14.10 小结¶
这一章里,小率把第 13 章的“训练、验证、泛化”框架,真正落到一组经典模型上。现在他不再问“哪个模型最厉害”,而是会先问:数据有没有标签?边界是不是非线性?簇是不是圆形?样本多不多?特征维度高不高?错误代价是什么?
14.10.1 模型工具箱回顾¶
14.10.2 一页速查图¶
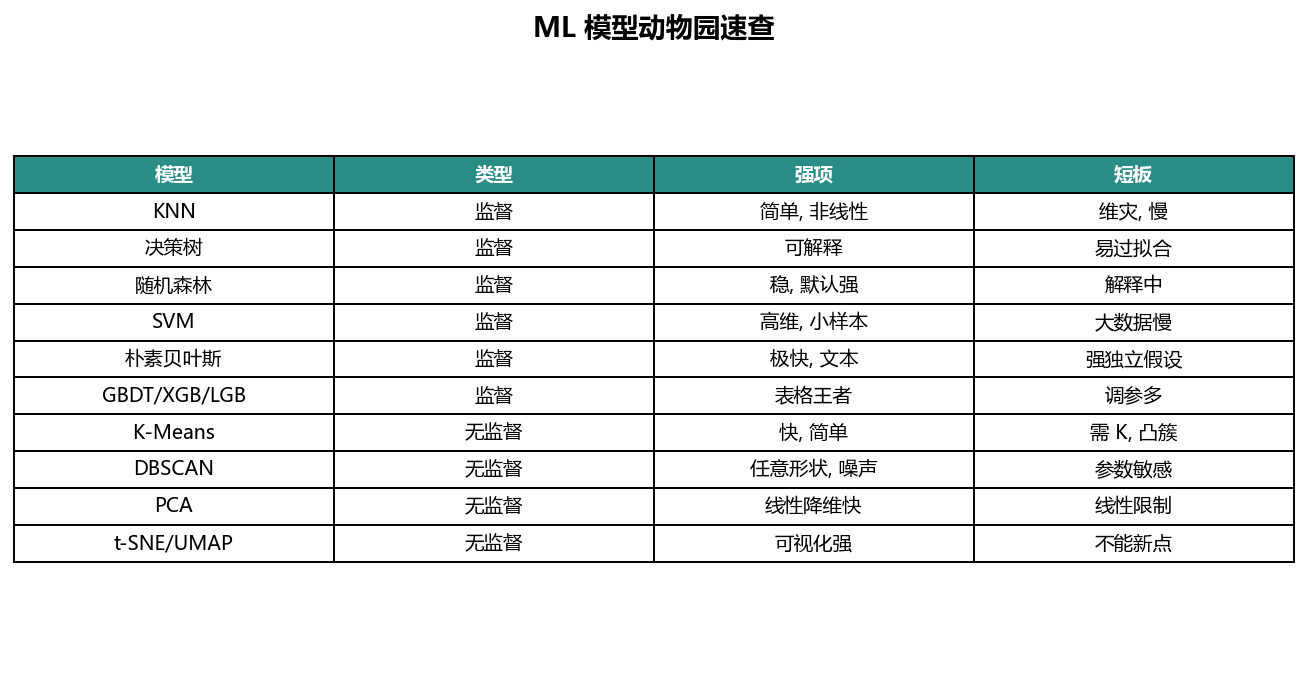
14.10.3 模型选择地图¶
flowchart TD
A["训练时有标签吗"] -->|有| B["预测类别还是数字"]
A -->|没有| C["想分群还是压缩维度"]
B --> D["需要简单基线"]
D --> E["KNN / 决策树 / 朴素贝叶斯"]
B --> F["需要稳健表格模型"]
F --> G["随机森林 / 梯度提升"]
B --> H["中小样本高维边界"]
H --> I["SVM"]
C --> J["簇近似圆形且知道 K"]
J --> K["K-Means"]
C --> L["簇形状不规则或有噪声"]
L --> M["DBSCAN"]
C --> N["高维可视化或压缩"]
N --> O["PCA / t-SNE / UMAP"]14.10.4 模型对比表¶
| 模型 | 核心直觉 | 优点 | 常见风险 |
|---|---|---|---|
| KNN | 找邻居投票 | 简单、边界灵活 | 需标准化、预测慢、怕高维 |
| 决策树 | 一连串问题切分 | 可解释、不怕尺度 | 容易过拟合 |
| 随机森林 | 多树投票 | 稳定强基线 | 模型大、解释弱 |
| SVM | 最大间隔 | 中小高维数据强 | 参数敏感、大样本慢 |
| 朴素贝叶斯 | 贝叶斯合并证据 | 文本小数据快 | 独立假设强、概率不稳 |
| 梯度提升 | 逐步修正错误 | 表格任务强 | 易过拟合、需早停 |
| K-Means | 找 K 个中心 | 快、直观 | 偏爱圆形簇、需指定 K |
| DBSCAN | 找密集区域 | 任意形状、识别噪声 | 参数敏感、多密度困难 |
| 降维 | 压缩保结构 | 可视化、去噪、加速 | 信息损失、图需谨慎解释 |
14.10.5 十个容易翻车的地方¶
常见误区
- KNN 和 SVM 忘记标准化。
- 决策树不限制深度,训练集满分后误以为模型很好。
- 把随机森林特征重要性当成因果解释。
- 梯度提升不做早停,只堆更多树。
- 朴素贝叶斯输出概率未经校准就拿去做高风险决策。
- K-Means 用在月牙形簇上。
- 只用 inertia 选择 K,忘记它会随 K 增大单调下降。
- DBSCAN 在高维空间直接跑。
- 过度解读 t-SNE 图上簇间距离。
- 在全量数据上标准化、降维或编码后再交叉验证。
14.10.6 一条实战流程¶
- 先做一个简单基线:分类可从 LogisticRegression、KNN、树开始;文本可试朴素贝叶斯。
- 用交叉验证估计泛化,指标要匹配任务代价。
- 检查泄漏:标准化、编码、降维、特征选择都放进 Pipeline。
- 看误差样本:模型错在哪里,比平均分更有用。
