4.7 协方差与相关系数¶
小率把书包往均哥桌边一放,先掏出来的不是冰汽水,而是一张生物老师布置的作业纸。
作业里出现了两个词:基因(Gene) 和 基因表达(Gene Expression)。基因是 DNA 上具有特定功能的片段,常与蛋白质合成、细胞功能调节有关;基因表达值则表示某个基因在某个细胞中的活跃程度。表达值越高,通常表示这个基因相关的转录信号越强。
如果两个基因总是一起高、一起低,它们可能在同一条生物通路里工作,可能被同一个调控开关控制,也可能共同参与某种疾病状态。比如肿瘤细胞里,一组基因如果总是同步活跃,研究者就会追问:它们是不是和细胞异常增殖有关?

4.7.1 生物老师的作业¶
作业:
作业纸上给了一个很小的数据表。行是基因,列是细胞;每一列里的两个数,来自同一个细胞。
| 基因 细胞 | 细胞 1 | 细胞 2 | 细胞 3 | 细胞 4 | ... |
|---|---|---|---|---|---|
| X 基因 | 3 | 13 | 18 | 22 | ... |
| Y 基因 | 12 | 20 | 25 | 28 | ... |
已知两个基因分别在同一批细胞中的表达值,判断 X 基因 和 Y 基因 有没有关系。
小率盯着两列数字,越看越头大。
也就是说,第 \(i\) 个细胞不是只给我们一个 X,也不是只给我们一个 Y,而是给我们一对数:
一对数可以变成坐标系里的一个点。于是,“两个基因有没有关系”就先变成了一个更容易看见的问题:这些点有没有方向?
