7.5 显著性水平¶
科学社团准备测试一套新的训练方法是否能提高投篮命中率。小率想等数据收完再决定“多小的 p 值算显著”。均哥摇摇头,把三张卡片放在桌上:
- \(\alpha=0.10\):探索,门槛宽松。
- \(\alpha=0.05\):常用,平衡选择。
- \(\alpha=0.01\):严格,需要更强证据。
显著性水平不是数据算出来的,而是在实验前定下的错误容忍度。

7.5.1 alpha 是误报容忍度¶
显著性水平 \(\alpha\) 的定义是:
也就是:如果其实没有效果,我们愿意承受多大概率误判为“有效”。
它也叫:
- 第一类错误率(Type I error rate)。
- 假阳性率(false positive rate)。
- 显著性水平(significance level)。
一句话
\(\alpha\) 是研究者在看数据前设定的“误报上限”,不是 p 值,也不是效果大小。
7.5.2 alpha 越小,拒绝域越窄¶
在双侧检验里,\(\alpha\) 会被分到两端尾部。\(\alpha\) 越小,尾部拒绝域越窄,临界值越远,越难拒绝 \(H_0\)。
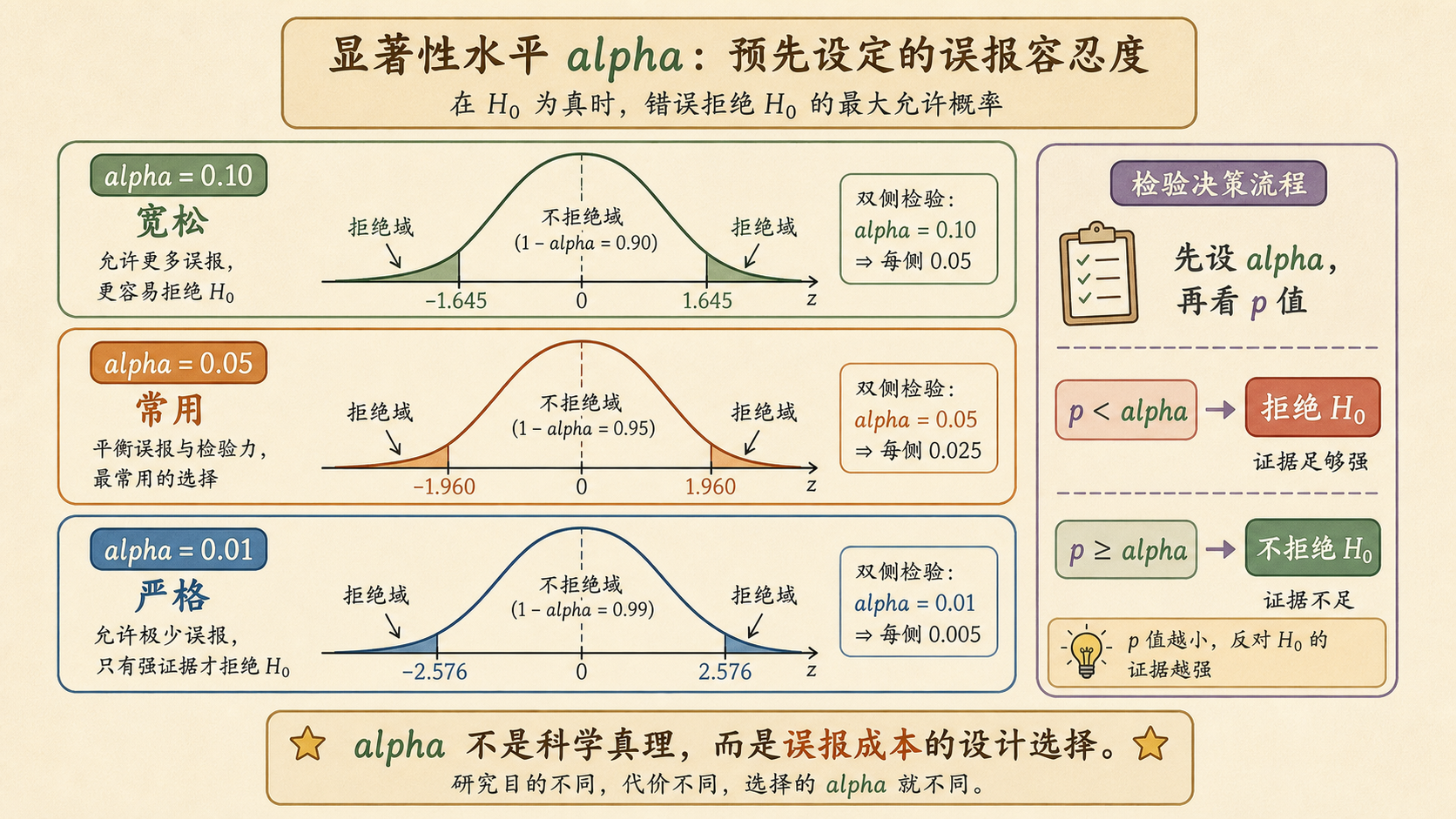
常用临界值:
| \(\alpha\) | 双侧 z 临界值 |
|---|---|
| 0.10 | \(\pm1.645\) |
| 0.05 | \(\pm1.960\) |
| 0.01 | \(\pm2.576\) |
| 0.001 | \(\pm3.291\) |
7.5.3 alpha 要按代价选择¶
不同场景对误报的容忍度不同。
| 场景 | 误报后果 | alpha 倾向 |
|---|---|---|
| 探索性问卷 | 多发现一些线索,后续再验证 | 可稍宽松 |
| 课堂小实验 | 后果可控,重在学习 | 0.05 常用 |
| 药物审批 | 批准无效或有害药物 | 应更严格 |
| 重大科学发现 | 全球资源跟进、结论影响大 | 极严格 |
你知道吗
物理学里宣布新粒子发现常用 5σ 标准,对应的误报概率远小于 0.05。它不是因为统计学公式不同,而是因为错误发现的代价太高。
