2.4 均值¶
小率在新闻里看到“城市平均月薪破万”,可妈妈办公室里没人拿到这个数。他把这条新闻拿给均哥看。均哥的第一反应不是算公式,而是问:平均值真的能代表大多数人吗?
均哥说,均值不是一个单独的按钮,而是一组选择。不同问题要选不同的“平均”。

2.4.1 平均值真的能代表大多数人吗¶
晚上吃饭,小率刷着手机。
均哥在记事本上写:
| 员工 | 月薪(元) |
|---|---|
| 9 位同事 | 6 000 |
| 1 位老板 | 1 000 000 |
这也是学习均值时最重要的一句话:均值不是“把数据讲完”的万能答案,而是“用一个中心位置概括数据”的一种方式。它特别擅长回答总量分摊问题,比如一家公司总薪酬平均分到每位员工、一个部门总奖金平均分到每个人。
但如果你想知道“普通人通常拿多少工资”,均值就不一定是最合适的代表。它用了所有人的工资,也就会被少数特别高的工资影响。
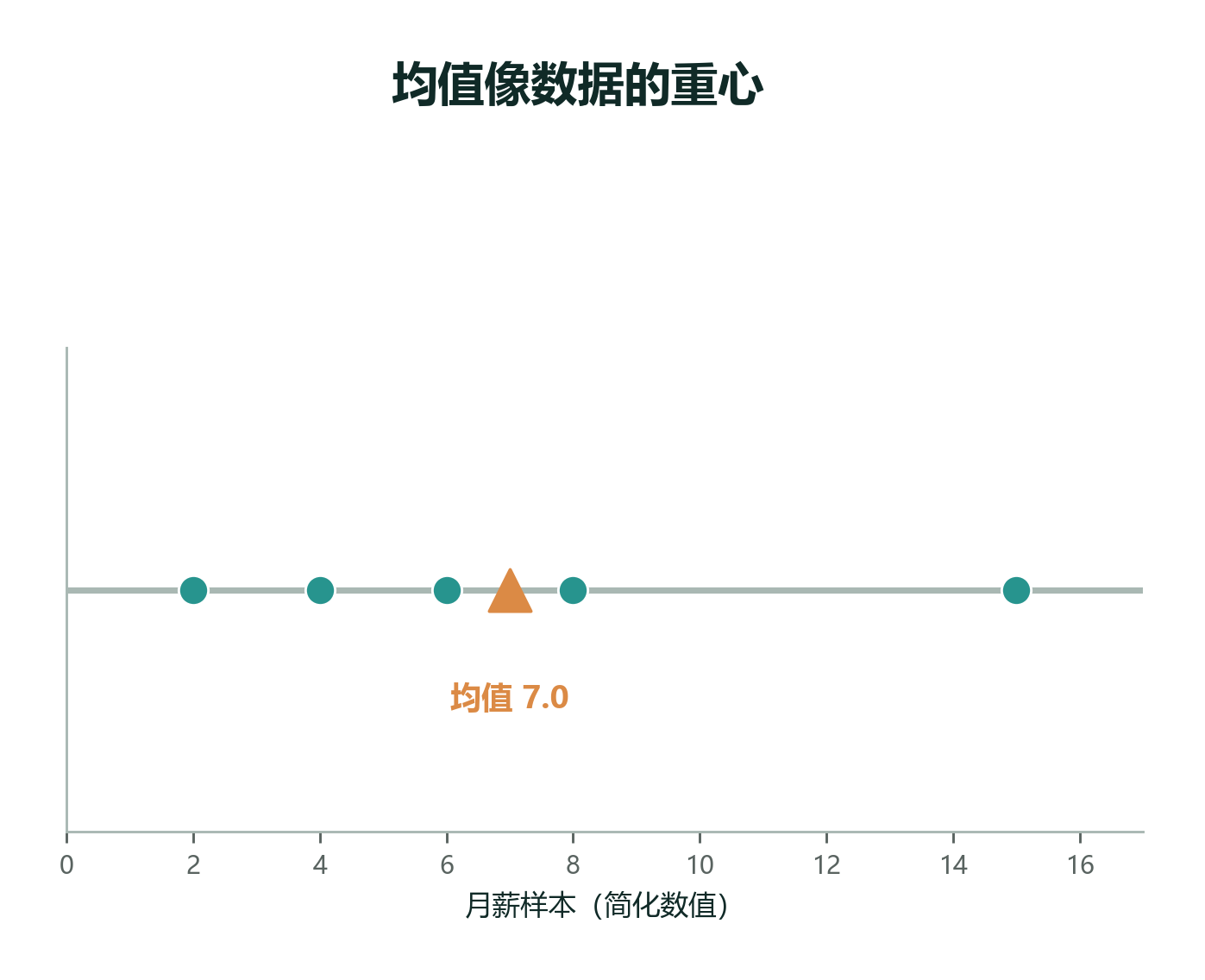
2.4.2 把均值想成「数据的重心」¶
均哥不急着写公式,先在便签上画了一根数轴,把每个数据点想象成**重量相同**的小球,挂在数轴上。问:把一根杠杆放在这条数轴下面,**唯一**能让杠杆平衡的支点在哪?