4.7.2 先看点云的方向¶
把每个细胞的 X 基因表达值放在横轴,把同一个细胞的 Y 基因表达值放在纵轴,就得到一张散点图。
如果 X 低的细胞,Y 也低;X 高的细胞,Y 也高,点云会沿着右上方向排列。这叫 正趋势:两个变量倾向于同高同低。
如果 X 高的时候 Y 低,X 低的时候 Y 高,点云会沿着右下方向排列。这叫 负趋势:两个变量倾向于此高彼低。
如果点云散成一团,看不出稳定方向,就说明二者至少没有明显的线性趋势。
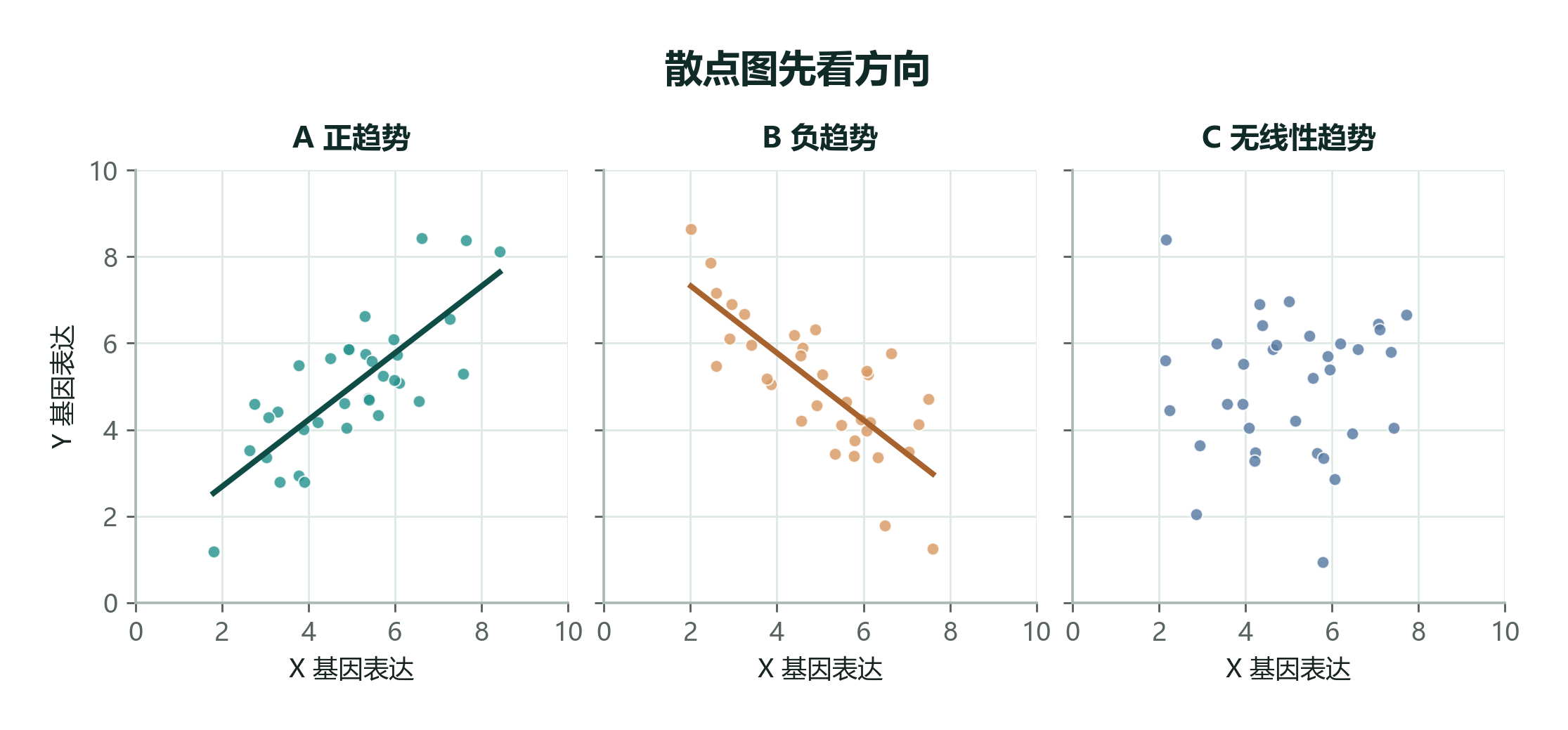
小率拿笔在三张图上画了三条想象中的线。
这一步先不要急着问“相关系数是多少”。先问更朴素的问题:
- 点云有没有方向?
- 如果有方向,是向右上还是向右下?
- 点离一条线近不近?
4.7.3 协方差:把“同高同低”算出来¶
现在我们只做一件很朴素的事:看每个点相对平均值是偏高还是偏低。
先计算两个基因的平均表达值:
拿一个细胞试试。它的表达值是:
它的 X 低于平均值,Y 也低于平均值:
两个偏差都是负数,相乘得到正数。这不是巧合,而是在说:这个细胞支持“X 和 Y 同低”。
均值线把平面分成四块:
- 右上:X 高于均值,Y 也高于均值,偏差乘积为正。
- 左下:X 低于均值,Y 也低于均值,偏差乘积为正。
- 左上:X 低于均值,Y 高于均值,偏差乘积为负。
