16.2 推荐系统中的统计¶
书店咖啡角里,小率刚给一本小说打了五星,手机就弹出几本相似书和两部电影。均哥问:“它为什么觉得你会喜欢?”小率看了看历史评分、收藏和浏览记录:“它在用过去的行为预测下一次选择。”
推荐系统(Recommendation System)的本质,是在用户、物品和场景之间估计偏好。

16.2.1 推荐先从用户-物品矩阵开始¶
把用户对物品的评分排成矩阵:
| 用户 | 书 A | 书 B | 电影 C | 电影 D |
|---|---|---|---|---|
| 小率 | 5 | ? | 4 | ? |
| 读者甲 | 5 | 4 | ? | 2 |
| 读者乙 | ? | 5 | 4 | 1 |
问号就是要预测的位置。协同过滤(Collaborative Filtering)的直觉是:如果两个人过去喜欢的东西相似,他们未来可能也会喜欢相似的东西。
一个简单的矩阵分解模型写成:
其中 \(\mu\) 是全局平均分,\(b_u\) 是用户偏好偏置,\(b_i\) 是物品受欢迎程度,\(\mathbf{p}_u\) 和 \(\mathbf{q}_i\) 是低维向量。
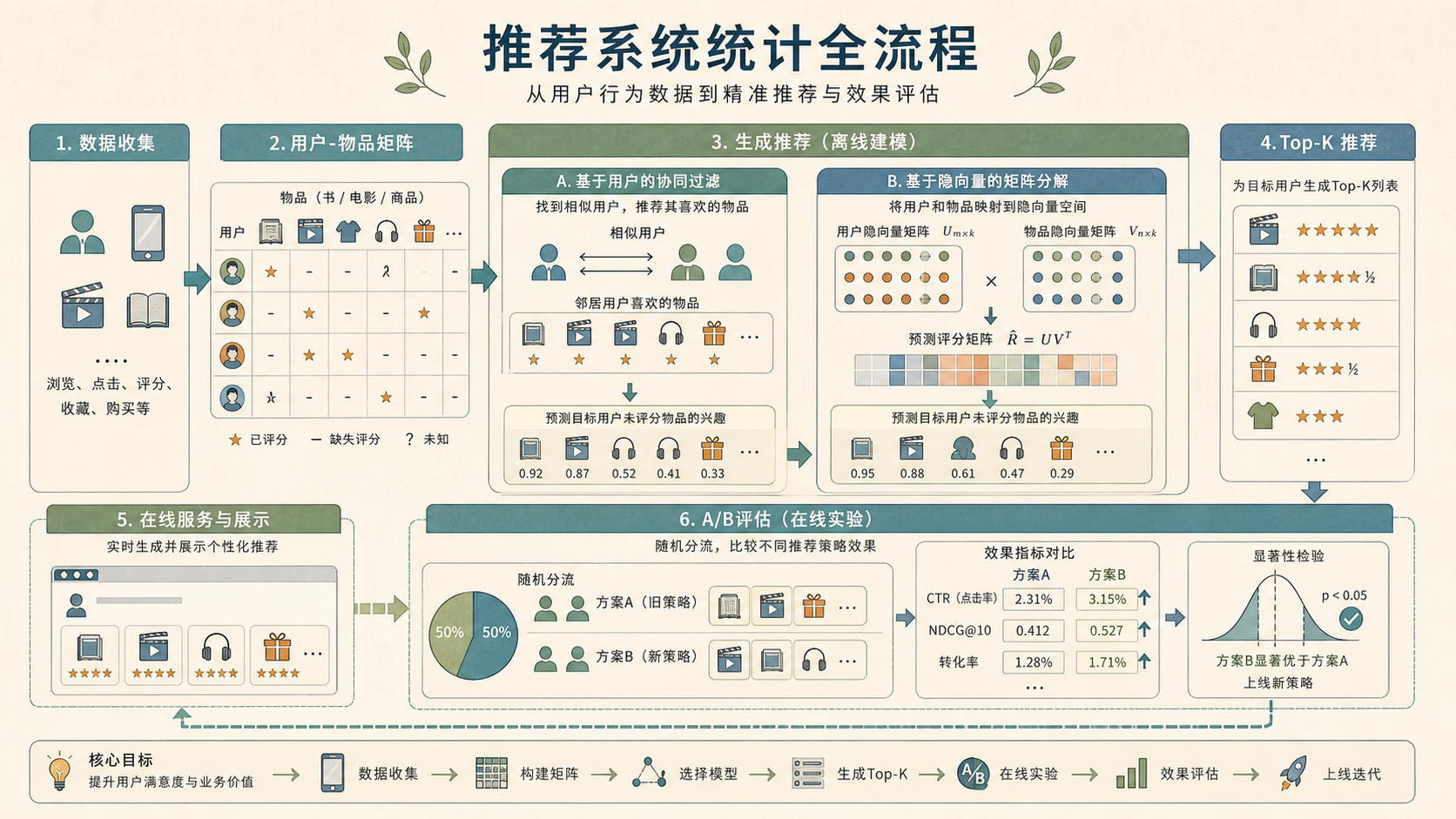
16.2.2 推荐系统通常分成召回和排序¶
实际系统不会对所有物品逐一精算。常见流程是两步:
- 召回(Recall):从海量物品中快速找出几百个候选,例如相似用户喜欢的书、同主题电影、最近热门内容。
- 排序(Ranking):对候选物品精细打分,综合点击概率、购买概率、多样性、新鲜度和业务约束。
这就像书店先把你可能喜欢的书架找出来,再从架子上挑最适合放到你面前的几本。
16.2.3 离线准确不等于线上有效¶
推荐系统常见离线指标包括 RMSE、AUC、Recall@K、NDCG@K。但线上更关心点击率、转化率、停留时长、复购和用户满意度。
曝光偏差很容易藏起来
用户没有点击某个物品,不代表他不喜欢;也可能是系统从未把它展示出来。推荐数据天然带有系统过去策略的偏差。
16.2.4 Top-K 指标更贴近推荐列表¶
如果推荐页只展示 10 个物品,评分预测误差不一定最重要。我们更关心“好东西有没有排到前面”。
