6.5 均值的置信区间¶
小率把 8 盒牛奶摆在桌上,每盒标称 250 mL。他用量杯测了一遍,得到 8 个数:249、252、248、253、251、247、250、252。
他想估计这批牛奶的平均容量。但问题来了:上一节的公式要求总体标准差 \(\sigma\) 已知,现实里我们通常不知道 \(\sigma\)。

σ 不知道,还能做均值区间吗
可以。用样本标准差 \(s\) 代替总体标准差 \(\sigma\),但必须承认 \(s\) 也是估出来的。这个额外不确定性会把标准正态 \(z\) 换成 t 分布(Student's t Distribution)。
6.5.1 t 分布是在给小样本补保险¶
若 \(\sigma\) 已知:
但 \(\sigma\) 通常未知,只能用 \(s\) 代替:
这时:
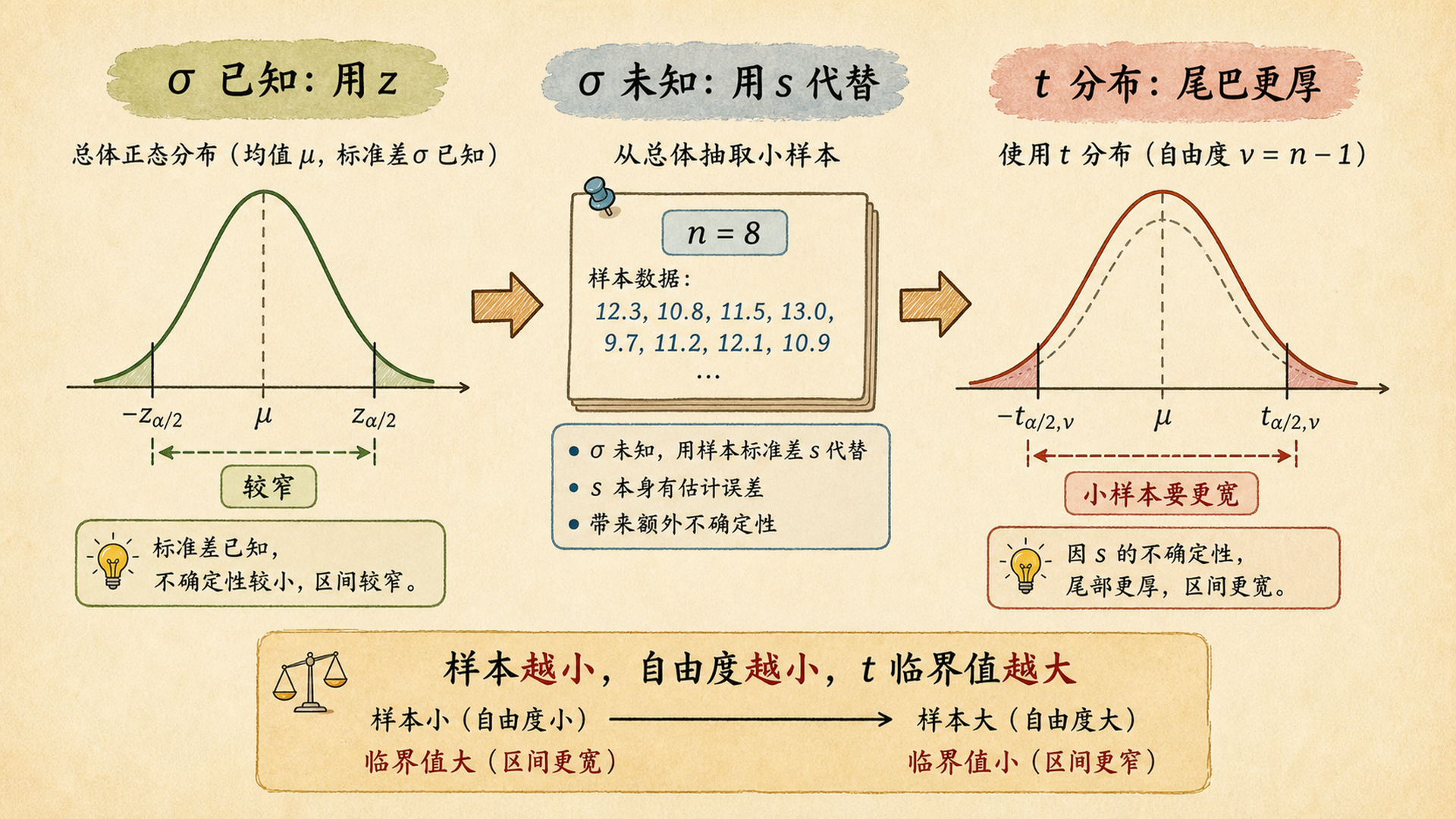
t 分布比标准正态尾巴更厚,尤其在样本量小时更明显。尾巴更厚意味着同样 95% 置信水平下,临界值更大,区间更宽。
Student 是谁
t 分布由 William Sealy Gosset 在啤酒厂小样本质量控制问题中推导出来。由于公司不允许公开发表,他用笔名 “Student” 发表,所以今天仍叫 Student's t 分布。
6.5.2 单样本均值 t 区间¶
当总体近似正态,或样本量足够大时,均值的 t 置信区间是:
其中自由度是 \(n-1\)。
用牛奶例子手算:
| 盒号 | 容量(mL) |
|---|---|
| 1 | 249 |
| 2 | 252 |
| 3 | 248 |
| 4 | 253 |
| 5 | 251 |
| 6 | 247 |
| 7 | 250 |
| 8 | 252 |
样本均值:
样本标准差:
自由度 \(df=7\),95% 临界值 \(t_{0.025,7}\approx 2.365\),所以:
即:
6.5.3 什么时候可以放心用 t 区间¶
t 区间的常用条件:
- 数据来自近似正态总体,小样本也可用。
- 总体不太正态,但样本量较大时,中心极限定理会帮忙。
- 小样本且明显偏态、有极端值时,谨慎使用,优先考虑 Bootstrap。
小样本最怕离群值
当 \(n=8\) 时,一个异常值就能明显改变 \(\bar x\) 和 \(s\)。这时不要只套公式,也要画图、查原始记录,必要时用 Bootstrap 做稳健性检查。
6.5.4 Python 计算 t 区间¶
import numpy as np
from scipy import stats
milk = np.array([249, 252, 248, 253, 251, 247, 250, 252])
n = len(milk)
xbar = milk.mean()
s = milk.std(ddof=1)
tcrit = stats.t.ppf(0.975, df=n - 1)
margin = tcrit * s / np.sqrt(n)
print(f"样本均值 = {xbar:.2f} mL")
print(f"样本标准差 = {s:.2f} mL")
print(f"95% t-CI = [{xbar - margin:.2f}, {xbar + margin:.2f}]")
完整脚本见:
小率的笔记本
\(\sigma\) 已知用 \(z\),\(\sigma\) 未知用 \(t\)。t 区间把“用 \(s\) 估 \(\sigma\)”带来的额外不确定性补进去。样本越小,自由度越小,t 临界值越大,区间越宽。