- 右下:X 高于均值,Y 低于均值,偏差乘积为负。
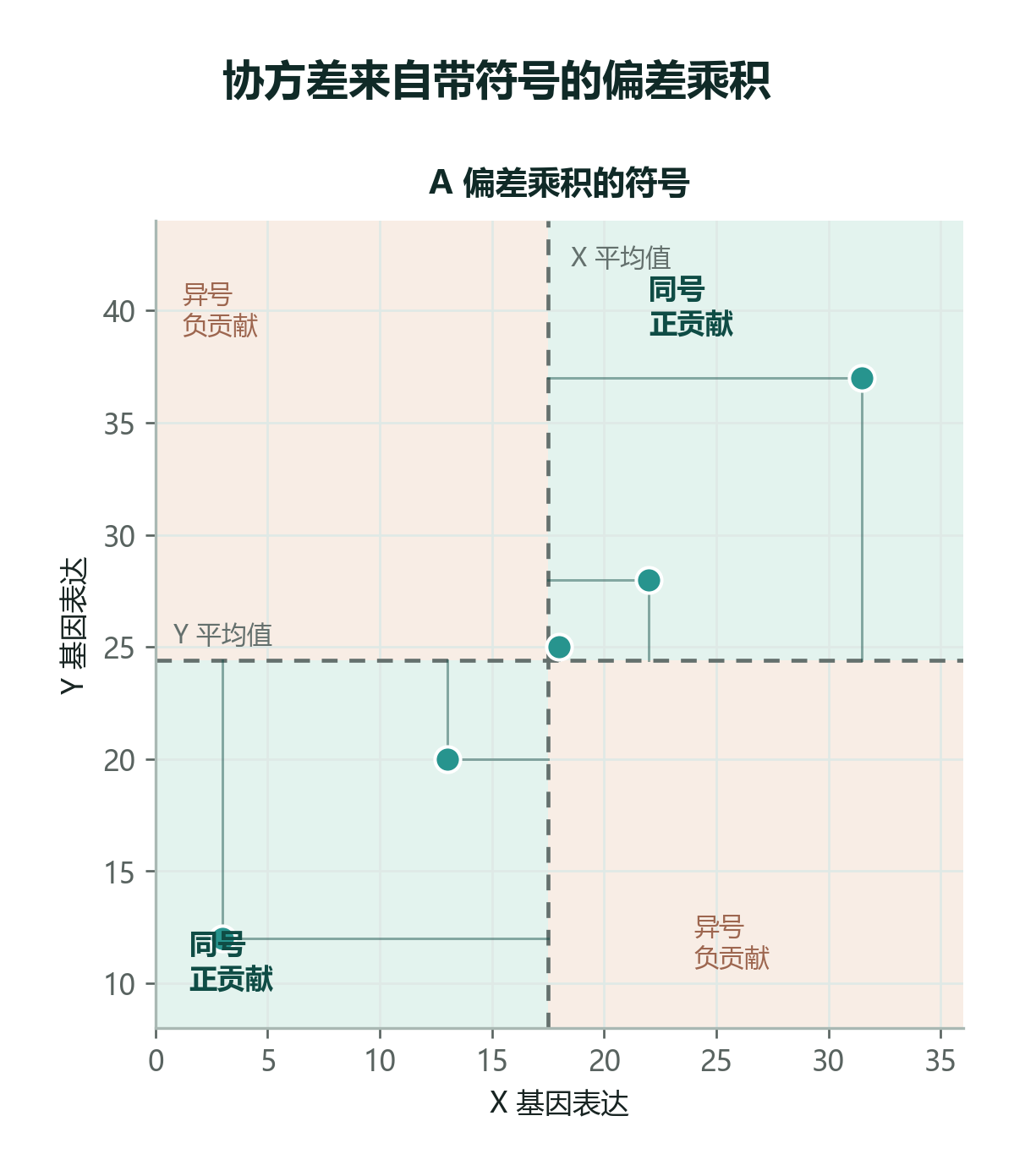
把所有细胞的偏差乘积加起来,再除以自由度,就得到样本协方差:
协方差的符号非常有用:
- \(\operatorname{cov}(X,Y)>0\):点更多落在同高同低区域,趋势为正。
- \(\operatorname{cov}(X,Y)<0\):点更多落在此高彼低区域,趋势为负。
- \(\operatorname{cov}(X,Y)\approx 0\):正负贡献互相抵消,线性趋势不明显。
4.7.4 协方差的问题:单位会放大它¶
小率刚想把协方差当成“关系强度分数”,均哥把图往旁边一推。
协方差带着原始变量的单位。如果 X 和 Y 的表达值都放大 2 倍,点云形状没有变,直线方向没有变,两个基因的关系也没有变。
但是每个偏差都会放大 2 倍,两个偏差相乘就会放大 4 倍,所以协方差也会放大 4 倍。
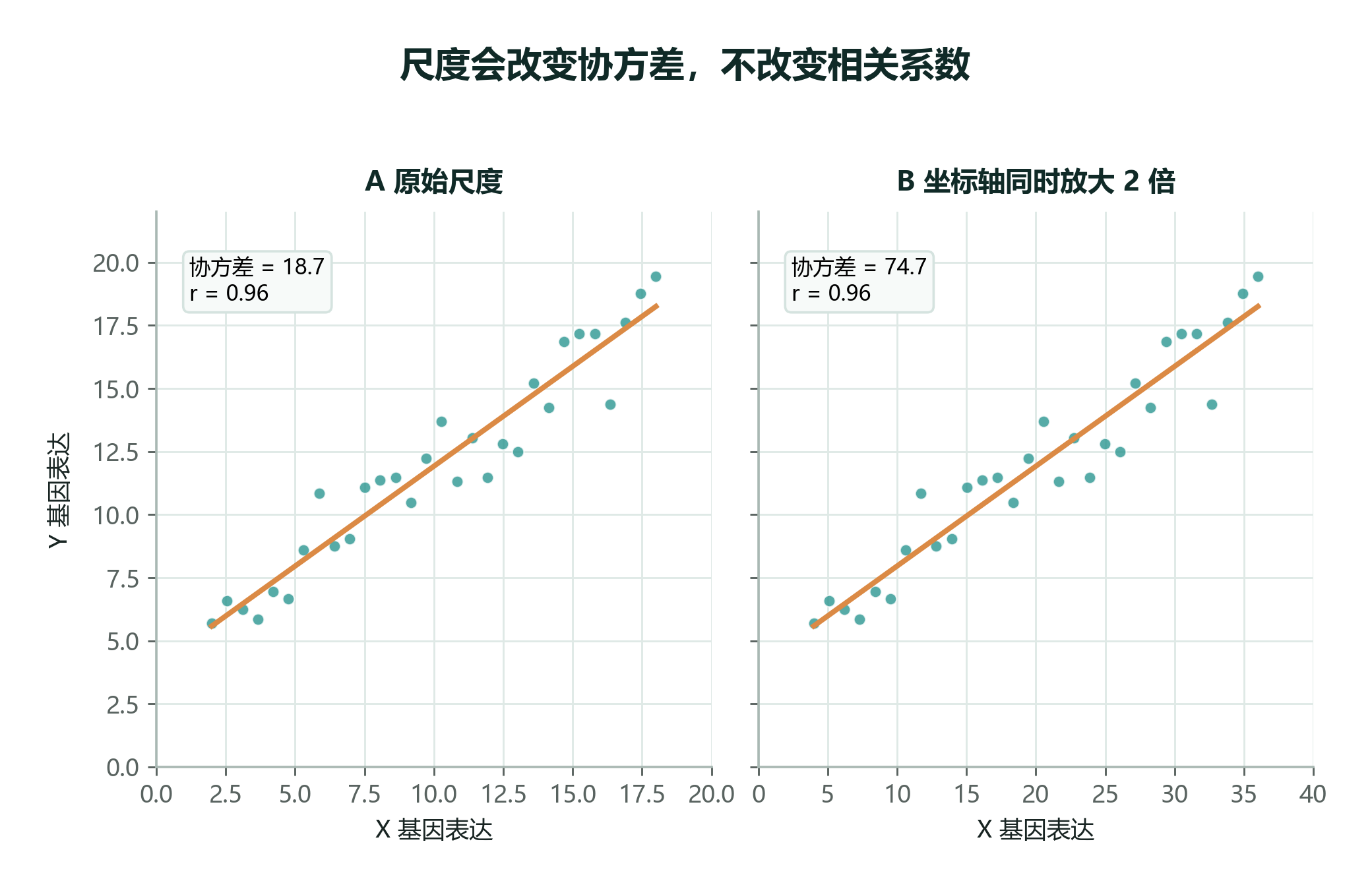
这意味着协方差不适合直接比较“谁的关系更强”。例如:
- 基因表达量用 TPM、FPKM 或原始计数表示,协方差数值可能完全不同。
- 两个变量的单位不同,协方差的大小没有统一参照。
- 坐标轴范围一变,协方差就会变大或变小,但点云关系未必变了。
4.7.5 相关系数:标准化后的协方差¶
既然协方差会被单位放大,我们就把单位影响除掉。