那个位置,就是算术平均值。
下面的交互图把这个直觉做成了可拖拽的实物:你可以把任意一个小球拉到任何位置, 橙色支点 会自动跟着移动。
2.4.3 算术平均值¶
均哥的写作习惯是先写中文版,再换字母:
记数据是 \(x_1, x_2, \dots, x_n\),"加起来"用大写希腊字母 \(\Sigma\)(读作 sigma)表示,得到 样本均值(sample mean) :
如果数据来自整个总体,我们用希腊字母 \(\mu\)(读作 mu)表示 总体均值(population mean) :
即 \(\bar{x}\) 对应 \(\mu\),\(s\) 对应 \(\sigma\)。这套命名是后续抽样、估计、检验的基石——必须分清"手上这一组数据的平均"和"想推断的整体平均"。
为了让公式不只是公式,我们继续用月薪小例子手算一遍。小率从新闻附带的样本说明里摘出 5 位应届生的月薪:
| 受访者 | 月薪(元) |
|---|---|
| A | 5 000 |
| B | 6 000 |
| C | 6 500 |
| D | 7 500 |
| E | 25 000 |
先把所有月薪加起来:
再除以 5 位受访者:
所以这 5 位受访者的平均月薪是 10 000 元。这个 10 000 元不是说每个人都拿到 10 000 元,而是说如果把 50 000 元总月薪平均分摊给 5 个人,每人就是 10 000 元。
性质一 :所有数据到均值的偏差之和为零
性质二 :所有数据到均值的**平方偏差和最小**——任何其他位置都会让"距离平方和"变大
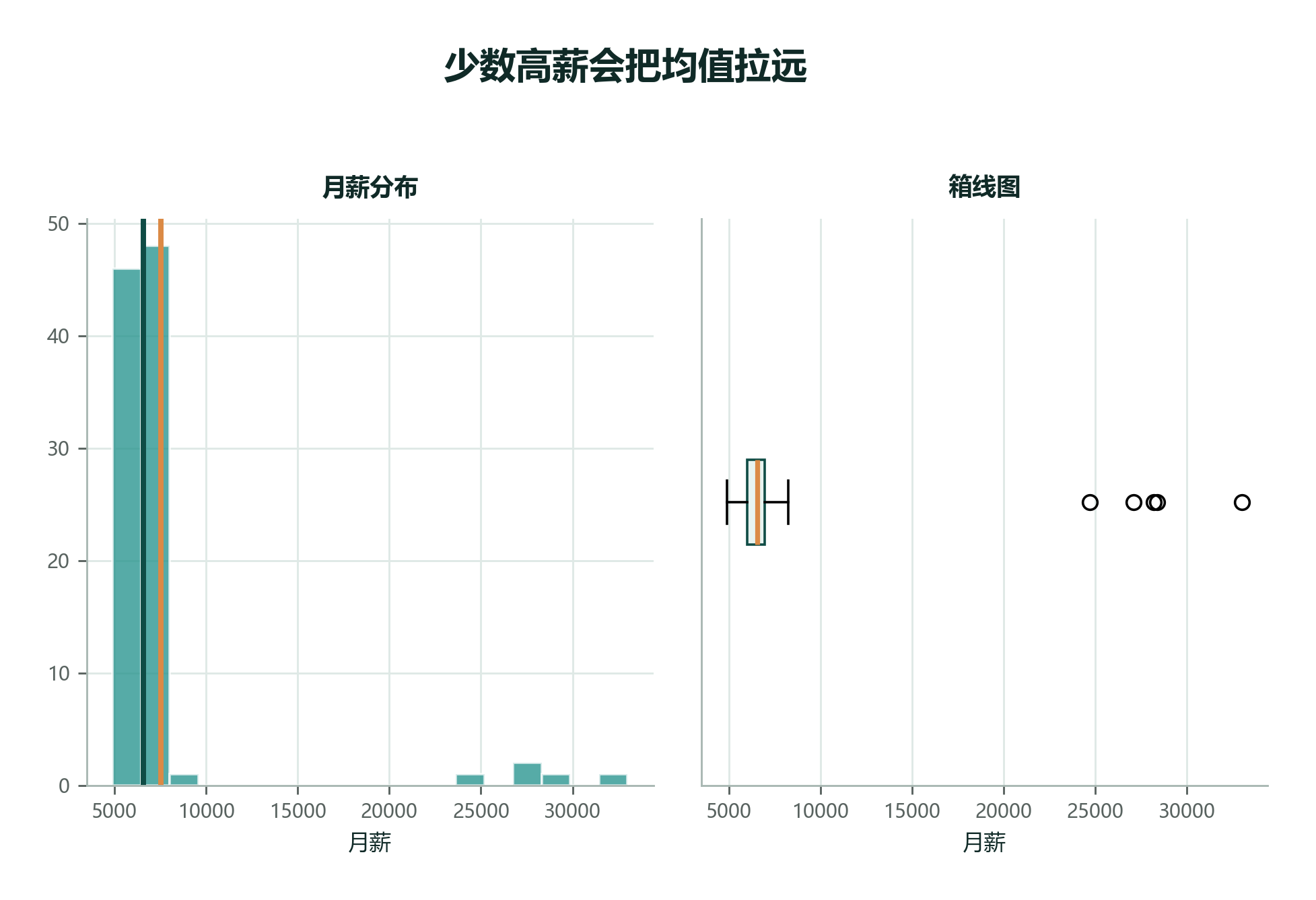
2.4.4 极端值与稳健性¶
直观结论:
| 数据形态 | 均值是否可靠 | 推荐使用 |
|---|---|---|
| 对称、无离群点 (同岗位基础工资) | ✅ | 算术平均 |
| 右偏 + 长尾 (工资、房价、点击数) | ❌ | 中位数 / 截尾均值 |
| 乘法叠加 (投资收益、增长率) | ❌ | 几何平均(见 §2.4.5) |
