12.5 预测与评估¶
奶茶店准备下周备料。小率想给出一个数字,均哥却让他同时给出一段范围:未来越远,不确定性越大,只报一个点容易让人误会。

店长问我下周卖多少杯,我直接给预测值不就行了吗?
点预测有用,但区间更诚实。它告诉对方:这不是确定答案,而是带不确定性的判断。
12.5.1 点预测回答“最可能是多少”¶
点预测 (Point Forecast) 给出一个未来值,例如:
\[
\hat{y}_{T+h}
\]
其中 \(h\) 是预测步长。\(h=1\) 表示预测下一期,\(h=7\) 表示预测 7 期后。
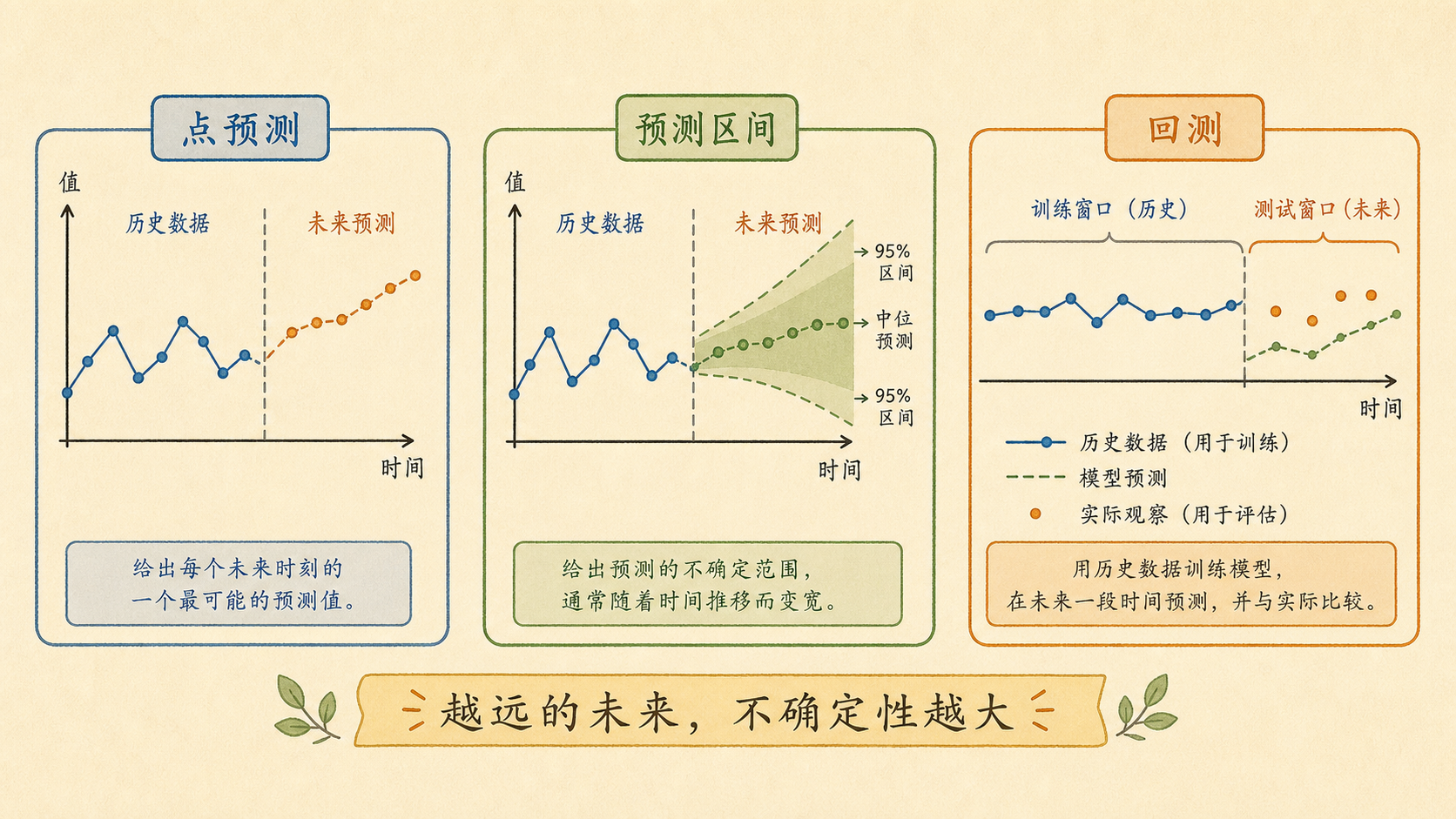
12.5.2 预测区间回答“可能落在哪”¶
预测区间 (Prediction Interval) 会把未来误差也考虑进去:
\[
\hat{y}_{T+h} \pm z_{\alpha/2}\operatorname{SE}(\hat{y}_{T+h})
\]
通常 \(h\) 越大,预测区间越宽。因为越远的未来,累积不确定性越多。
点预测和预测区间的区别
点预测像“最可能的一杯数”。
预测区间像“准备原料时要留的安全范围”。
做决策时,两者最好一起看。
12.5.3 回测要像真正预测未来¶
时间序列不能随机切训练集和测试集。正确做法是用过去训练,预测后面,再不断向前滚动。
常见评估指标:
| 指标 | 含义 | 注意点 |
|---|---|---|
| MAE | 平均绝对误差 | 单位和原数据相同,容易解释 |
| RMSE | 均方根误差 | 对大误差更敏感 |
| MAPE | 平均绝对百分比误差 | 真实值接近 0 时会不稳定 |
| MASE | 相对朴素模型的误差 | 便于跨序列比较 |
12.5.4 先打败朴素基线¶
一个预测模型至少要赢过简单基线:
- 朴素预测:下一期等于上一期。
- 季节朴素预测:下一期等于上一个周期同位置。
- 移动平均:用最近几期平均值预测。
import numpy as np
import pandas as pd
from sklearn.metrics import mean_absolute_error
from statsmodels.tsa.holtwinters import ExponentialSmoothing
rng = np.random.default_rng(12)
dates = pd.date_range("2021-01-01", periods=60, freq="MS")
t = np.arange(len(dates))
sales = pd.Series(
220 + 2 * t + 20 * np.sin(2 * np.pi * t / 12) + rng.normal(0, 7, len(t)),
index=dates,
)
train, test = sales.iloc[:-12], sales.iloc[-12:]
fit = ExponentialSmoothing(train, trend="add", seasonal="add", seasonal_periods=12).fit()
forecast = fit.forecast(12)
seasonal_naive = train.iloc[-12:].to_numpy()
print("ETS MAE:", round(mean_absolute_error(test, forecast), 2))
print("季节朴素 MAE:", round(mean_absolute_error(test, seasonal_naive), 2))
完整脚本见:
别把未来信息漏进训练集
用全量数据做标准化、调参、特征选择,再切测试集,会让模型提前看见未来。时间序列评估里,这是最常见也最隐蔽的错误。
小率的笔记本
预测要同时给点和区间。
评估要按时间向前滚动,不能随机打散。
好模型必须先打败朴素基线,再谈复杂方法。