做法很直接:把协方差除以 X 和 Y 各自的标准差,得到 皮尔逊相关系数(Pearson Correlation Coefficient):
分子仍然是协方差,所以它保留方向;分母是两个标准差,所以它把尺度影响标准化掉。这样一来,相关系数的取值被限制在:
可以这样理解:
- \(r=1\):所有点完美落在一条正斜率直线上。
- \(r=-1\):所有点完美落在一条负斜率直线上。
- \(r\approx 0\):没有明显线性关系。
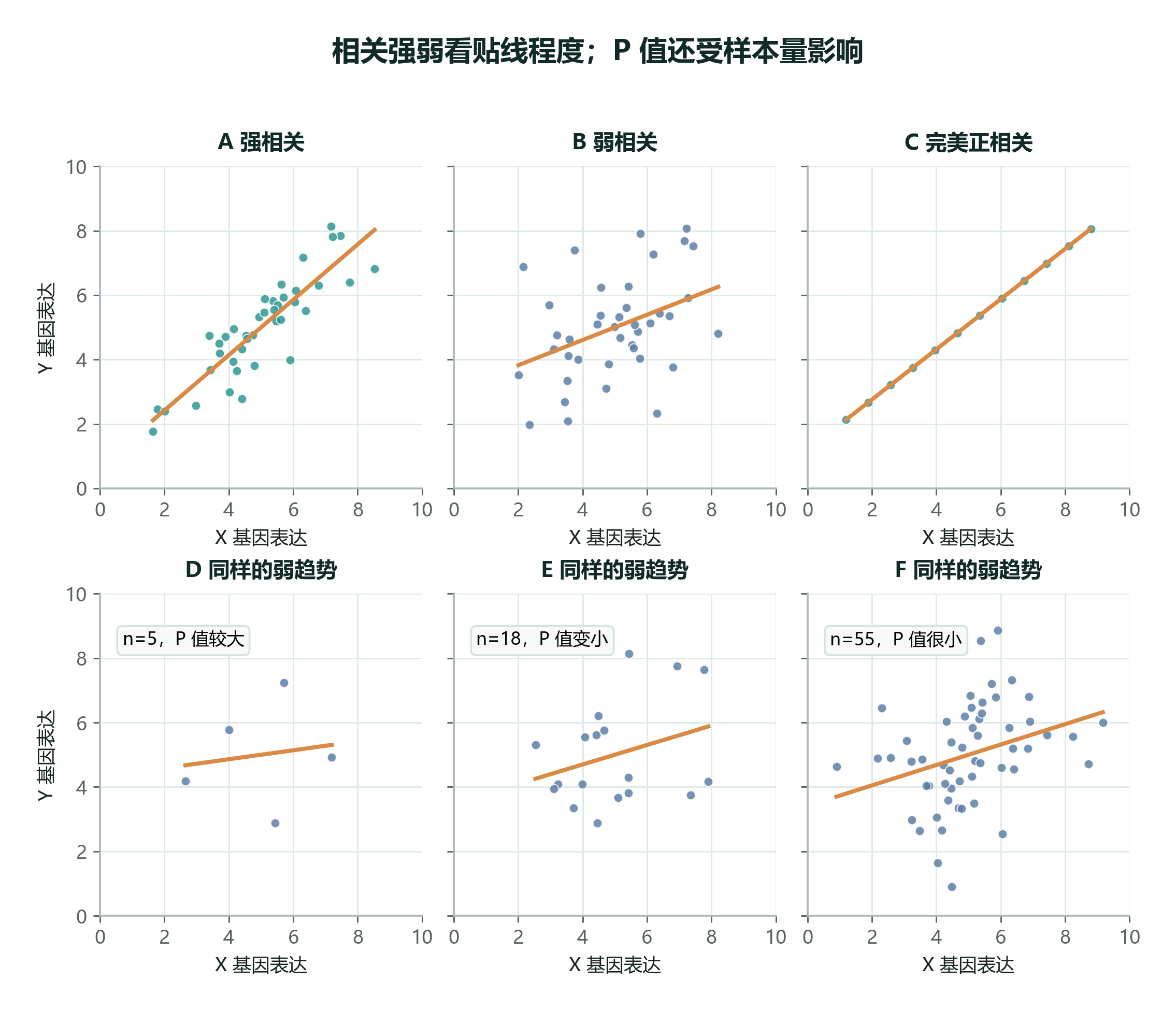
- \(|r|\) 越大,点越贴近一条直线,线性关系越强。
相关强弱还可以从预测角度理解。点越贴近趋势线,知道 X 之后,预测 Y 的不确定范围越小;点越分散,知道 X 也只能给出很宽的猜测范围。
需要注意
我们说“用 X 预测 Y”,并不等于“X 导致 Y”。相关关系描述的是共同变化模式,因果关系还需要实验设计、干预、混杂控制等额外证据。
4.7.6 P 值:这条趋势线有多站得住¶
相关系数回答的是“关系强不强”。但还有另一个问题:这个相关系数是不是可能只是抽样运气造成的?
这就要看 P 值(P-value)。在相关分析中,常见的原假设是:
也就是总体里 X 和 Y 没有线性相关。P 值越小,表示在“总体其实没有相关”的前提下,抽到当前这种相关结果的概率越小。
