14.2 决策树¶
小率发现,社团老师最喜欢问“为什么推荐这个活动”。KNN 能说“因为邻居都选了它”,但很难给出一条清楚规则。于是均哥换了一种模型:像做问卷一样,一步步提问。
“艺术兴趣高吗?”“周五晚上有空吗?”“过去是否参加过展览?”每个问题把同学分成两边,最后落到一个推荐结果。这样的模型叫 决策树(Decision Tree)。

决策树是不是最像人写规则的模型?
很像,但规则不是人手写的,是算法从数据里挑出来的。
14.2.1 每次切分都想让组内更纯¶
决策树从根节点开始,每次选择一个特征和一个阈值,把样本分成左右两组。好的切分应该让每组内部尽量“纯”:同一组里大多属于同一类别。
分类树常用 基尼不纯度(Gini Impurity):
\[
Gini=1-\sum_{c=1}^{C}p_c^2
\]
\(p_c\) 是当前节点里类别 \(c\) 的比例。如果一个节点全是同一类,\(Gini=0\);类别越混杂,Gini 越大。
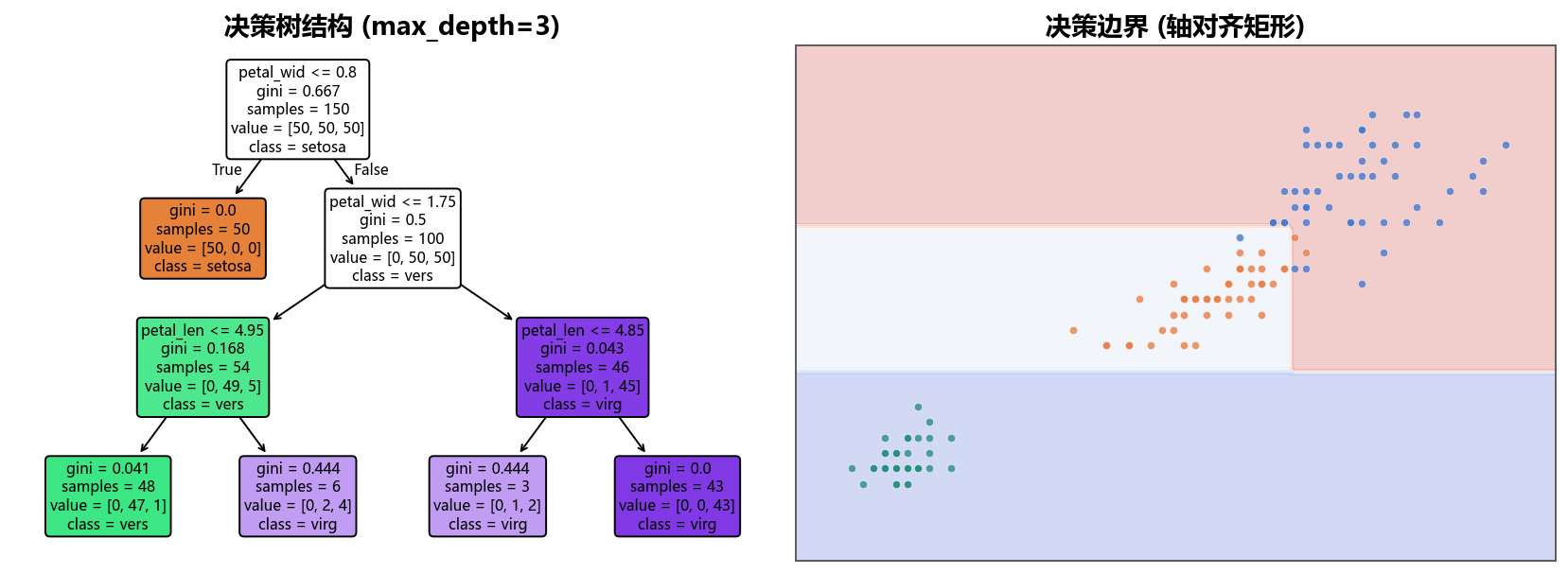
树在做什么
决策树不断寻找“让子节点更纯”的问题。每个内部节点是一次判断,每个叶子节点给出预测。
14.2.2 树太深会背旧题¶
如果不限制深度,决策树可以一路切到每个叶子几乎只剩一个样本。训练集会很好看,但新样本往往不稳。
常见约束包括:
| 参数 | 含义 | 作用 |
|---|---|---|
max_depth |
最大深度 | 防止规则过细 |
min_samples_leaf |
叶子最少样本数 | 防止孤立样本成规则 |
min_samples_split |
分裂所需最少样本数 | 防止末端继续切 |
ccp_alpha |
剪枝强度 | 删掉收益小的分支 |
树越深,看起来越聪明,其实可能越会背题。
对。树模型的解释性很强,但也很容易过拟合。
14.2.3 回归树看方差下降¶
回归树预测连续数值,比如活动报名人数。它每次切分时,不再看类别纯度,而是看左右节点的平方误差能否下降。
叶子节点的预测通常是该叶子里训练样本的平均值:
\[
\hat y_{\text{leaf}}=\frac{1}{m}\sum_{i=1}^{m}y_i
\]
所以回归树像把输入空间切成许多小房间,每个房间给一个局部平均预测。
14.2.4 用 Python 训练一棵浅树¶
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
X, y = make_classification(
n_samples=400,
n_features=6,
n_informative=4,
random_state=2026,
)
tree = DecisionTreeClassifier(
max_depth=4,
min_samples_leaf=10,
random_state=2026,
)
scores = cross_val_score(tree, X, y, cv=5, scoring="f1")
print(f"5 折 F1 = {scores.mean():.3f} ± {scores.std(ddof=1):.3f}")
特征重要性不是因果重要性
决策树的特征重要性表示“这个特征帮助预测多少”,不表示“这个特征导致结果变化”。因果问题要用因果推断方法单独处理。
小率的笔记本
决策树用一连串问题把样本切开,优点是解释直观、不需要标准化;缺点是容易过拟合。控制深度、叶子样本数和剪枝,是树模型的基本功。