- 根据问题换模型:非线性表格可试随机森林或梯度提升;不规则聚类可试 DBSCAN;高维可先降维。
- 最后再调参,不要一上来就追复杂模型。
14.10.7 术语对照表 (Glossary)¶
| 中文 | English | 本章含义 |
|---|---|---|
| K 近邻 | K-Nearest Neighbors | 用最近邻居投票或平均 |
| 决策树 | Decision Tree | 用递归切分形成规则树 |
| 随机森林 | Random Forest | 多棵随机树投票或平均 |
| 支持向量机 | Support Vector Machine | 寻找最大间隔分类边界 |
| 朴素贝叶斯 | Naive Bayes | 条件独立假设下的贝叶斯分类器 |
| 梯度提升 | Gradient Boosting | 逐步加模型修正损失 |
| K-Means | K-Means | 用 K 个中心划分簇 |
| DBSCAN | DBSCAN | 基于密度发现簇和噪声 |
| 降维 | Dimensionality Reduction | 把高维数据压到低维 |
小率的笔记本
经典模型没有绝对排名。KNN 看邻居,树模型切规则,森林和提升做集成,SVM 找间隔,朴素贝叶斯合并证据,K-Means 和 DBSCAN 找结构,降维帮助看见高维数据。真正重要的是让模型匹配数据形状和任务代价。
14.10.9 练一练¶
本章核心练习题汇总。建议先动笔再看参考答案。
练习 14.1.1
KNN 中 \(K=1\) 和 \(K=N\) 分别有什么风险?
参考答案
\(K=1\) 极易过拟合,边界跟着噪声乱跳;\(K=N\) 几乎只预测多数类或全局均值,容易欠拟合。
练习 14.2.1
决策树需要标准化吗?为什么?
参考答案
通常不需要。决策树按阈值切分,特征单调缩放不会改变样本排序,因此不像 KNN/SVM 那样依赖尺度。
练习 14.3.1
随机森林为什么比单棵树更稳定?
参考答案
它通过 Bootstrap 样本随机和特征随机训练多棵差异化树,再投票或平均,降低单棵树的方差。
练习 14.4.1
RBF SVM 中 \(\gamma\) 太大可能发生什么?
参考答案
每个样本影响范围过小,边界会变得很局部、很弯,容易过拟合。
练习 14.5.1
为什么朴素贝叶斯适合做文本分类基线?
参考答案
文本特征通常高维稀疏,朴素贝叶斯参数少、训练快,小数据也能稳定工作。
练习 14.6.1
梯度提升和随机森林的合作方式有什么不同?
参考答案
随机森林多棵树并行训练后投票,主要降方差;梯度提升按顺序训练,每棵树修正前面模型的错误,主要降偏差。
练习 14.7.1
K-Means 为什么不适合月牙形簇?
参考答案
K-Means 用中心和平方距离定义簇,偏爱近似圆形、大小相近的结构,月牙形会被中心距离错误切开。
练习 14.8.1
DBSCAN 输出标签 -1 表示什么?
参考答案
表示噪声点,也就是不属于任何密集簇的样本。
练习 14.9.1
t-SNE 图上两个簇离得很远,能说明原空间里两类一定很远吗?
参考答案
不能。t-SNE 主要保留局部邻域结构,全局距离和簇间距离不能直接当作原空间距离解释。