| 等量除以速率 (平均速度、调和率) | ❌ | 调和平均(见 §2.4.6) |
2.4.5 加权平均值¶
把每个数据 \(x_i\) 配一个 权重 (weight)\(w_i\):
把字母翻成中文:
当所有权重相等时,加权平均就退化成算术平均。
| 课程 | 学分 \(w_i\) | 绩点 \(x_i\) |
|---|---|---|
| 高等数学 | 5 | 3.7 |
| 大学英语 | 3 | 4.0 |
| 体育 | 1 | 3.0 |
| 普通生物学 | 4 | 3.5 |
简单平均会得到 3.55, 低估 了高数和生物两门重课的贡献。
所以权重出处必须写进报告——否则你的数据看起来精确,其实只是把一个偏见包装成了百分制分数。
加权平均最容易被滥用的地方,正是“权重看起来很客观”。比如把求职岗位做综合评分:薪资 40%、通勤 20%、成长空间 25%、稳定性 15%。这个总分当然能算,但权重本身已经表达了评价者的偏好。对急需收入的人来说,薪资权重可能更高;对正在积累经验的人来说,成长空间权重可能更高。
权重不是装饰
只要用了加权平均,就要说明权重从哪里来。权重可以来自学分、样本占比、业务重要性或专家判断,但不能偷偷藏在公式里。
2.4.6 几何平均值¶
为什么会差?因为收益率不是相加,而是相乘:
要找一个"等价的恒定年化收益率" \(G\),应满足
这正是 几何平均(geometric mean) :
代入:\(G = \sqrt[3]{1.254} \approx 1.0784\),对应年化收益 \(\approx 7.84\%\),复利三年正好回到 125.4 元。
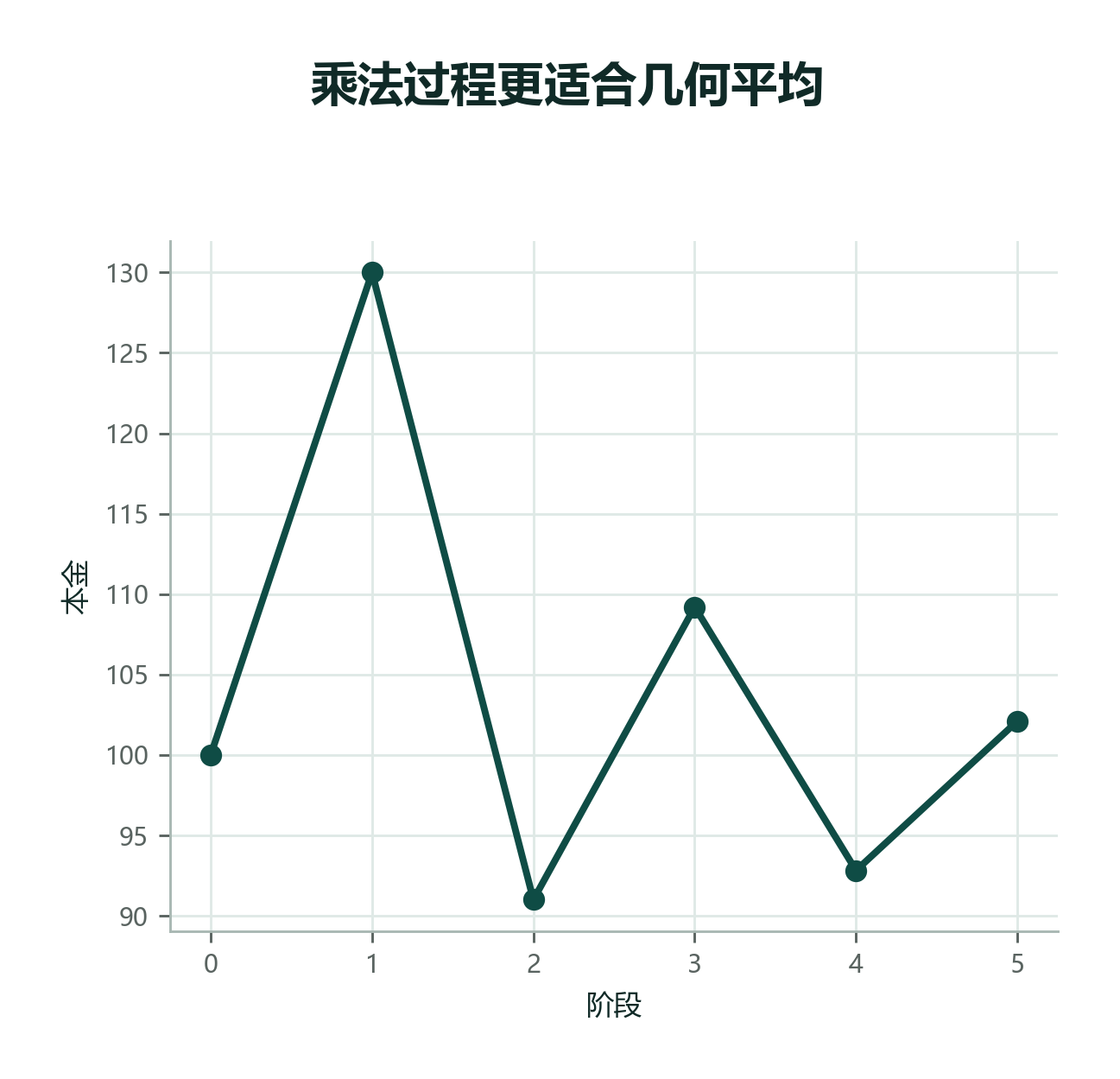
AM-GM 不等式:几何平均永远 ≤ 算术平均¶
对任何一组 正数 ,恒有
所以任何带波动的乘法过程,几何平均一定低于算术平均。这也是金融业"年化收益率"必须用几何平均的原因。
- 投资收益、复利、人口增长率、通胀率
- 比率的"平均":市盈率、生物学倍数变化(fold change)
- 任何 乘法叠加 的指标
2.4.7 调和平均值¶
设上下坡各 15 km:
- 上坡用时 \(15 / 10 = 1.5\) 小时
- 下坡用时 \(15 / 30 = 0.5\) 小时
- 总路程 \(30\) km,总时间 \(2\) 小时
- 平均速度 \(= 30 / 2 = 15\) km/h
正确答案是 15 ,不是 20。
调和平均(harmonic mean) :
中文版:
代入小率的例子:\(H = \dfrac{2}{\frac{1}{10} + \frac{1}{30}} = \dfrac{2}{4/30} = 15\)。
三大平均的不等式链¶
对任意正数集合:
差距大小直接告诉你数据"散得有多狠"——三者越接近,数据越均匀。
| 场景 | 为什么用调和平均 |
|---|---|
| 等距离不同速度的平均速度 | 时间是路程除以速度,要对 速率求平均 |
| 几台机器并行处理同一批任务 | 总产能取决于"单位时间产出"的倒数关系 |
| F1 分数(精确率与召回率的调和平均) | 任何一个低,整体都低;惩罚短板 |
| 平均市盈率 | 每元盈利对应的价格,倒数关系 |
2.4.8 截尾均值¶
把数据排序后,对称地**砍掉两端各 \(p\%\) 的数据,再对剩下的部分求算术平均,就得到了 \(p\%\) **截尾均值(trimmed mean)。常见的 \(p\) 是 5%、10%、25%。
回到工资数据:100 人里去掉收入最高的 5 人和最低的 5 人,剩下的 90 人均值大约是 7.0 千元,远比未截尾的 10.6 千元贴近"普通员工"的真实水平。
2.4.9 用 numpy/scipy 算五种均值¶
import numpy as np
from scipy import stats
x = np.array([6, 6, 6, 6, 6, 6, 6, 6, 6, 1000]) # 9 个员工 + 1 个老板, 单位: 千元
# 算术平均
print("算术平均:", x.mean()) # 105.4
# 中位数(虽然不是均值,但常一起报告)
print("中位数 :", np.median(x)) # 6.0
