2.7 极差与四分位距¶
小率已经知道标准差能描述“散不散”。但他又遇到一个新问题。
咖啡店老板拿来一串外卖送达时间:
大多数订单都在 20 到 40 分钟之间送达,最后却有一个 78 分钟。小率皱起眉头。
均哥点点头。

本节要讲三个工具:极差(Range)、四分位距(Interquartile Range, IQR)和箱线图(Box Plot)。
它们和标准差一样,都在描述“散不散”,但视角不同。标准差会让每个点都参与计算;极差只看最远的两端;IQR 只看中间一半。理解这些差异,比记住公式更重要。
2.7.1 极差:最快扫一眼范围¶
极差(Range) 是最大值和最小值的差:
在外卖例子里:
这说明最慢和最快之间差了 60 分钟。
极差的优点是直观:一眼知道跨度有多大。
但它也很脆弱:它只看两个点。
如果 78 分钟是因为暴雨、骑手摔车、商家漏单或顾客地址填错,它可能是值得单独调查的特殊情况。此时极差会把整组数据描述得“非常夸张”。
极差常适合做第一眼检查。例如一份年龄数据极差是 98 岁,说明样本横跨婴儿到老人;一份考试成绩极差是 5 分,说明大家分数非常接近;一批产品重量极差突然变大,可能提示生产过程有异常。
但极差的问题也正来自它太快:它完全不关心中间 98% 的数据。如果只有一个录入错误,极差就会被拉得很夸张。
2.7.2 四分位数:把排好队的数据切成四段¶
要看“中间大多数”的范围,我们先把数据从小到大排好。
四分位数会把这支队伍切成四段:
- \(Q_1\):第 25% 位置,四分之一数据在它以下。
- \(Q_2\):第 50% 位置,也就是中位数。
- \(Q_3\):第 75% 位置,四分之三数据在它以下。
