾部事件并不少见。金融收益、网络流量、保险赔付、设备故障时间,都可能存在这种“平时普通,偶尔极端”的特征。
2.8.4 对数变换:换一个尺度看右偏数据¶
当数据严重右偏时,直接使用均值和标准差可能很难代表主体。
一种常见做法是对数变换。
比如等待时间:
原始尺度上,90 比 9 大 10 倍,长尾很明显。取对数后,大值会被压缩,小值之间的差异也会更容易比较。
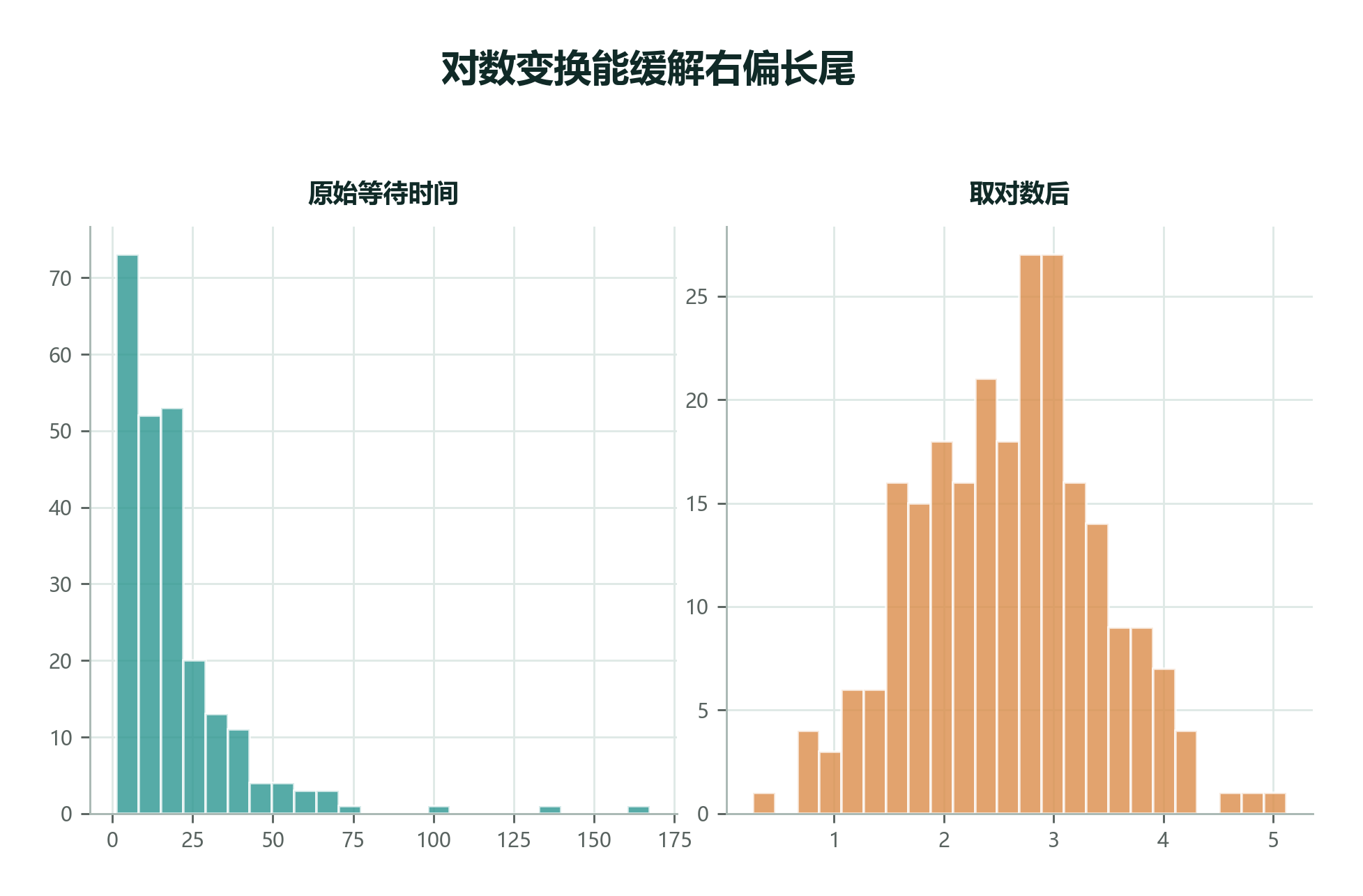
实用搭配
右偏长尾数据先报告中位数和 IQR;如果后续要建模,可以考虑对数变换,并在报告中清楚说明原始尺度和变换尺度的含义。
对数变换特别适合“倍数关系比差值关系更自然”的数据。比如收入从 3000 到 6000,是翻倍;从 30000 到 33000,虽然也差 3000,但生活意义完全不同。原始尺度看差值,对数尺度更接近看倍数。
但变换后解释要小心。你不能只说“对数等待时间平均是多少”,读者听不懂。更好的做法是:在建模或计算时使用对数尺度,在报告时再翻译回原始单位,比如“典型等待时间约为 20 分钟,长尾订单明显存在”。
2.8.5 形状指标不能代替画图¶
偏度和峰度很有用,但它们不是万能摘要。
两组数据可能偏度、峰度接近,图形却不完全一样;也可能因为样本量太小,偏度和峰度非常不稳定。
所以更稳妥的顺序是:
- 先画直方图、密度图或箱线图。
- 再看中位数、IQR、均值和标准差。
- 最后用偏度、峰度补充描述形状。
描述统计里,图形常常是第一眼,指标是第二句话。
这条原则非常重要。偏度和峰度把形状压成两个数字,压缩就一定会丢信息。双峰、断层、群体混合、少量异常值,都可能让单个形状指标变得难解释。图形不是可有可无的配图,而是判断这些指标能不能相信的前提。
2.8.6 用 Python 计算偏度和峰度¶
import numpy as np
from scipy.stats import skew, kurtosis
rng = np.random.default_rng(28)
wait_time = rng.lognormal(mean=2.5, sigma=0.8, size=200)
print(f"偏度 = {skew(wait_time):.2f}")
print(f"超额峰度 = {kurtosis(wait_time):.2f}")
print(f"中位数 = {np.median(wait_time):.1f}")
print(f"均值 = {wait_time.mean():.1f}")
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/08_skewness_and_kurtosis.py,可以复现偏度、峰度和对数变换示例。
小率的笔记本
- 偏度描述分布是否不对称,以及尾巴拖向哪边。
- 右偏数据中,均值常被长尾拉到中位数右侧。
- 峰度更应理解为尾部厚度和极端值风险,而不只是峰顶尖不尖。
- 对数变换可以缓解右偏,但必须说明变换方式和解释尺度。
- 形状指标要配合图形使用,不能只看一个数字就下结论。
- 描述长尾数据时,尽量同时报告主体范围和少数极端情况。