样本量会强烈影响 P 值。随着细胞数量增加,同样方向的趋势如果还能保持,趋势线就更可信,P 值也更容易变小。
所以报告相关分析时,最好同时说明:
- 相关系数 \(r\):方向和强弱。
- 样本量 \(n\):证据来自多少对观测。
- P 值:当前样本对“无相关”假设的反驳程度。
- 图形:是否有离群点、非线性关系或分组结构。
4.7.7 R²:这条线解释了多少变化¶
相关系数 \(r\) 有方向,但有时我们还想用更直观的百分比来表达关系强度。这时可以看 决定系数(Coefficient of Determination),也就是 \(R^2\)。
先想一个最偷懒的预测方法:不看 X,只用 Y 的平均值去猜每个细胞或每只小鼠的 Y 值。这个方法会产生一堆误差:
再想一个更聪明的方法:根据 X 拟合一条直线,用直线上的预测值 \(\hat{y}_i\) 去猜 Y。它的误差是:
\(R^2\) 比较的就是:拟合线比“只猜平均值”好多少。
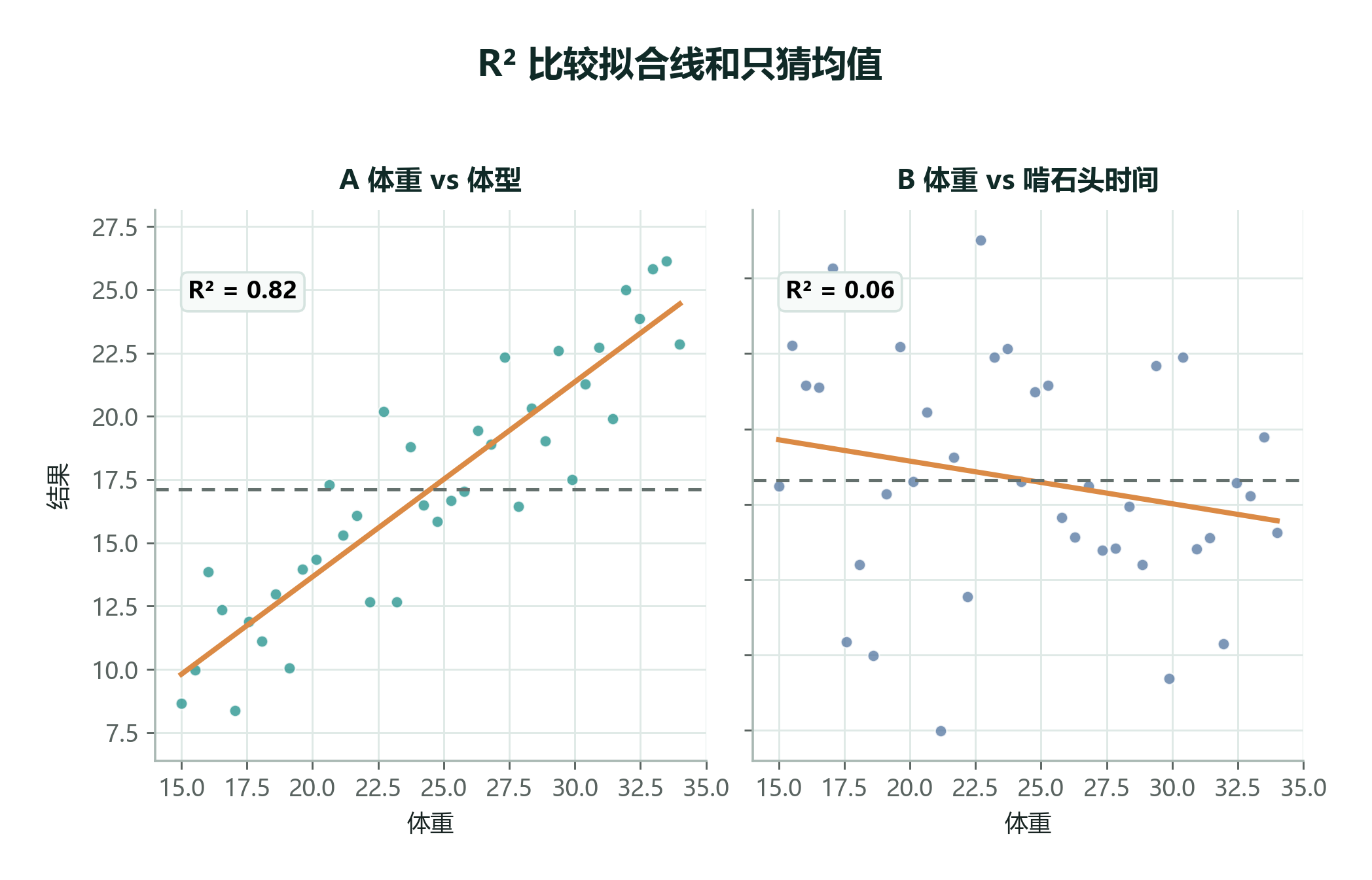
如果 \(R^2=0.81\),可以说这条线解释了 81% 的 Y 方向变化;如果 \(R^2=0.06\),说明这条线只比均值预测多解释了 6% 的变化。
在只有一个自变量的简单线性回归里,\(R^2\) 等于相关系数的平方:
例如:
- \(r=0.7\),则 \(R^2=0.49\),约 49% 的变化可由这条线解释。
