6.1 点估计¶
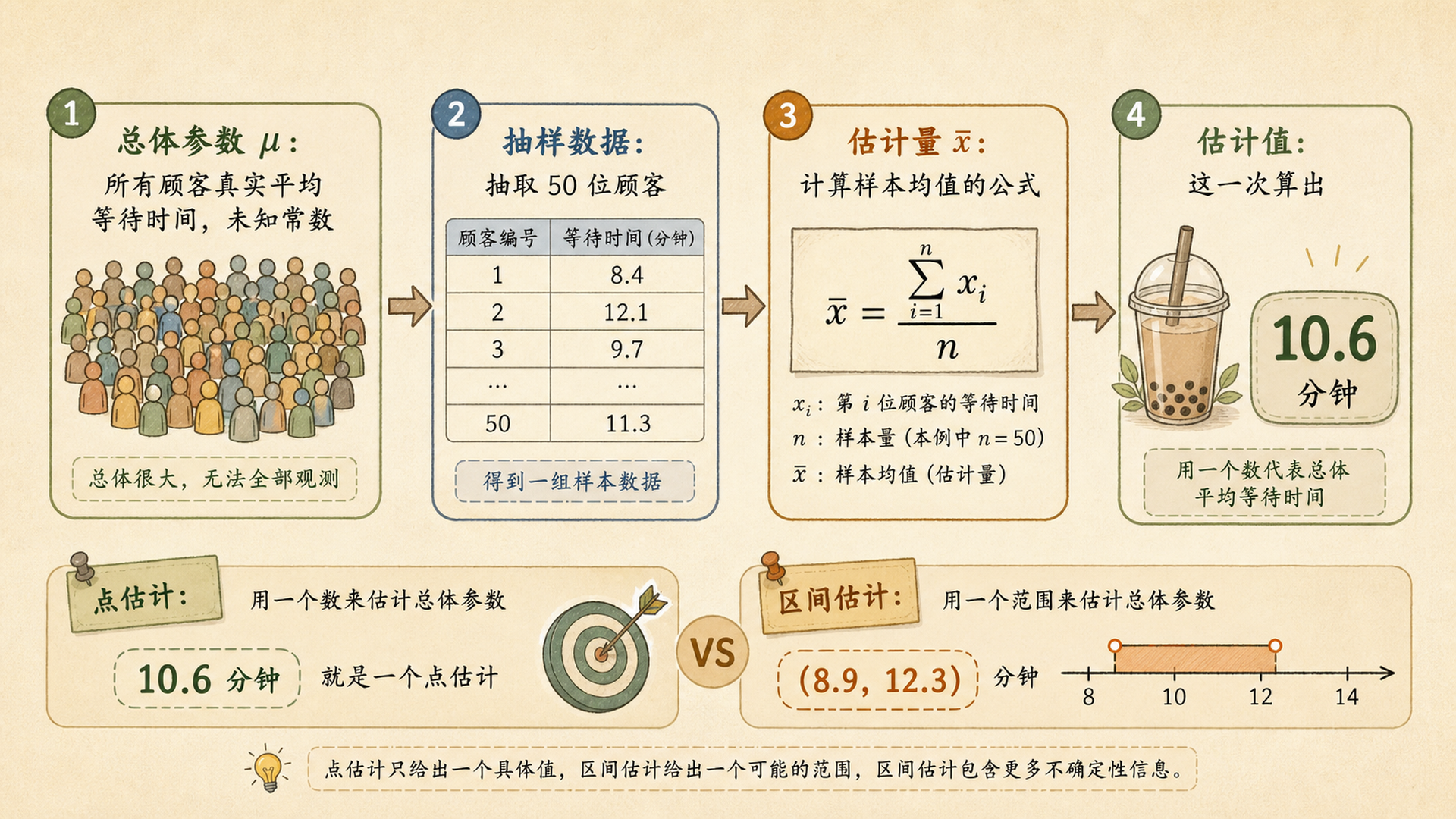
暑假第一天,小率拖着行李箱去找均哥,手里还攥着一张奶茶店小调查。店门口排了很长的队,小率想知道:今天这家店的顾客平均要等多久?