在很多统计软件里,四分位数的具体计算方式可能略有差别,但核心直觉不变:
\(Q_1\) 到 \(Q_3\) 之间,是中间一半数据的活动范围。
四分位距(Interquartile Range, IQR) 定义为:
它只看中间 50% 的数据,因此比极差更不怕极端值。
你可以把 IQR 想成“普通订单的主要活动区间”。在外卖例子里,如果 \(Q_1=24\) 分钟、\(Q_3=34\) 分钟,那么中间一半订单大约集中在 24 到 34 分钟之间。这个信息比“最慢 78 分钟”更能描述大多数顾客的体验。
2.7.3 箱线图:把五个关键信息放在一张图里¶
箱线图(Box Plot)是描述分布的压缩图。它把中位数、四分位数、IQR 和可能的异常点放在一起。
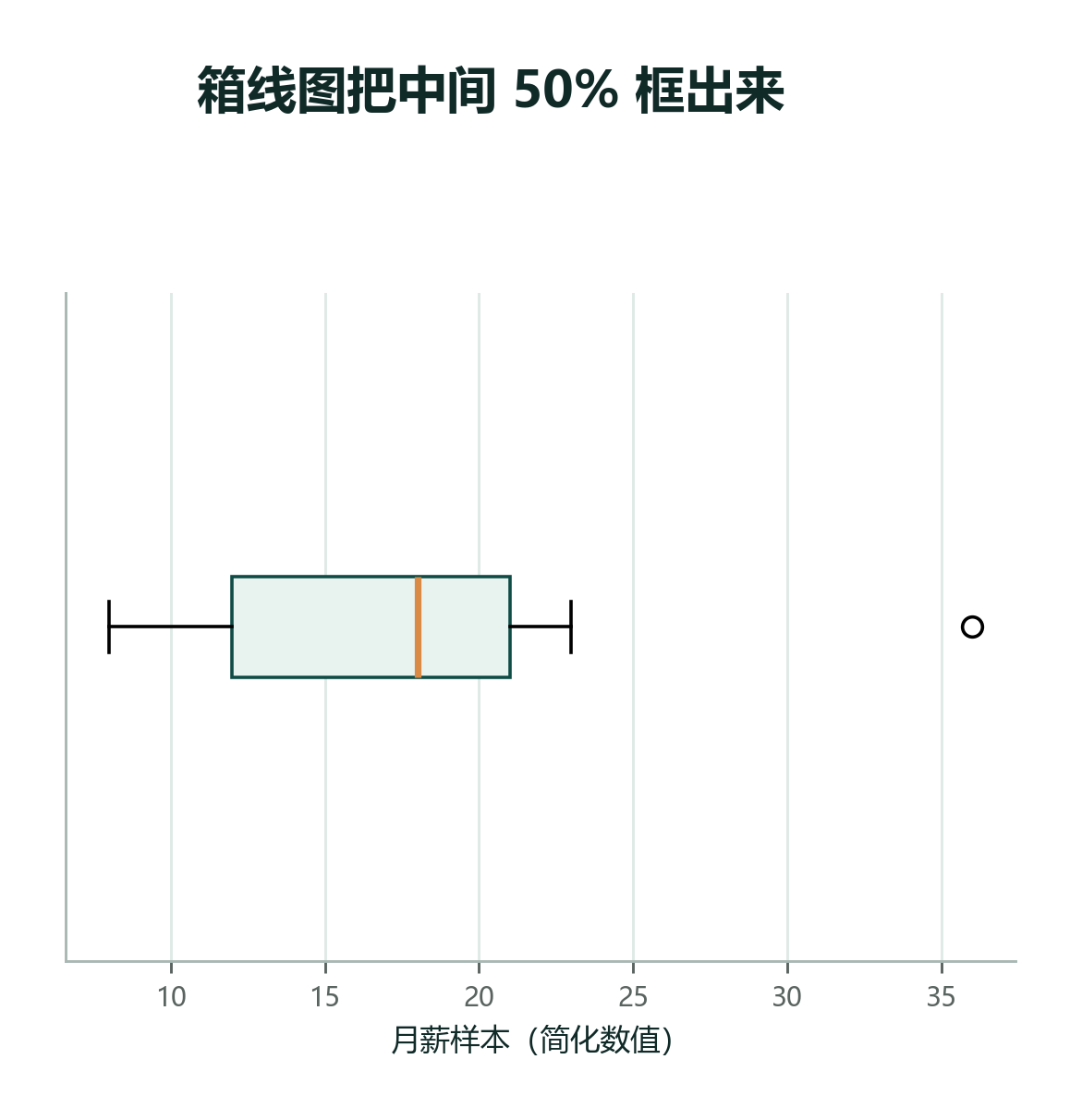
读箱线图时,先看这几件事:
| 元素 | 含义 | 读图时问什么 |
|---|---|---|
| 箱体中线 | 中位数 \(Q_2\) | 典型水平在哪里 |
| 箱体两边 | \(Q_1\) 和 \(Q_3\) | 中间一半数据在哪 |
| 箱体长度 | IQR | 中间一半散得多开 |
| 须 | 非异常范围内的较小/较大值 | 普通范围大概到哪里 |
| 单独的点 | 可能异常值 | 值得检查来源吗 |
箱线图不是为了让图看起来高级,而是为了快速回答:中心在哪里?中间一半有多宽?有没有可疑的远点?
读箱线图时可以按“中间、箱子、尾巴、远点”四步走:
- 看中位数线:典型水平在哪里。
- 看箱体长度:中间一半数据是否集中。
- 看上下两根须:普通范围是否对称。
- 看单独点:有没有需要追问的异常值。
这样读,箱线图就不再是一堆线条,而是一份压缩后的分布报告。
