7.7 卡方检验¶
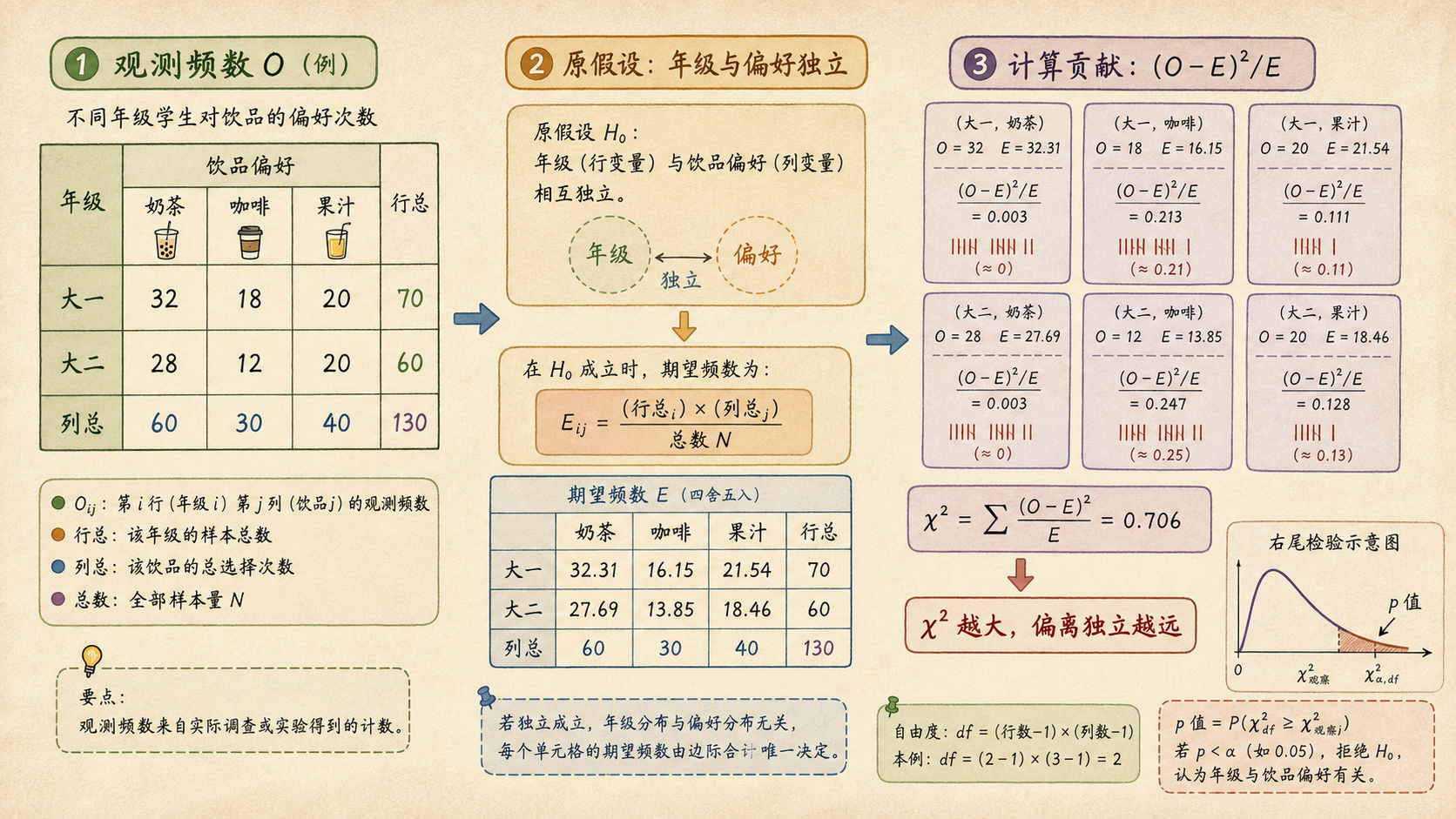
小率把社团问卷摊在桌上:高一、高二、高三同学各自喜欢的饮品不一样。有人说「年级越高越爱咖啡」,也有人说「只是样本碰巧」。这类问题不能用均值去比,因为数据不是身高、成绩、等待时间,而是一格一格的**人数**。

年级和饮品偏好有关吗
如果年级与饮品偏好完全无关,那么每个年级里喜欢奶茶、咖啡、果汁的比例应该差不多。卡方检验要问:实际看到的人数,和「无关」时应该看到的人数,差得够不够大?
