2.1 总体与样本¶
第一章里我们说过,统计学常常是在“不可能全部知道”的情况下做判断。第二章的第一步,就是把这个“不可能全部知道”说清楚:我们真正想了解的是谁?手上实际看到的又是谁?
这两个问题听起来简单,却会决定整份分析靠不靠谱。很多错误结论不是公式算错,而是一开始就把“想研究的对象”和“实际拿到的数据”混在了一起。
2.1.1 一批牛奶到底检查了谁¶
小率和均哥假期去参观一家乳品厂,均哥顺手布置了一个小任务。
均哥的问题
一批盒装牛奶有 100 000 盒。怎样判断这批牛奶质量是否稳定?
小率盯着传送带上密密麻麻的盒装牛奶,突然有点发怵。
在这个故事里,总体(Population) 是我们真正关心的全部对象:这批 100 000 盒牛奶的质量指标,比如每盒牛奶的蛋白质含量、细菌总数或脂肪含量。总体容量记作 \(N\)。
样本(Sample) 是从总体中抽出来、真正被拆开化验的一部分:比如随机抽检的 200 盒牛奶。样本量记作 \(n\)。

这个区分很重要。我们平时说“研究一批牛奶”,听起来像是在研究盒子本身;但真正进入数据表时,每一盒牛奶会变成一行,每个质量指标会变成一列。统计学不是对着传送带发呆,而是把现实对象转成可以记录、比较和汇总的变量值。
| 研究问题 | 总体 | 样本 |
|---|---|---|
| 这批盒装牛奶平均蛋白质含量 | 100 000 盒牛奶的蛋白质含量 | 随机拆检的 200 盒 |
| 这批盒装牛奶细菌总数是否合格 | 100 000 盒牛奶的细菌总数 | 随机送检的若干盒 |
| 一批灯泡平均寿命 | 全批灯泡的寿命 | 抽检到烧坏的 30 只灯泡 |
总体不一定是一群人
总体可以是盒装牛奶的蛋白质含量、灯泡寿命、交易记录、考试成绩,也可以是理论上无限次投掷硬币的结果。关键不是“对象长什么样”,而是“我们关心哪个变量”。
回到这批牛奶,问题不同,总体也会跟着变:
| 小率真正想问的问题 | 这一题里的总体 |
|---|---|
| 这批牛奶蛋白质含量是否稳定 | 100 000 盒牛奶的蛋白质含量 |
| 这批牛奶容量有没有偏少 | 100 000 盒牛奶的实际容量 |
