13.4 交叉验证¶
小率把活动推荐数据随机分成训练集和验证集。第一次切分,F1 是 0.86;换一个随机种子,变成 0.78;再换一次,又到 0.82。模型没变,分数却像天气一样飘。
一次切分太依赖运气。交叉验证(Cross Validation) 要做的,就是让不同样本轮流当验证集,多测几次,再看平均表现和波动。
如果刚好抽到一批简单验证集,分数不就虚高了吗?
所以让每一份数据都轮流接受检验,把单次切分的运气摊薄。
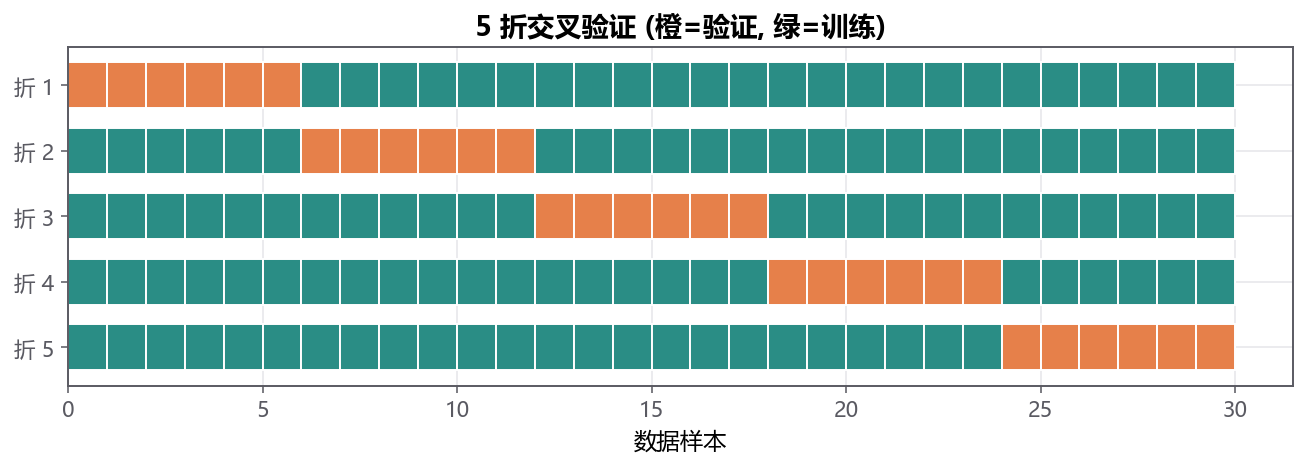
13.4.1 K 折让每份数据都轮到一次¶
K 折交叉验证(K-Fold Cross Validation) 把数据分成 \(K\) 份。每次用 \(K-1\) 份训练,剩下 1 份验证,重复 \(K\) 次。
如果第 \(k\) 折的验证分数是 \(s_k\),平均分是:
\[
\bar s=\frac{1}{K}\sum_{k=1}^{K}s_k
\]
分数波动也要报告:
\[
sd(s)=\sqrt{\frac{1}{K-1}\sum_{k=1}^{K}(s_k-\bar s)^2}
\]
平均分告诉你模型大概多好,标准差告诉你这个估计有多稳。
0.84±0.01 和 0.84±0.10,听起来完全不是一回事。
对。平均值相同,不代表可靠程度相同。
13.4.2 数据不能乱切¶
不同数据有不同切法。切错了,验证分数会看起来很好,却不能代表真实上线表现。
| 场景 | 推荐方式 | 为什么 |
|---|---|---|
| 类别比例不平衡 | StratifiedKFold | 每折保持类别比例接近 |
| 同一同学多条记录 | GroupKFold | 避免同一个人同时进训练和验证 |
| 按时间预测报名 | TimeSeriesSplit | 只能用过去预测未来 |
| 样本很少 | Leave-One-Out | 尽量利用数据,但计算慢 |
数据泄漏比模型差更可怕
如果同一个同学的多条记录被拆到训练集和验证集,模型可能只是认出了这个人,而不是学会了活动推荐规律。验证分数会虚高。
13.4.3 调参也会偷看答案¶
交叉验证常用来选择超参数,比如正则强度、树深度、邻居数。要注意:验证集可以用来选模型,但最后报告性能最好再用独立测试集,或使用 嵌套交叉验证(Nested Cross Validation)。
外层负责评估,内层负责调参:
如果我在同一批验证集上反复试参数,最后挑最高分,是不是也在背验证集?
是的。验证集被用太多次,也会变成训练过程的一部分。
13.4.4 用 sklearn 跑一次交叉验证¶
from sklearn.datasets import make_classification
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.linear_model import LogisticRegression
X, y = make_classification(
n_samples=600,
n_features=8,
weights=[0.75, 0.25],
random_state=2026,
)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=2026)
model = LogisticRegression(max_iter=1000)
scores = cross_val_score(model, X, y, cv=cv, scoring="f1")
print("每折 F1:", scores.round(3).tolist())
print(f"平均 F1 = {scores.mean():.3f}, 标准差 = {scores.std(ddof=1):.3f}")
报告时怎么写
“5 折分层交叉验证 F1 = 0.81 ± 0.04” 比 “F1 = 0.81” 更完整,因为它同时交代了切分方式、平均表现和不稳定程度。
小率的笔记本
交叉验证让样本轮流当验证集,用多次评估降低单次切分的运气影响。切分方式必须尊重数据结构:类别要分层,同一对象要分组,时间数据要按过去到未来。