# 加权平均(假设最后一位老板权重 0.1, 其余各 1)
w = np.r_[np.ones(9), 0.1]
print("加权平均:", np.average(x, weights=w)) # ≈ 16.7
# 几何平均(数据需为正)
print("几何平均:", stats.gmean(x)) # ≈ 11.84
# 调和平均
print("调和平均:", stats.hmean(x)) # ≈ 6.66
# 10% 截尾均值
print("截尾均值:", stats.trim_mean(x, 0.1)) # 6.0
np.mean / np.median 看主体,再换 gmean / hmean / trim_mean 验真。
真实分析工作里常会先把均值、中位数和稳健均值放在一起看,目的就是揪出被极端值、乘法过程或速率结构骗住的均值。
完整版脚本(含本节三张图的复现):docs/assets/scripts/ch02_descriptive/04_mean.py
你知道吗
1934 年,经济学家 Simon Kuznets 受美国国会委托做出第一份国民收入估算——这是"人均 GDP"作为政策指标的起点。Kuznets 后来因此拿了 1971 年的诺贝尔经济学奖,但他自己一直警告:
"一个国家的福利几乎不可能从一个国民收入指标推断出来。"
他指的就是 均值掩盖分布 的问题。九十多年过去了,新闻头条还在用"人均 GDP / 平均工资"刷屏,而读者依然会被搞糊涂。所以"看到平均,先问分布"这条规矩,从一开始就刻在统计学的基因里。
小率的笔记本
- 算术平均是数据的重心,简单、可加,有“偏差和为零”和“最小平方距离”两条好性质,但对极端值高度敏感。
- 加权平均把不同重要性的数据加权求和,权重往往来自业务判断,必须公开。
- 几何平均适用于乘法叠加过程,例如投资收益和增长率,且不大于算术平均。
- 调和平均适用于速率或倒数结构,例如平均速度、效率和 F1。
- 截尾均值通过砍掉两端极端值,保留分布主体趋势。
- 数据近似对称时用算术平均;偏态或有离群点时优先考虑中位数或截尾均值;增长过程看几何平均;速率过程看调和平均。