2.7.4 异常值规则不是定罪书¶
箱线图常用一个经验规则标记异常值:
的点,会被标出来。
但注意:被标出来不等于一定错误。
它只是提醒你:“这个点离其他数据比较远,最好检查一下。”
可能原因包括:
- 记录错误:时间录成了 78,其实是 28。
- 特殊事件:暴雨、交通事故、设备故障。
- 真实但罕见:确实有一个订单等了很久。
- 群体混合:某些远距离订单和普通订单混在一起。
异常值不是坏人
异常值可能是错误,也可能是最有价值的信息。不要机械删除。先查来源,再决定保留、修正、分组还是单独说明。
一个好的异常值处理流程通常是:
- 先确认记录:是不是单位错了、录入错了、小数点错了。
- 再查背景:是不是暴雨、活动、促销、故障等特殊事件。
- 再决定分析方式:保留、修正、删除、分组,或在报告中单独说明。
最危险的做法是为了让图“更好看”就偷偷删掉异常点。统计报告里,异常值处理必须可解释、可复查。
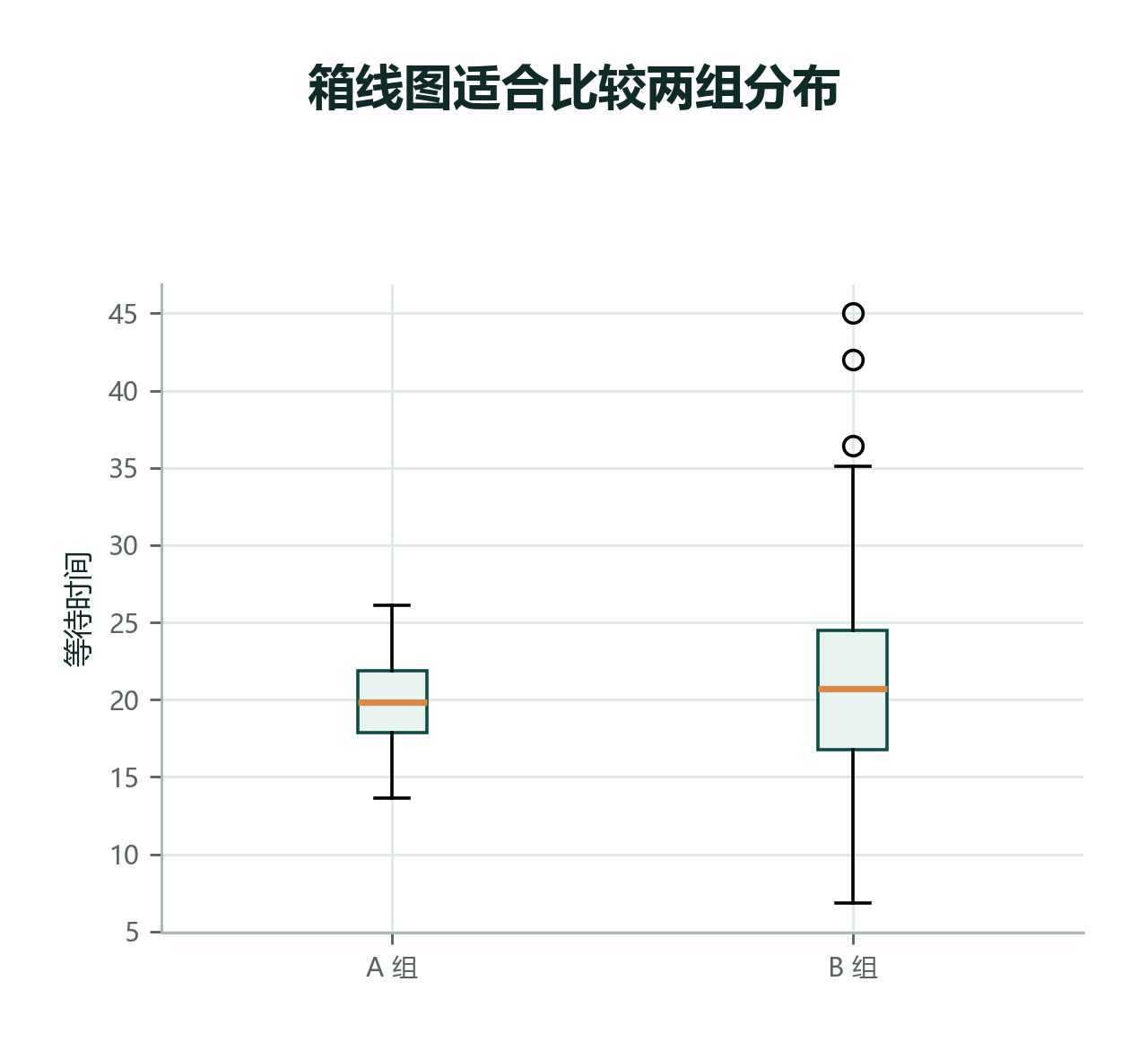
2.7.5 比较多组数据时,IQR 很有用¶
如果两家门店的中位送达时间都差不多,我们还想知道哪家更稳定。
这时箱线图很方便。
极差、标准差和 IQR 都能描述离散程度,但它们关注点不同:
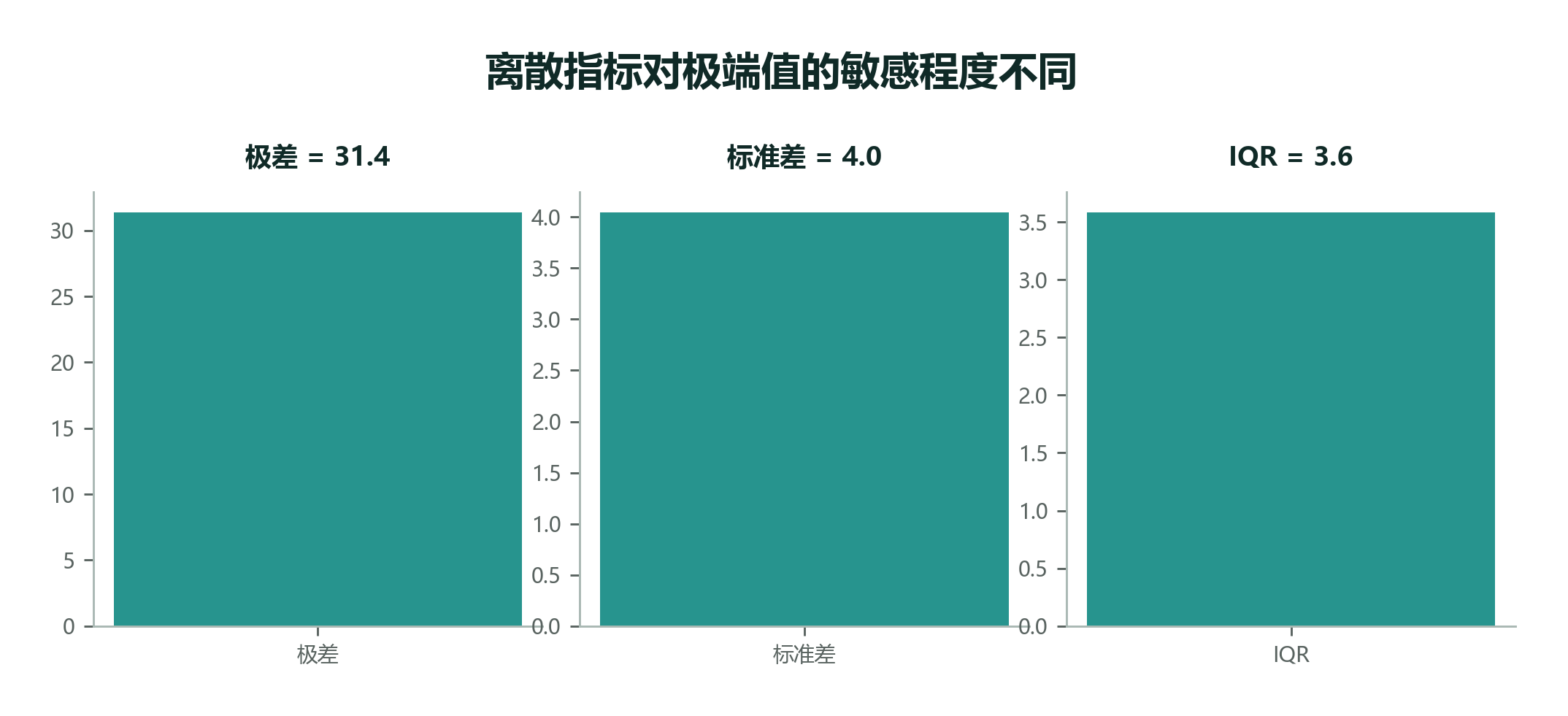
| 指标 | 看什么 | 对极端值敏感吗 |
|---|---|---|
| 极差 | 最大值和最小值 | 非常敏感 |
| 标准差 | 每个值离均值多远 | 敏感 |
| IQR | 中间 50% 的范围 | 不太敏感 |
在比较多组数据时,IQR 常常比极差更公平。比如两家门店各有一单特别迟到,极差都会很大;但如果其中一家大多数订单都很稳定,另一家中间一半订单也很分散,箱线图会把这个差异显示出来。