问题是,顾客一直来来走走,不可能把一整天每个人的等待时间都完整记录下来。他只问了 50 位顾客,算出平均等待时间是 10.6 分钟。

这一个数能代表所有顾客吗
小率手上的 10.6 分钟,是从 50 位顾客那里算出来的。它不是总体真值,只是对“所有顾客平均等待时间”的一次猜测。统计学把这种用一个数猜未知参数的做法叫 点估计(Point Estimation)。
| 顾客编号 | 等待时间(分钟) |
|---|---|
| 1 | 8.4 |
| 2 | 12.1 |
| 3 | 9.7 |
| ... | ... |
| 50 | 11.3 |
6.1.1 总体参数藏在看不见的地方¶
先把对象分清楚:
- 总体参数(Parameter):所有顾客真实平均等待时间,记作 \(\mu\)。它是一个固定但未知的数。
- 样本数据(Sample Data):小率问到的 50 位顾客等待时间。
- 统计量(Statistic):只用样本算出来的量,比如样本均值 \(\bar X\)。
- 估计量(Estimator):当一个统计量被用来估计参数时,它就叫估计量。
- 估计值(Estimate):把这一次样本代入公式后得到的具体数字,比如 10.6。
四个名字别混
参数是总体里的未知真值,统计量是样本里算出的量,估计量是用来猜参数的统计量,估计值是某次样本代入后的具体数字。
6.1.2 点估计只给一个答案¶
点估计的核心句子很短:
其中 \(\theta\) 是未知参数,\(\hat\theta\) 是用样本算出来的估计量。
在奶茶等待时间里,最自然的估计量是样本均值:
如果 \(n=50\),样本总等待时间是 530 分钟,那么:
点估计的局限
点估计清爽,但它不会主动告诉你“不确定性有多大”。“平均等待 10.6 分钟”和“平均等待大概在 9 到 12 分钟之间”传达的信息量完全不同。后者就是后面要讲的区间估计。
6.1.3 矩估计法:让样本特征对齐总体特征¶
如果不知道该选什么估计量,可以先用一个朴素办法:矩估计法(Method of Moments)。
它的想法是:
总体的某个特征未知,就用样本里对应的特征去替它。
| 想估的参数 | 总体关系 | 样本替代 |
|---|---|---|
| 均值 \(\mu\) | \(E(X)=\mu\) | \(\hat\mu=\bar X\) |
| 泊松率 \(\lambda\) | \(E(X)=\lambda\) | \(\hat\lambda=\bar X\) |
| 均匀分布上界 \(b\) | \(E(X)=b/2\) | \(\hat b=2\bar X\) |
| 正态方差 \(\sigma^2\) | \(\operatorname{Var}(X)=\sigma^2\) | \(\hat\sigma^2=\frac{1}{n}\sum (X_i-\bar X)^2\) |
6.1.4 用 Python 算一次点估计¶
下面用固定随机种子模拟 50 位顾客等待时间,并计算样本均值。
import numpy as np
rng = np.random.default_rng(2026)
wait_minutes = rng.normal(loc=10.5, scale=2.0, size=50)
wait_minutes = np.clip(wait_minutes, 1, None)
point_estimate = wait_minutes.mean()
print(f"等待时间点估计 = {point_estimate:.2f} 分钟")
print(f"样本量 n = {len(wait_minutes)}")
完整脚本见:
写报告时怎么说
不要只写“平均等待时间为 10.6 分钟”。更好的写法是:“根据抽取的 50 位顾客,平均等待时间的点估计为 10.6 分钟。这个数会随样本变化,后续还需要给出误差范围。”
小率的笔记本
点估计就是用一个样本统计量去猜总体参数。\(\bar X\) 是估计量,10.6 分钟是估计值。点估计简单直观,但一个数字本身不说明不确定性,所以后面还要学习置信区间。