| 这批牛奶是否存在细菌超标风险 | 100 000 盒牛奶的细菌检测结果 |
换句话说,总体不是一个固定模板,而是由研究问题决定的。离开乳品厂以后,同样的思路也可以迁移到班级问卷、考试成绩、交易记录或人口普查里;但在本节这个故事中,我们先牢牢记住:对象是这批牛奶,变量是每盒牛奶身上的质量指标。
2.1.2 样本要像总体的一小张照片¶
样本不是随便拿几盒牛奶凑数。一个好样本应该尽量像总体的缩小版。
如果质检员只拿传送带最外侧、最容易取到的盒装牛奶,可能刚好避开了某个灌装口的问题;如果只抽刚开机时生产的牛奶,也未必能代表整批产品。
这就是 抽样偏差(Sampling Bias):样本的产生方式让某些对象更容易被选中,导致样本不再代表总体。
需要注意
“顺手拿几盒”“只拿最上层”“只检查最容易取到的位置”,都不是可靠的随机抽样。样本不是越方便越好,而是越能代表总体越好。
理想情况下,我们希望使用 随机抽样(Random Sampling):总体中每个对象都有清楚且公平的入选机会。例如把整批牛奶按生产时间、生产线或箱号编号,再用随机数决定抽检哪些盒。
但在真实工作里,样本经常不是完美随机的。仍以牛奶抽检为例:质检员可能只拿最顺手的一箱,只抽某一条生产线,或者只检查刚开机时生产的盒子。它们未必完全不能用,但必须承认限制。
一个实用判断是:样本像不像总体的“小照片”。如果这批牛奶来自早班、午班、晚班三个生产时段,样本最好也覆盖三段;如果来自两条生产线,样本最好不要只来自其中一条;如果有不同箱号和不同批次,抽检也要尽量覆盖这些结构。
2.1.3 参数和统计量:一个在总体里,一个在样本里¶
总体里真正的平均蛋白质含量,我们通常不知道。它叫 参数(Parameter),常用希腊字母表示,例如总体均值 \(\mu\)、总体标准差 \(\sigma\)。
样本里算出来的平均蛋白质含量,我们看得见。它叫 统计量(Statistic),常用拉丁字母表示,例如样本均值 \(\bar{x}\)、样本标准差 \(s\)。
| 想描述谁 | 名称 | 例子 | 常见符号 |
|---|---|---|---|