| 指标 | 问题 | 直觉 |
|---|---|---|
| Precision@K | 推荐的 K 个里有多少是用户喜欢的 | 少推错 |
| Recall@K | 用户喜欢的物品有多少被找到了 | 少漏掉 |
| NDCG@K | 排得越靠前是否越相关 | 好东西放前面 |
| Coverage | 系统覆盖了多少物品 | 避免只推热门 |
16.2.5 用相似用户做一个小推荐¶
import numpy as np
ratings = np.array([
[5, 0, 4, 0],
[5, 4, 0, 2],
[0, 5, 4, 1],
], dtype=float)
target = ratings[0]
others = ratings[1:]
def cosine(a, b):
mask = (a > 0) & (b > 0)
if mask.sum() == 0:
return 0
return np.dot(a[mask], b[mask]) / (
np.linalg.norm(a[mask]) * np.linalg.norm(b[mask])
)
sims = np.array([cosine(target, row) for row in others])
candidate_item = 1
pred = np.average(others[:, candidate_item], weights=sims)
print("similarities:", sims)
print("predicted rating for book B:", round(pred, 2))
16.2.6 为什么推荐系统需要探索¶
如果系统永远只推“看起来最确定”的物品,用户很难发现新兴趣,冷门物品也永远没有机会被验证。探索-利用(Explore-Exploit)权衡就是:
- 利用:推荐当前模型最有把握的内容。
- 探索:有控制地尝试不确定但可能有价值的内容。
新闻、短视频和新品推荐尤其需要探索,因为内容变化快,旧数据很快过期。
小率的笔记本
推荐系统不只是“猜你喜欢”。它同时涉及预测、排序、探索、偏差校正和 A/B 测试。离线指标是筛选工具,真正上线还要看因果效果和用户体验。