| 年级 | 奶茶 | 咖啡 | 果汁 | 合计 |
|---|---|---|---|---|
| 高一 | 26 | 9 | 15 | 50 |
| 高二 | 21 | 17 | 12 | 50 |
| 高三 | 13 | 28 | 9 | 50 |
| 合计 | 60 | 54 | 36 | 150 |
7.7.1 先想象「完全无关」会长什么样¶
卡方检验(Chi-square Test)处理的是分类数据。它最常见的两种用法是:
- 拟合优度检验(Goodness-of-fit Test):一个分类变量是否符合某个理论比例,例如骰子 1 到 6 是否均匀。
- 独立性检验(Test of Independence):两个分类变量是否有关,例如年级与饮品偏好是否有关。
这节先看独立性检验。原假设写成:
如果 \(H_0\) 成立,高一共有 50 人,全体 150 人里有 60 人喜欢奶茶,那么高一喜欢奶茶的期望人数就是:
也就是「行总 × 列总 / 总数」。
7.7.2 χ² 统计量:把每格偏差加起来¶
记观测频数为 \(O\),期望频数为 \(E\)。卡方统计量是:
为什么要平方?因为高了和低了都表示偏离,不能互相抵消。为什么除以 \(E\)?因为偏差 5 人在期望 10 人的格子里很大,在期望 200 人的格子里就不算大。
对于 \(r\) 行 \(c\) 列的列联表,自由度是:
本例是 \(3 \times 3\) 表,自由度 \(df=(3-1)(3-1)=4\)。
需要注意
卡方检验依赖大样本近似。经验规则是多数期望频数最好不小于 5;如果 2×2 小表里期望频数太小,可以考虑 Fisher 精确检验。
7.7.3 拟合优度:只有一行时也能用¶
如果只有一个分类变量,比如一颗骰子掷了 60 次,观测次数是:
| 点数 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 次数 | 8 | 12 | 9 | 11 | 10 | 10 |
公平骰子的期望次数都是 10。此时:
自由度是类别数减 1,也就是 \(df=5\)。这个偏差很小,没有足够证据说骰子不公平。
7.7.4 Python 复现社团问卷¶
完整脚本见:docs/assets/scripts/ch07_hypothesis_testing/07_chi_square_test/main.py。
import numpy as np
from scipy import stats
table = np.array([
[26, 9, 15],
[21, 17, 12],
[13, 28, 9],
])
chi2, p, df, expected = stats.chi2_contingency(table)
print(f"χ² = {chi2:.2f}, df = {df}, p = {p:.4f}")
print(np.round(expected, 2))
obs = np.array([8, 12, 9, 11, 10, 10])
chi2_dice, p_dice = stats.chisquare(obs, f_exp=np.repeat(10, 6))
print(f"骰子拟合优度: χ² = {chi2_dice:.2f}, p = {p_dice:.4f}")
如果社团问卷的 p 值很小,意思是:在「年级与饮品偏好独立」这个世界里,看到这么大偏离的概率很低。我们倾向于认为年级和饮品偏好有关。
小率的笔记本
卡方检验不比较均值,而是比较频数。先用 \(H_0\) 计算期望频数 \(E\),再把每格偏差写成 \((O-E)^2/E\)。χ² 越大,说明观测表越不像原假设预期的表。