- \(r=0.5\),则 \(R^2=0.25\),约 25% 的变化可由这条线解释。
但 \(R^2\) 没有方向。\(r=0.7\) 和 \(r=-0.7\) 的 \(R^2\) 都是 0.49,所以解释结果时要把 \(r\) 的符号一起报告。
4.7.8 用 Python 把这件事算一遍¶
小率把作业纸翻到背面,写下 5 个细胞的表达值。前面的图和公式都已经讲过,现在轮到 Python 来做同一件事:算均值、协方差、相关系数和 P 值。
import numpy as np
from scipy.stats import pearsonr
# 5 个细胞中的两个基因表达值
x_gene = np.array([3, 13, 18, 22, 32], dtype=float)
y_gene = np.array([12, 20, 25, 28, 37], dtype=float)
x_mean = x_gene.mean()
y_mean = y_gene.mean()
# ddof=1 表示样本协方差,分母是 n-1
cov_xy = np.cov(x_gene, y_gene, ddof=1)[0, 1]
r_xy, p_value = pearsonr(x_gene, y_gene)
print(f"X 基因平均表达 = {x_mean:.1f}")
print(f"Y 基因平均表达 = {y_mean:.1f}")
print(f"样本协方差 cov(X, Y) = {cov_xy:.2f}")