| 总体 | 参数 Parameter | 整批牛奶真实平均蛋白质含量 | \(\mu, \sigma\) |
| 样本 | 统计量 Statistic | 抽检牛奶算出的平均蛋白质含量 | \(\bar{x}, s\) |
这也是为什么统计学总喜欢区分“真实但未知”和“算得出来但会变”。总体参数像整批牛奶真正的平均蛋白质含量,它就在那里,但我们通常看不见;样本统计量像抽检 200 盒算出来的平均值,它能看见,但换一批样本可能会稍微变动。
以后看到符号时,可以先不急着害怕。问一句就够了:这个符号描述的是总体,还是样本?如果是总体,它通常是我们想知道的目标;如果是样本,它通常是我们手里能算出来的证据。
2.1.4 样本量越大,估计通常越稳¶
抽样会有误差。今天抽检 50 盒牛奶,平均蛋白质含量可能是 3.18 g/100 mL;明天换另一批 50 盒,可能变成 3.22 g/100 mL。这个摇摆叫 抽样误差(Sampling Error)。
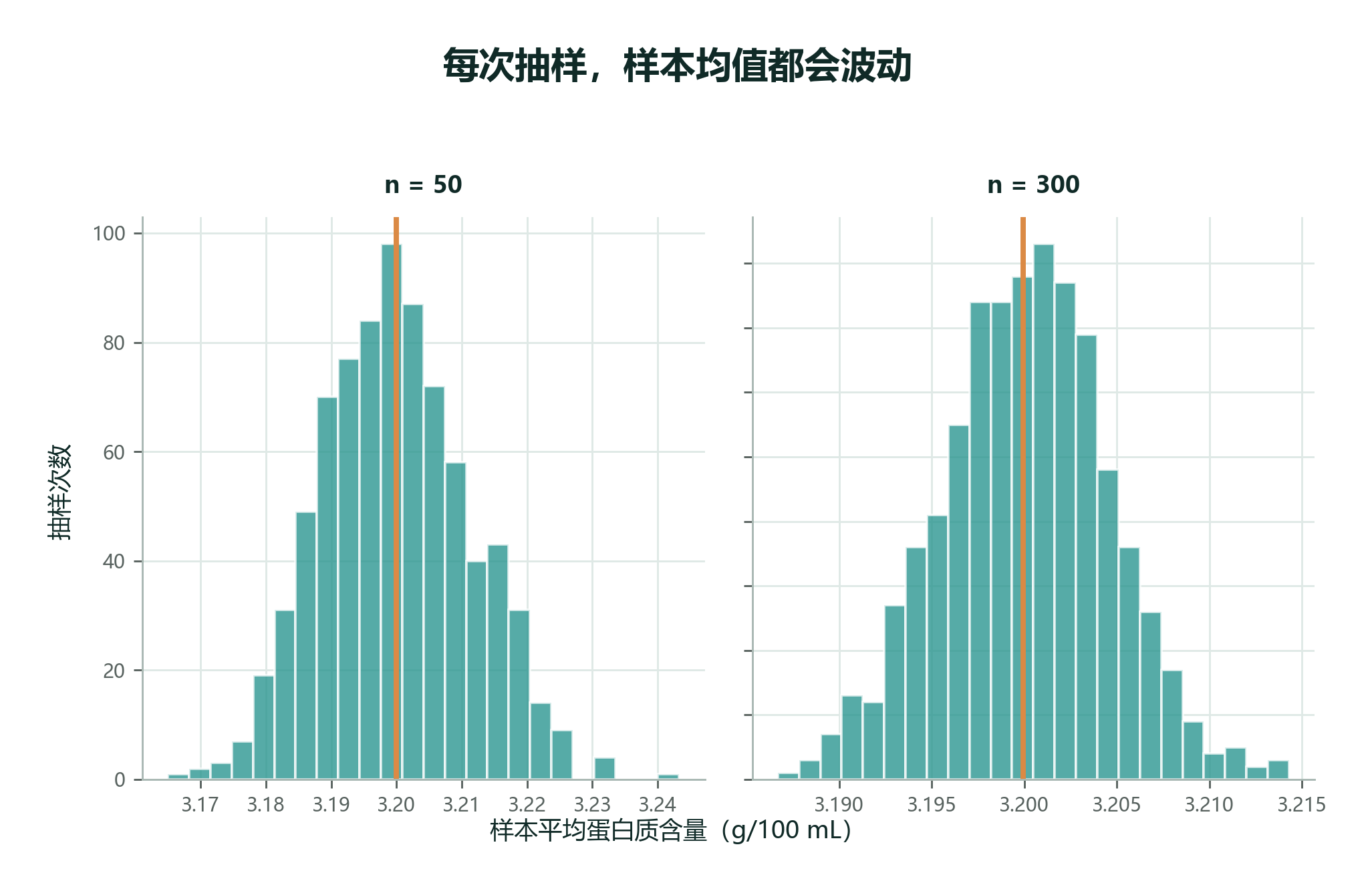
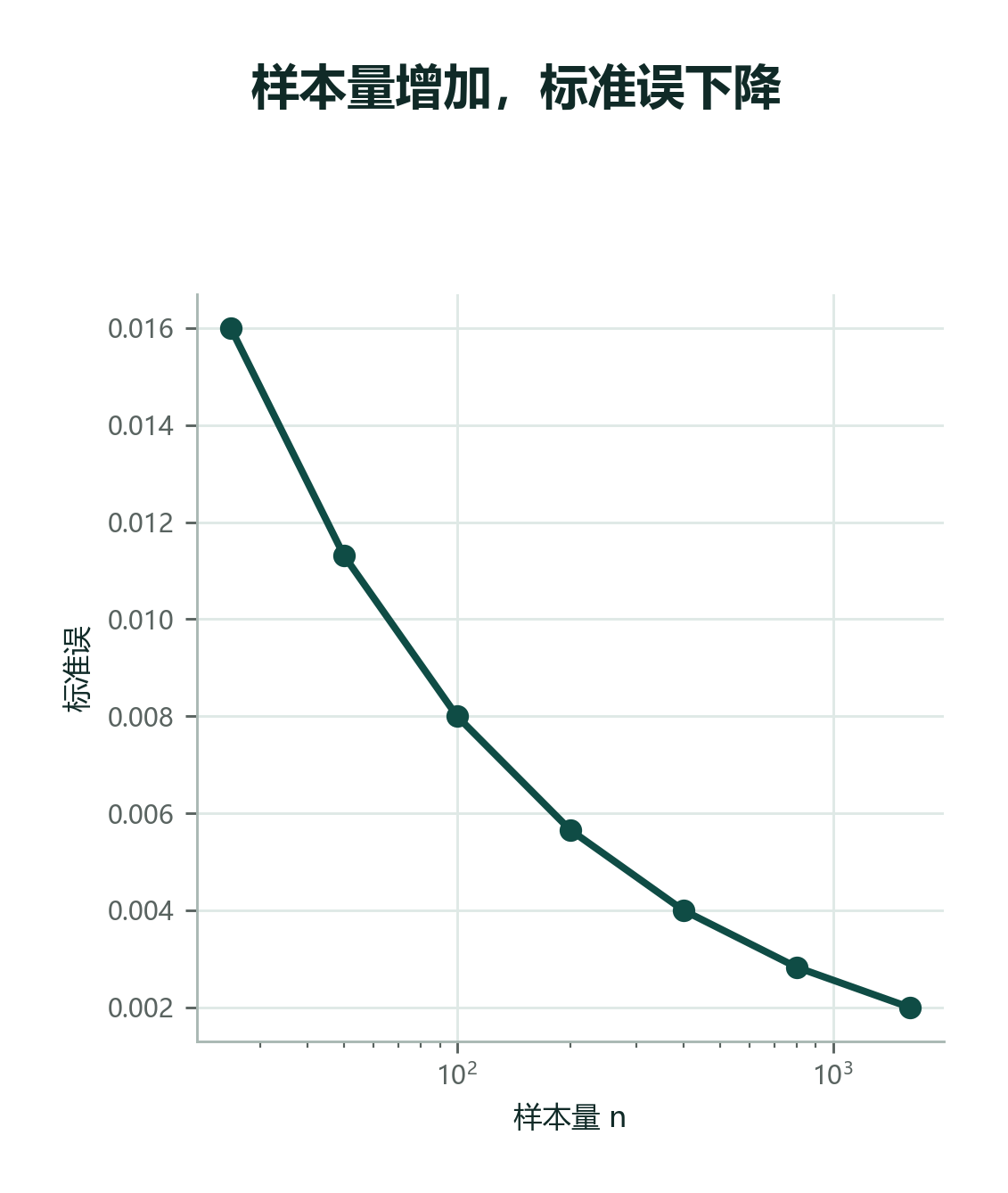
样本量 \(n\) 增大时,样本均值的波动通常会变小。后面我们会把这件事写成 标准误(Standard Error):
这里还要分清两个容易混淆的词:抽样误差**和**抽样偏差。
抽样误差像“正常摇摆”。哪怕抽样方法很公平,每次抽到的 200 盒也不会完全一样,所以样本均值会有一点波动。样本量变大,这种波动通常会变小。
抽样偏差像“方向错了”。如果总是只抽传送带最外侧的盒子,或者总是只抽刚开机时生产的盒子,样本可能长期偏向某一种情况。样本量再大,也只是更精确地错。
| 问题 | 直觉 | 主要解决办法 |
|---|---|---|
| 抽样误差 | 公平抽样下的自然摇摆 | 增加样本量,重复抽样 |
| 抽样偏差 | 抽样方式让某些对象更容易入选 | 改进抽样设计,覆盖总体结构 |
2.1.5 用 Python 模拟抽样误差¶
下面用一个模拟总体来感受抽样误差。假设整批牛奶的蛋白质含量已经存在,只是我们不能把 100 000 盒全部拆开化验。