7.5.4 p 值和 alpha 的分工¶
不要把 p 值和 \(\alpha\) 混成一件事。
| 名称 | 何时确定 | 作用 |
|---|---|---|
| \(\alpha\) | 看数据前 | 设定误报容忍度 |
| p 值 | 看数据后 | 衡量数据在 \(H_0\) 下有多罕见 |
决策规则仍然是:
若小率事先定 \(\alpha=0.05\),p=0.04 就拒绝;若事先定 \(\alpha=0.01\),同样的 p=0.04 就不拒绝。
不要把 0.05 当成科学分界线
0.05 是常用惯例,不是自然定律。严肃报告应说明为什么选择这个阈值,尤其在医疗、安全、政策决策中。
7.5.5 多次检验会放大误报¶
如果一次检验的误报率是 0.05,同时做很多次检验,至少撞上一次误报的概率会变大。
若做 \(m\) 个独立检验,每个检验 \(\alpha=0.05\):
| 检验次数 \(m\) | 至少一次误报概率 |
|---|---|
| 1 | 0.05 |
| 5 | 0.23 |
| 20 | 0.64 |
| 100 | 0.99 |
这就是多重检验校正的动机,后面 §7.10 会专门讲。
7.5.6 Python 计算临界值和误报累积¶
from scipy import stats
for alpha in [0.10, 0.05, 0.01, 0.001]:
z_star = stats.norm.ppf(1 - alpha / 2)
print(f"alpha={alpha:.3f}, 双侧 z 临界值 = ±{z_star:.3f}")
for m in [1, 5, 20, 100]:
fwer = 1 - (1 - 0.05) ** m
print(f"m={m:3d}, 至少一次误报概率 = {fwer:.3f}")
完整脚本见:
小率的笔记本
\(\alpha\) 是在看数据前设定的误报容忍度,也就是 \(P(\text{拒绝 }H_0\mid H_0\text{ 真})\)。\(\alpha\) 越小越难拒绝 \(H_0\),但可能增加漏报。0.05 只是惯例,不是科学定律;多次检验会放大整体误报风险。