print(f"Pearson 相关系数 r = {r_xy:.3f}")
print(f"P 值 = {p_value:.2e}")
输出大致是:
这组小数据的点几乎贴在一条上升直线上,所以 \(r\) 非常接近 1。这里的 P 值也很小,但要记住:只有 5 个细胞时,任何统计结论都应该谨慎,真实研究还要看样本来源、批次效应、细胞类型和实验设计。
再看“尺度会改变协方差,但不改变相关系数”:
x2 = 2 * x_gene
y2 = 2 * y_gene
cov_scaled = np.cov(x2, y2, ddof=1)[0, 1]
r_scaled = np.corrcoef(x2, y2)[0, 1]
print(f"放大 2 倍后的样本协方差 = {cov_scaled:.2f}")
print(f"放大 2 倍后的相关系数 r = {r_scaled:.3f}")
输出是:
协方差从 99.70 变成 398.80,正好放大 4 倍;相关系数仍然是 0.999。这就是为什么协方差适合看方向,而相关系数更适合比较线性关系强弱。
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch04_random_variables/07_covariance_correlation/main.py,可以复现上面的计算结果。
4.7.9 相关分析的几个坑¶
误解 1:相关等于因果。
不等于。两个基因一起升高,可能是一个调控另一个,也可能是同一个上游信号同时调控了它们,还可能是批次效应、细胞类型混杂或测量偏差造成的。
误解 2:相关系数接近 0 就表示没有任何关系。
不一定。相关系数主要捕捉线性关系。如果两个变量呈 U 形、周期形或分段关系,Pearson 相关系数可能接近 0,但图上仍然有结构。
误解 3:P 值小就代表关系很强。
不一定。样本量很大时,非常弱的相关也可能得到很小的 P 值。所以要同时看 \(r\)、\(n\)、P 值和散点图。
误解 4:R² 越高模型越好。
也不总是。R² 高可能来自真实关系,也可能来自过拟合、离群点或数据泄漏。它说明“解释了多少变化”,但不自动保证因果解释或泛化能力。
小率的笔记本
- 先画散点图:正趋势、负趋势、无线性趋势都能从点云方向看出来。
- 协方差来自两个偏差的乘积:同高同低为正贡献,此高彼低为负贡献。
- 协方差能判断方向,但会被单位和尺度放大,不适合直接比较强弱。
- 相关系数是标准化后的协方差,取值范围是 -1 到 1,可以同时表达方向和线性强弱。
- P 值描述证据是否足以反驳“总体无相关”,它会受到样本量影响。
- R² 表示拟合线比均值线多解释了多少变化;简单线性关系中 \(R^2=r^2\),但 R² 本身没有方向。
- 下一节 §4.8 会继续看联合分布与边际分布,把两个随机变量放在同一张概率地图里。