import numpy as np
rng = np.random.default_rng(21)
population = rng.normal(loc=3.20, scale=0.08, size=100_000)
for n in [20, 100, 500]:
sample_means = []
for _ in range(1000):
sample = rng.choice(population, size=n, replace=False)
sample_means.append(sample.mean())
print(f"n={n:>3},样本均值的标准差约为 {np.std(sample_means, ddof=1):.4f} g/100 mL")
输出会看到:样本量越大,样本均值越稳定。
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/01_population_sample.py,可以复现总体、样本和抽样误差的演示。
你知道吗
统计学通常用样本推断总体,是因为总体太大、太分散,逐一查询成本极高;有些检测还会破坏对象,比如盒装牛奶、灯泡寿命和汽车碰撞测试。但有些问题确实需要尽量接近“查总体”,比如全国人口普查。人口普查会定期收集全国人口数量、年龄结构、地区分布、受教育程度、住房等信息,用来支持教育、医疗、养老、交通和城市规划等政策决策。

这类大规模普查非常重要,但组织成本、时间成本和社会成本都很高,所以不会频繁进行。更多日常研究会使用抽样调查:用设计良好的样本,尽量可靠地估计总体。
小率的笔记本
- 总体是研究问题中所有对象在某个变量上的取值集合,容量记作 \(N\)。
- 样本是从总体中抽出的一部分,样本量记作 \(n\)。
- 参数描述总体,统计量描述样本;我们常用样本统计量估计总体参数。
- 抽样误差不可避免,但合理抽样和更大的样本量能让估计更稳定。
- 抽样偏差比样本小更危险:偏了的样本会把结论带向错误方向。
- 写报告时一定要交代样本从哪里来,否则读者不知道结论能推广到哪里。