2.7.6 用 Python 计算 IQR¶
import numpy as np
data = np.array([18, 20, 21, 22, 24, 25, 25, 26, 27, 28,
29, 30, 31, 32, 33, 34, 36, 37, 41, 78])
q1, q2, q3 = np.percentile(data, [25, 50, 75])
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
print(f"Q1 = {q1:.1f}")
print(f"中位数 Q2 = {q2:.1f}")
print(f"Q3 = {q3:.1f}")
print(f"IQR = {iqr:.1f}")
print(f"异常值检查范围:{lower:.1f} 到 {upper:.1f}")
print(data[(data < lower) | (data > upper)])
完整配套脚本
本节配套脚本在 docs/assets/scripts/ch02_descriptive/07_range_and_iqr.py,可以复现四分位数、IQR 和箱线图。
小率的笔记本
- 极差等于最大值减最小值,直观但非常怕极端值。
- 四分位数把排序后的数据切成四段,IQR 是 \(Q_3-Q_1\)。
- IQR 描述中间 50% 数据的范围,比极差更稳健。
- 箱线图适合快速比较多组数据的中心、离散和异常点。
- 异常值规则是提醒,不是定罪;先查来源,再做处理。
- 对称数据常配均值和标准差;偏态或有异常值时,常配中位数和 IQR。